













數據結構與算法,弄懂圖的兩種遍歷方式
1 引言
遍歷是指從某個節點出發,按照一定的的搜索路線,依次訪問對數據結構中的全部節點,且每個節點僅訪問一次。
在二叉樹基礎中,介紹了對于樹的遍歷。樹的遍歷是指從根節點出發,按照一定的訪問規則,依次訪問樹的每個節點信息。樹的遍歷過程,根據訪問規則的不同主要分為四種遍歷方式:
(1)先序遍歷
(2)中序遍歷
(3)后序遍歷
(4)層次遍歷
類似的,圖的遍歷是指,從給定圖中任意指定的頂點(稱為初始點)出發,按照某種搜索方法沿著圖的邊訪問圖中的所有頂點,使每個頂點僅被訪問一次,這個過程稱為圖的遍歷。遍歷過程中得到的頂點序列稱為圖遍歷序列。
圖的遍歷過程中,根據搜索方法的不同,又可以劃分為兩種搜索策略: (1)深度優先搜索(DFS,Depth First Search) (2)廣度優先搜索(BFS,Breadth First Search)
2 深度優先搜索
2.1 算法思想
深度優先搜索思想:假設初始狀態是圖中所有頂點均未被訪問,則從某個頂點v出發,首先訪問該頂點,然后依次從它的各個未被訪問的鄰接點出發深度優先搜索遍歷圖,直至圖中所有和v有路徑相通的頂點都被訪問到。若此時尚有其他頂點未被訪問到,則另選一個未被訪問的頂點作起始點,重復上述過程,直至圖中所有頂點都被訪問到為止。
2.2 算法特點
深度優先搜索是一個遞歸的過程。首先,選定一個出發點后進行遍歷,如果有鄰接的未被訪問過的節點則繼續前進。若不能繼續前進,則回退一步再前進,若回退一步仍然不能前進,則連續回退至可以前進的位置為止。重復此過程,直到所有與選定點相通的所有頂點都被遍歷。 深度優先搜索是遞歸過程,帶有回退操作,因此需要使用棧存儲訪問的路徑信息。當訪問到的當前頂點沒有可以前進的鄰接頂點時,需要進行出棧操作,將當前位置回退至出棧元素位置。
2.3 圖解過程
2.3.1 無向圖深度優先搜索
以圖2.3.1.1中所示無向圖說明深度優先搜索遍歷過程。
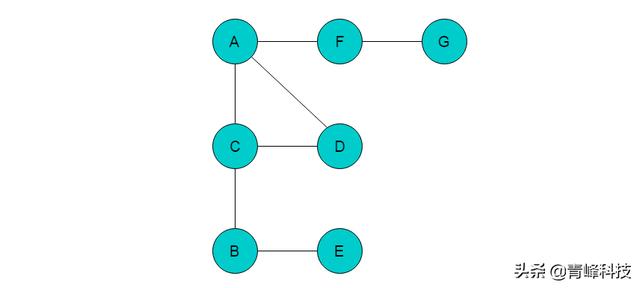
圖2.3.1.1
(1)首先選取頂點A為起始點,輸出A頂點信息,且將A入棧,并標記A為已訪問頂點。
(2)A的鄰接頂點有C、D、F,從中任意選取一個頂點前進。這里我們選取C頂點為前進位置頂點。輸出C頂點信息,將C入棧,并標記C為已訪問頂點。當前位置指向頂點C。
(3)頂點C的鄰接頂點有A、D和B,此時A已經標記為已訪問頂點,因此不能繼續訪問。從B或者D中選取一個頂點前進,這里我們選取B頂點為前進位置頂點。輸出B頂點信息,將B入棧,標記B頂點為已訪問頂點。當前位置指向頂點B。
(4)頂點B的鄰接頂點只有C、E,C已被標記,不能繼續訪問,因此選取E為前進位置頂點,輸出E頂點信息,將E入棧,標記E頂點,當前位置指向E。
(5)頂點E的鄰接頂點均已被標記,此時無法繼續前進,則需要進行回退。將當前位置回退至頂點B,回退的同時將E出棧。
(6)頂點B的鄰接頂點也均被標記,需要繼續回退,當前位置回退至C,回退同時將B出棧。
(7)頂點C可以前進的頂點位置為D,則輸出D頂點信息,將D入棧,并標記D頂點。當前位置指向頂點D。
(8)頂點D沒有前進的頂點位置,因此需要回退操作。將當前位置回退至頂點C,回退同時將D出棧。
(9)頂點C沒有前進的頂點位置,繼續回退,將當前位置回退至頂點A,回退同時將C出棧。
(10)頂點A前進的頂點位置為F,輸出F頂點信息,將F入棧,并標記F。將當前位置指向頂點F。
(11)頂點F的前進頂點位置為G,輸出G頂點信息,將G入棧,并標記G。將當前位置指向頂點G。
(12)頂點G沒有前進頂點位置,回退至F。當前位置指向F,回退同時將G出棧。
(13)頂點F沒有前進頂點位置,回退至A,當前位置指向A,回退同時將F出棧。
(14)頂點A沒有前進頂點位置,繼續回退,棧為空,則以A為起始的遍歷結束。若圖中仍有未被訪問的頂點,則選取未訪問的頂點為起始點,繼續執行此過程。直至所有頂點均被訪問。
(15)采用深度優先搜索遍歷順序為A->C->B->E->D->F->G。
2.3.2 有向圖深度優先搜索
以圖2.3.2.1中所示有向圖說明深度優先搜索遍歷過程。
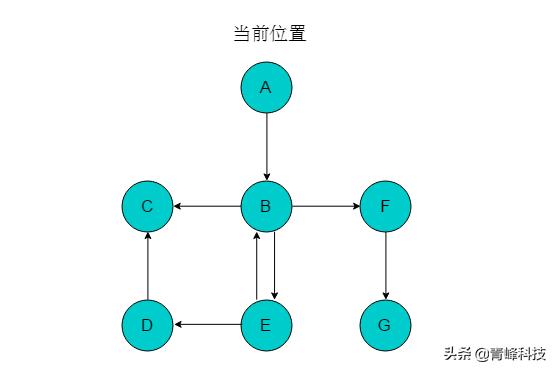
圖2.3.2.1 有向圖
(1)以頂點A為起始點,輸出A,將A入棧,并標記A。當前位置指向A。
(2)以A為尾的邊只有1條,且邊的頭為頂點B,則前進位置為頂點B,輸出B,將B入棧,標記B。當前位置指向B。
(3)頂點B可以前進的位置有C與F,選取F為前進位置,輸出F,將F入棧,并標記F。當前位置指向F。
(4)頂點F的前進位置為G,輸出G,將G入棧,并標記G。當前位置指向G。
(5)頂點G沒有可以前進的位置,則回退至F,將F出棧。當前位置指向F。
(6)頂點F沒有可以前進的位置,繼續回退至B,將F出棧。當前位置指向B。
(7)頂點B可以前進位置為C和E,選取E,輸出E,將E入棧,并標記E。當前位置指向E。
(8)頂點E的前進位置為D,輸出D,將D入棧,并標記D。當前位置指向D。
(9)頂點D的前進位置為C,輸出C,將C入棧,并標記C。當前位置指向C。
(10)頂點C沒有前進位置,進行回退至D,回退同時將C出棧。
(11)繼續執行此過程,直至棧為空,以A為起始點的遍歷過程結束。若圖中仍有未被訪問的頂點,則選取未訪問的頂點為起始點,繼續執行此過程。直至所有頂點均被訪問。
2.4 算法分析
當圖采用鄰接矩陣存儲時,由于矩陣元素個數為n^2,因此時間復雜度就是O(n^2)。 當圖采用鄰接表存儲時,鄰接表中只是存儲了邊結點(e條邊,無向圖也只是2e個結點),加上表頭結點為n(也就是頂點個數),因此時間復雜度為O(n+e)。
3 廣度優先搜索
3.1 算法思想
廣度優先搜索思想:從圖中某頂點v出發,在訪問了v之后依次訪問v的各個未曾訪問過的鄰接點,然后分別從這些鄰接點出發依次訪問它們的鄰接點,并使得“先被訪問的頂點的鄰接點先于后被訪問的頂點的鄰接點被訪問,直至圖中所有已被訪問的頂點的鄰接點都被訪問到。如果此時圖中尚有頂點未被訪問,則需要另選一個未曾被訪問過的頂點作為新的起始點,重復上述過程,直至圖中所有頂點都被訪問到為止。
3.2 算法特點
廣度優先搜索類似于樹的層次遍歷,是按照一種由近及遠的方式訪問圖的頂點。在進行廣度優先搜索時需要使用隊列存儲頂點信息。
3.3 圖解過程
3.3.1 無向圖的廣度優先搜索
例如:圖3.3.1.1所示的無向圖,采用廣度優先搜索過程。
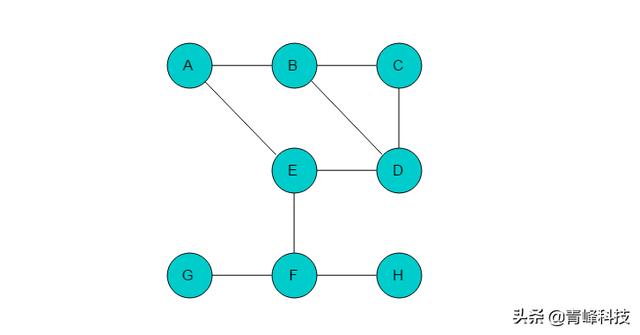
圖3.3.1.1
(1)選取A為起始點,輸出A,A入隊列,標記A,當前位置指向A。
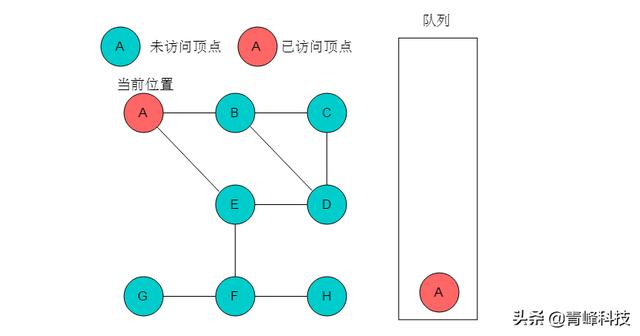
(2)隊列頭為A,A出隊列。A的鄰接頂點有B、E,輸出B和E,將B和E入隊,并標記B、E。當前位置指向A。
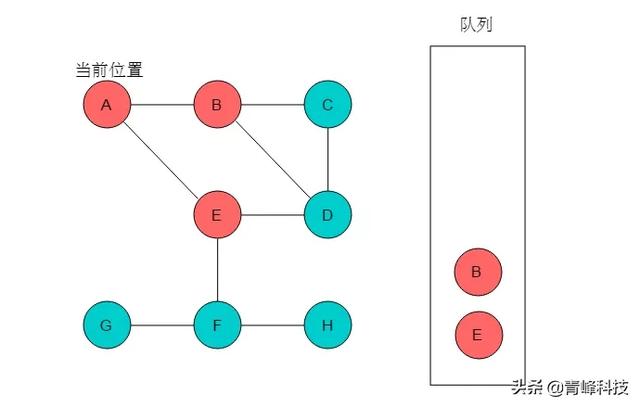
(3)隊列頭為B,B出隊列。B的鄰接頂點有C、D,輸出C、D,將C、D入隊列,并標記C、D。當前位置指向B。
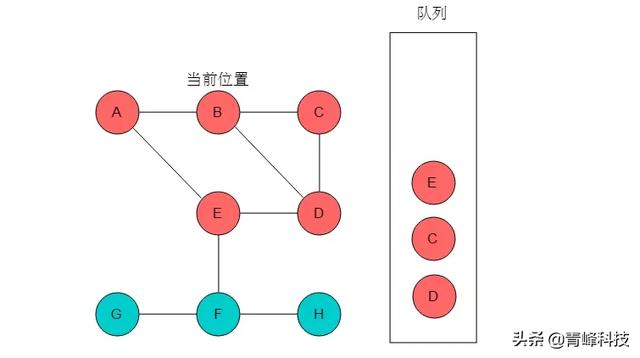
(4)隊列頭為E,E出隊列。E的鄰接頂點有D、F,但是D已經被標記,因此輸出F,將F入隊列,并標記F。當前位置指向E。
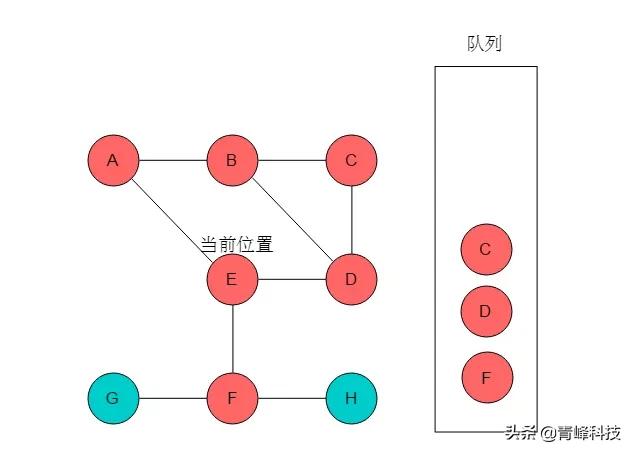
(5)隊列頭為C,C出隊列。C的鄰接頂點有B、D,但B、D均被標記。無元素入隊列。當前位置指向C。
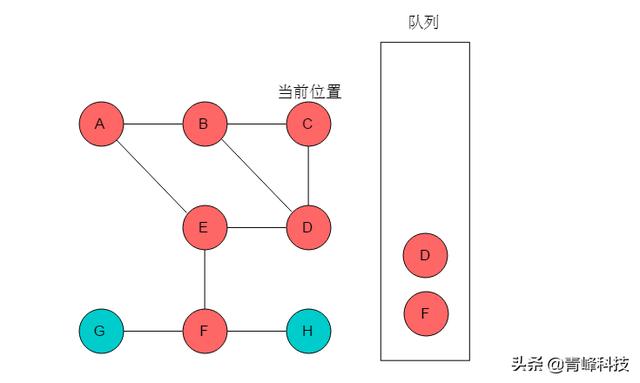
(6)隊列頭為D,D出隊列。D的鄰接頂點有B、C、E,但是B、C、E均被標記,無元素入隊列。當前位置指向D。
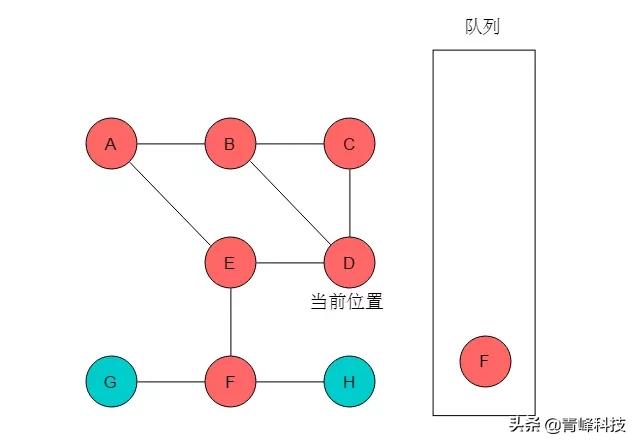
(7)隊列頭為F,F出隊列。F的鄰接頂點有G、H,輸出G、H,將G、H入隊列,并標記G、H。當前位置指向F。
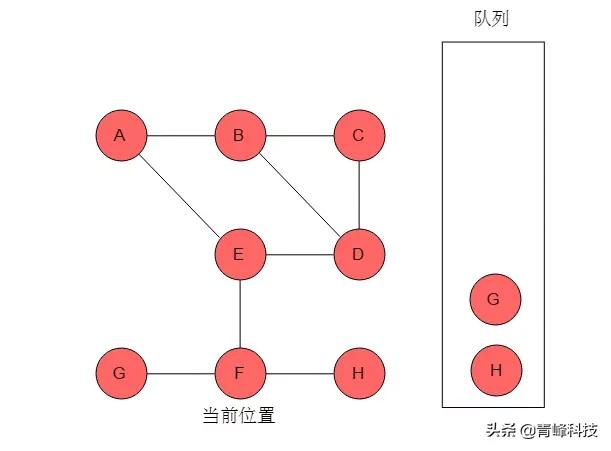
(8)隊列頭為G,G出隊列。G的鄰接頂點有F,但F已被標記,無元素入隊列。當前位置指向G。
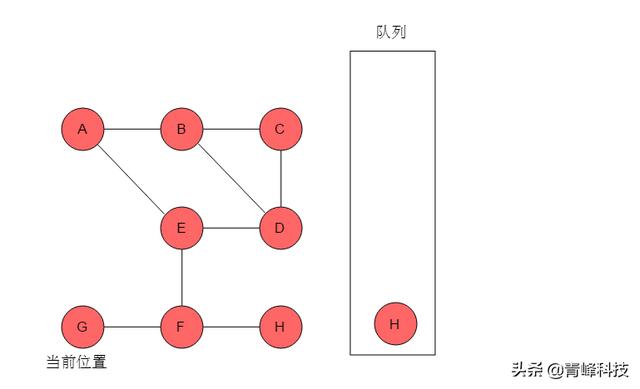
(9)隊列頭為H,H出隊列。H的鄰接頂點有F,但F已被標記,無元素入隊列。當前位置指向H。
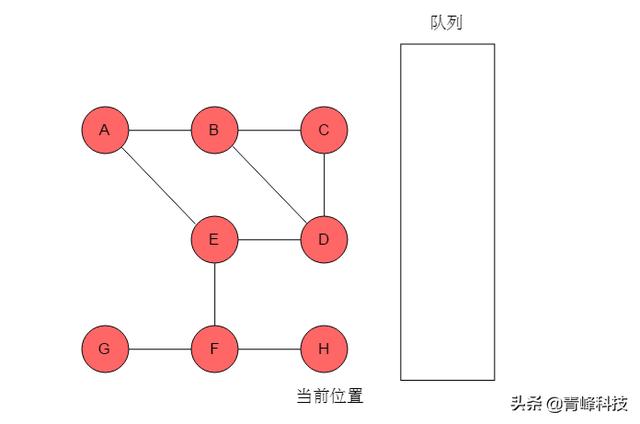
(10)隊列空,則以A為起始點的遍歷結束。若圖中仍有未被訪問的頂點,則選取未訪問的頂點為起始點,繼續執行此過程。直至所有頂點均被訪問。
3.3.2 有向圖的廣度優先搜索
以圖3.3.2.1所示的有向圖為例進行廣度優先搜索。
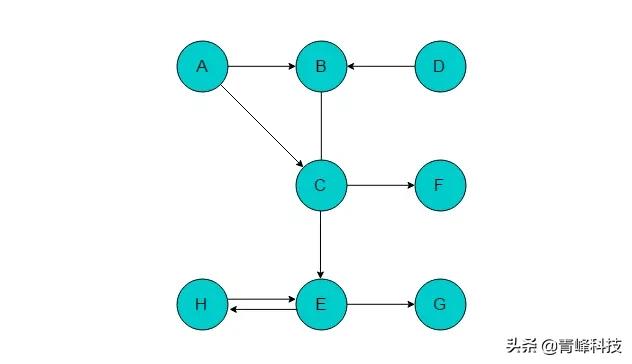
.3.2.1
(1)選取A為起始點,輸出A,將A入隊列,標記A。
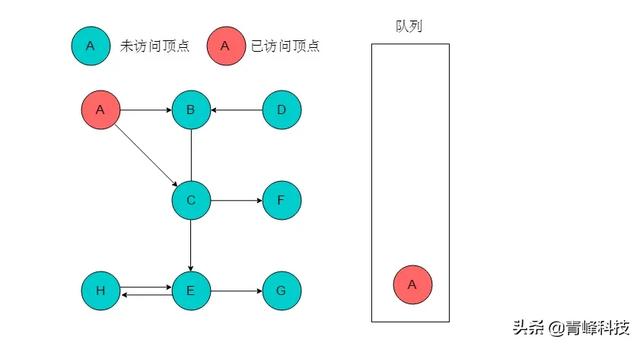
(2)隊列頭為A,A出隊列。以A為尾的邊有兩條,對應的頭分別為B、C,則A的鄰接頂點有B、C。輸出B、C,將B、C入隊列,并標記B、C。
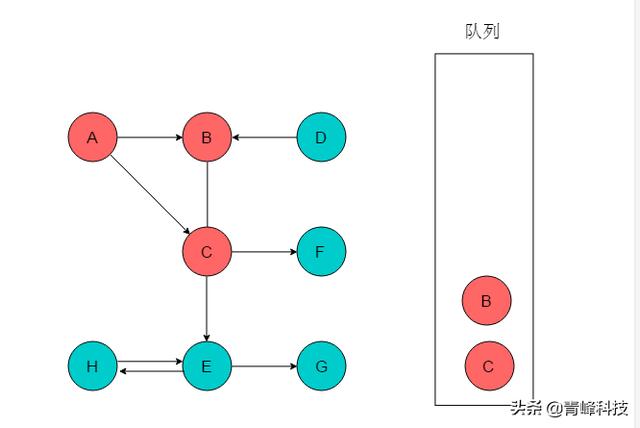
(3)隊列頭為B,B出隊列。B的鄰接頂點為C,C已經被標記,因此無新元素入隊列。
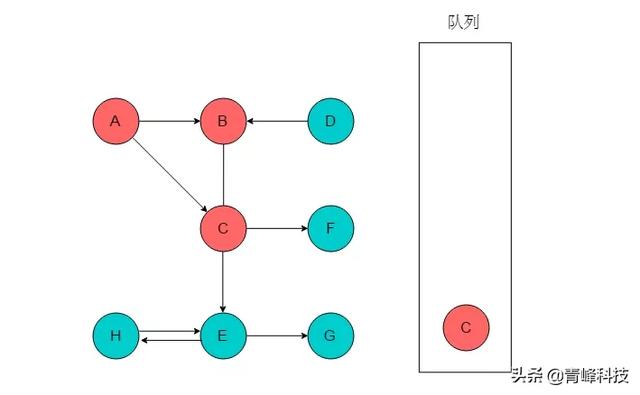
(4)隊列頭為C,C出隊列。C的鄰接頂點有E、F。輸出E、F,將E、F入隊列,并標記E、F。
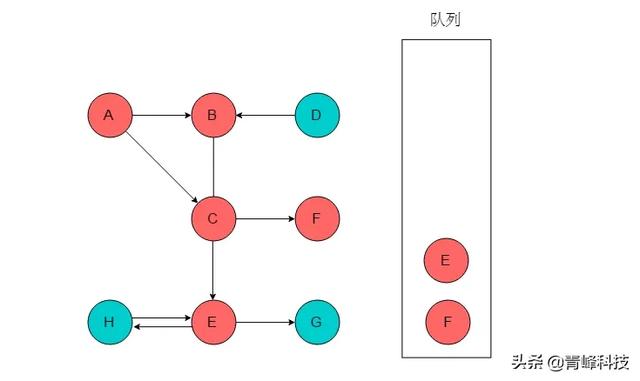
(5)隊列頭為E,E出隊列。E的鄰接頂點有G、H。輸出G、H,將G、H入隊列,并標記G、H。
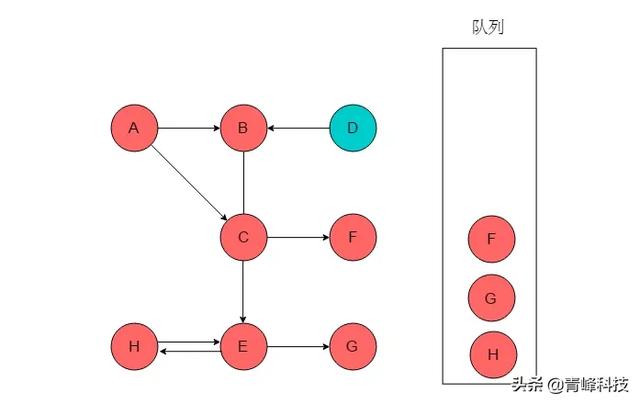
(6)隊列頭為F,F出隊列。F無鄰接頂點。
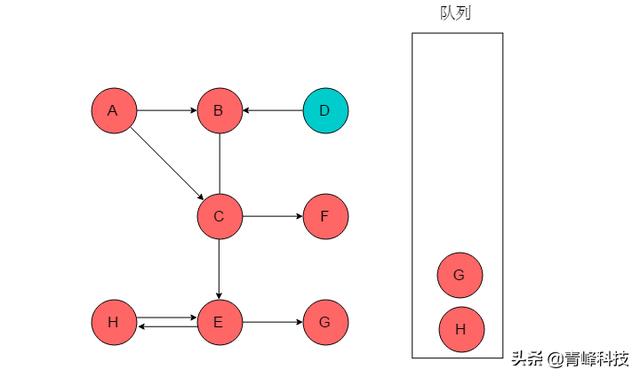
(7)隊列頭為G,G出隊列。G無鄰接頂點。
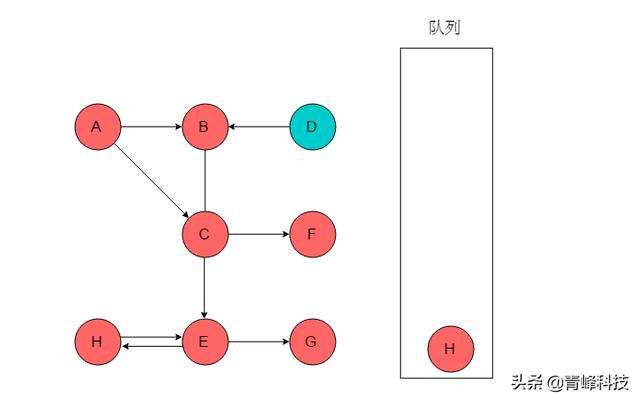
(8)隊列頭為H,H出隊列。H鄰接頂點為E,但是E已被標記,無新元素入隊列。
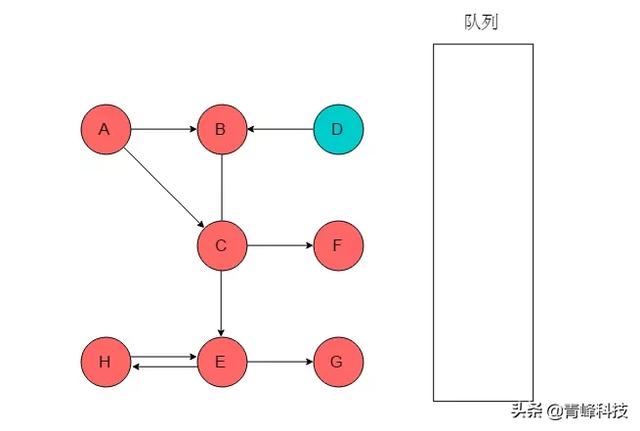
(9)隊列為空,以A為起始點的遍歷過程結束,此時圖中仍有D未被訪問,則以D為起始點繼續遍歷。選取D為起始點,輸出D,將D入隊列,標記D。
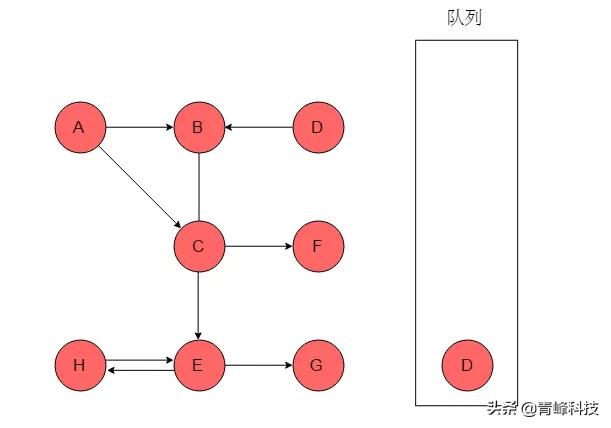
(10)隊列頭為D,D出隊列,D的鄰接頂點為B,B已被標記,無新元素入隊列。
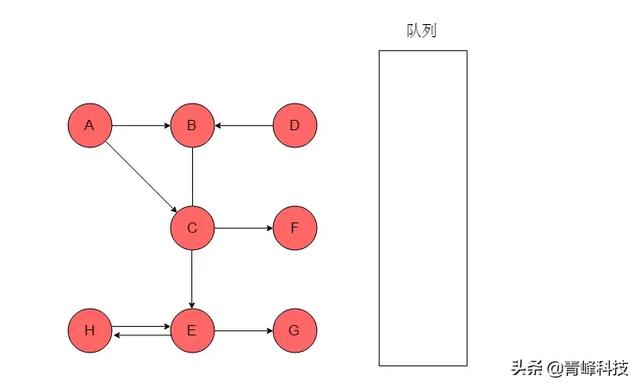
(11)隊列為空,且所有元素均被訪問,廣度優先搜索遍歷過程結束。廣度優先搜索的輸出序列為:A->B->E->C->D->F->G->H。
3.4 算法分析
假設圖有V個頂點,E條邊,廣度優先搜索算法需要搜索V個節點,時間消耗是O(V),在搜索過程中,又需要根據邊來增加隊列的長度,于是這里需要消耗O(E),總得來說,效率大約是O(V+E)。
4 總結
圖的遍歷主要就是這兩種遍歷思想,深度優先搜索使用遞歸方式,需要棧結構輔助實現。廣度優先搜索需要使用隊列結構輔助實現。在遍歷過程中可以看出,對于連通圖,從圖的任意一個頂點開始深度或廣度優先遍歷一定可以訪問圖中的所有頂點,但對于非連通圖,從圖的任意一個頂點開始深度或廣度優先遍歷并不能訪問圖中的所有頂點。




















