模型也可以上網(wǎng)課?!一文看懂服務(wù)型蒸餾訓(xùn)練方案
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
自今年年初,由于疫情的原因,為了減少人員聚集,降低病毒擴(kuò)散的可能性,各大中小學(xué)校都陸續(xù)開始了網(wǎng)上教學(xué)。上網(wǎng)課已經(jīng)成了家喻戶曉的一種學(xué)習(xí)方式了。
可是你知道嗎,在深度學(xué)習(xí)領(lǐng)域,模型訓(xùn)練也是可以采用網(wǎng)課形式,不用那么震驚,這個真的有!這就是今天要講的LF AI基金會的EDL項(xiàng)目基于飛槳深度學(xué)習(xí)平臺推出的服務(wù)型蒸餾訓(xùn)練方案!
什么是蒸餾訓(xùn)練?
要講蒸餾訓(xùn)練就要提到知識蒸餾。如今深度學(xué)習(xí)模型正在往越來越大,網(wǎng)絡(luò)層越來越深的方向發(fā)展。在很多場景下,模型越大,層數(shù)越多,模型效果就越好。但受限于推理速度,顯存資源等要求,大模型通常無法直接部署,需要對模型進(jìn)行壓縮。
目前主流的壓縮方法有裁剪、量化、知識蒸餾等。其中知識蒸餾這一概念是由Hinton等人在2015年發(fā)表的《Distilling the Knowledge in a Neural Network》論文中提出的一個黑科技,一種非常經(jīng)典的模型壓縮技術(shù),是將知識從一個復(fù)雜模型(Teacher)遷移到另一個輕量級模型(Student)上的方式來實(shí)現(xiàn)模型壓縮。
其實(shí)所謂知識的遷移,其實(shí)可以理解為一種訓(xùn)練過程,就是使用Teacher模型來訓(xùn)練Student模型,這種訓(xùn)練方法就是蒸餾訓(xùn)練。在訓(xùn)練出一個效果良好的Student模型后,這個Student模型就可以被用于實(shí)際部署了。
如下圖所示,訓(xùn)練步驟可以分為兩步:
- 訓(xùn)練好一個Teacher模型。
- 訓(xùn)練Student模型,即使用Teacher模型的知識來訓(xùn)練Student模型。
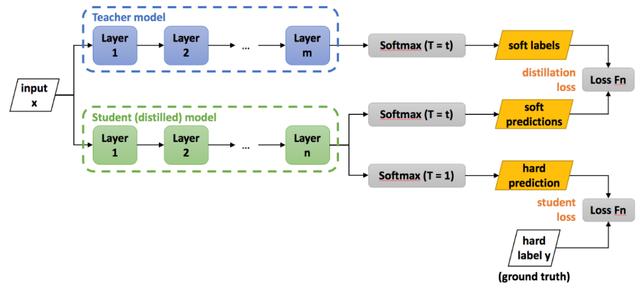
△知識蒸餾架構(gòu)圖
所謂Teacher模型的知識是指Teacher模型的推理結(jié)果,我們稱之為soft label,這個soft label將作為Student網(wǎng)絡(luò)的訓(xùn)練目標(biāo),Student的推理結(jié)果需要盡可能接近Teacher的推理結(jié)果。與soft label相對應(yīng)的是hard label,hard label就是真實(shí)訓(xùn)練數(shù)據(jù)的標(biāo)簽。相比于hard label,soft label所含的信息量更大。
舉個例子,比如做區(qū)分驢和馬的分類任務(wù)的時(shí)候,soft label不會像hard label那樣只給馬的index值為1,其余類別為0,而是在驢的部分也會提供一個概率值(例如0.3或0.4之類),這樣的優(yōu)勢在于使soft label包含了不同類別之間的相似性信息。顯而易見,使用soft label訓(xùn)練出來的模型肯定要比單獨(dú)使用hard label訓(xùn)練出來的模型學(xué)習(xí)到更多的知識,也就更加的優(yōu)秀。
知識蒸餾訓(xùn)練的目標(biāo)函數(shù)可由distillation loss(對應(yīng)teacher soft label)和student loss(對應(yīng)標(biāo)注的hard label)加權(quán)得到。公式如下,其中p表示Student模型的推理結(jié)果,q為teacher的推理結(jié)果,y為hard label。
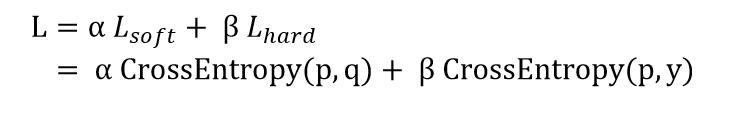
什么是服務(wù)型蒸餾訓(xùn)練?
說完蒸餾訓(xùn)練了,下面我們進(jìn)入正題,來看看我們這個服務(wù)型蒸餾訓(xùn)練到底是個什么東東!蒸餾訓(xùn)練可以分為如下三種方式:
離線蒸餾訓(xùn)練
離線蒸餾訓(xùn)練的方式很像是老師(Teacher)把要講課的內(nèi)容錄制成視頻交給學(xué)生(Student)去自學(xué),然后學(xué)生根據(jù)課程視頻自學(xué)成才。所以離線蒸餾訓(xùn)練就是先使用Teacher模型做推理并將結(jié)果保存在磁盤中,然后Student模型使用磁盤中保存的樣本和Teacher模型的推理結(jié)果作為數(shù)據(jù)集進(jìn)行訓(xùn)練。這種訓(xùn)練方式下Student模型訓(xùn)練和常規(guī)訓(xùn)練一致,方法簡單。不過這種訓(xùn)練方式一般需要數(shù)據(jù)增強(qiáng),而且需要占用巨大的磁盤空間,因此應(yīng)用環(huán)境受到了一定的限制。
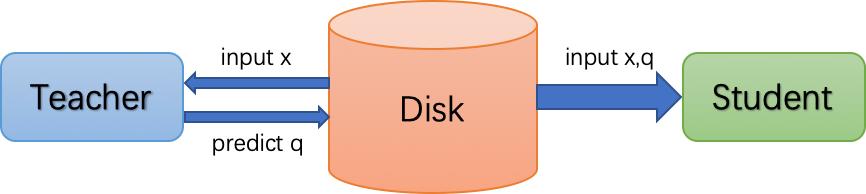
△ 離線蒸餾訓(xùn)練
常規(guī)蒸餾訓(xùn)練
常規(guī)蒸餾訓(xùn)練是指將Teacher模型和Student模型放入同一網(wǎng)絡(luò)中,固定Teacher模型參數(shù)只做前向,Student模型則正常做反向傳播訓(xùn)練。這也是目前主流的蒸餾訓(xùn)練方式。這和現(xiàn)實(shí)生活中常規(guī)的教學(xué)方式很像,老師和學(xué)生在一個教室里,老師說一句,學(xué)生聽一句。但是這種訓(xùn)練方式不僅Teacher模型本身需要占用較大的空間,而且由于Teacher和Student是1對1的綁定關(guān)系,Student模型的訓(xùn)練完全依賴Teacher模型,Student模型要等Teacher模型輸出一個batch的推理結(jié)果才可以訓(xùn)練,而teacher模型也要等Student訓(xùn)練完一個batch,才能開始下一個batch的推理,對整體的訓(xùn)練速度有一定的影響。
服務(wù)型蒸餾訓(xùn)練
服務(wù)型蒸餾訓(xùn)練是基于EDL(Elastic Deep Learning,彈性深度學(xué)習(xí)框架)提出的一種訓(xùn)練方案。EDL是Linux基金會(LF)旗下負(fù)責(zé)人工智能和大數(shù)據(jù)深度學(xué)習(xí)領(lǐng)域的基金會LF AI正在孵化的重要項(xiàng)目之一。如今在云計(jì)算資源蓬勃發(fā)展的條件下,利用彈性資源進(jìn)行深度學(xué)習(xí)模型訓(xùn)練和推理將成為一種普遍現(xiàn)象,因此EDL項(xiàng)目應(yīng)運(yùn)而生。EDL項(xiàng)目可以使云上深度學(xué)習(xí)模型的訓(xùn)練和推理變得更容易和更有效。而服務(wù)型蒸餾訓(xùn)練方案就是EDL項(xiàng)目結(jié)合百度飛槳開源深度學(xué)習(xí)平臺而推出了一種新的訓(xùn)練方案,可謂出身名門!

與常規(guī)蒸餾訓(xùn)練相比,服務(wù)型蒸餾訓(xùn)練將Teacher模型和Student模型解耦,Teacher模型被部署為線上推理服務(wù),Student模型則以客戶端的身份通過互聯(lián)網(wǎng)實(shí)時(shí)發(fā)送樣本到Teacher模型獲取推理結(jié)果進(jìn)行訓(xùn)練,這就如同讓模型上網(wǎng)課。那么讓模型上網(wǎng)課可以給用戶帶來什么收益呢?咱們往下看!
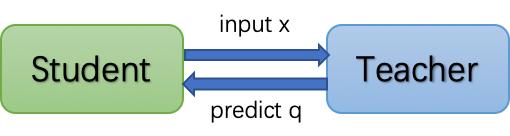
△ 服務(wù)蒸餾訓(xùn)練
服務(wù)型蒸餾訓(xùn)練的價(jià)值
相比于常規(guī)的蒸餾訓(xùn)練模式相比,服務(wù)型蒸餾訓(xùn)練可以給用戶帶來如下收益:
- 節(jié)約顯存資源。由于Student模型和Teacher模型的解耦,所以服務(wù)型蒸餾訓(xùn)練可以使用異構(gòu)的資源,也就是把Student模型和Teacher模型的部署到不同的設(shè)備上。原先受限于顯存大小而難以部署到單個GPU卡上的蒸餾網(wǎng)絡(luò)可以通過該方式部署到不同卡上。
- 提升訓(xùn)練速度。由于節(jié)約了顯存資源,這樣就可以使Student模型能夠訓(xùn)練更大的batch size;同時(shí)由于Student模型和Teacher模型是異構(gòu)流水線,Student模型不用等Teacher模型推理結(jié)束后再訓(xùn)練,綜合上述兩個原因,可以大大提高訓(xùn)練速度。
- 提高訓(xùn)練資源利用率。在實(shí)際應(yīng)用中,我們可以將Teacher模型部署到線上的彈性預(yù)估卡集群,利用線上預(yù)估卡閑時(shí)的算力資源提升蒸餾任務(wù)中Teacher模型側(cè)的吞吐量。同時(shí)由于Teacher模型可以彈性調(diào)度,不用擔(dān)心高峰時(shí)線上實(shí)例被搶占造成的任務(wù)失敗。相當(dāng)于把teacher對訓(xùn)練卡的資源需求轉(zhuǎn)移到了在線GPU卡上,在v100等離線訓(xùn)練資源受限的情況下,使用在線卡對訓(xùn)練進(jìn)行加速,以節(jié)約寶貴的訓(xùn)練資源。此外,在離線集群上,結(jié)合調(diào)度策略,還可以將Teacher模型部署到集群碎片資源,或者如k40等使用率較低的資源上,充分利用集群的空閑、碎片資源。
- 提升訓(xùn)練效率。用戶可以根據(jù)Teacher和Student的吞吐性能靈活設(shè)置Teacher和Student的比例,也就是說多個老師可以教多個學(xué)生,而不是只能保持1比1的家教模式,最大限度地提高訓(xùn)練的產(chǎn)出。
為了驗(yàn)證服務(wù)型蒸餾訓(xùn)練的效果,我們在ImageNet數(shù)據(jù)集上使用普通訓(xùn)練、常規(guī)蒸餾訓(xùn)練和服務(wù)型蒸餾訓(xùn)練幾個不同方式來訓(xùn)練ResNet50_vd模型。
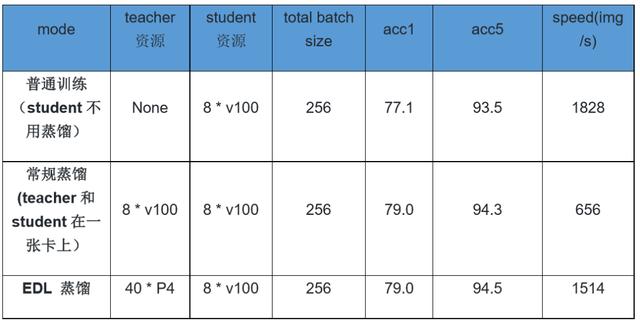
在精度上,可以看出相比于普通訓(xùn)練,蒸餾訓(xùn)練提升了ResNet50_vd模型近2%的精度。而服務(wù)型蒸餾訓(xùn)練和常規(guī)蒸餾訓(xùn)練在精度上持平。當(dāng)然該模型的蒸餾精度遠(yuǎn)不止于此,關(guān)于知識蒸餾更多提升精度的技巧請參考如下地址:
https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/distillation/index.html
在速度上,相比于普通訓(xùn)練,常規(guī)蒸餾訓(xùn)練由于Teacher模型占用了很大一部分算力,所以在相同訓(xùn)練資源的情況下,訓(xùn)練速度僅為普通訓(xùn)練的35.9%。而服務(wù)型蒸餾訓(xùn)練由于使用了額外的在線P4彈性資源,將Teacher對訓(xùn)練卡的資源需求轉(zhuǎn)移到了彈性卡上,所以相比于普通訓(xùn)練,仍保持有82.8%的訓(xùn)練效率,速度為常規(guī)蒸餾訓(xùn)練2.3倍。
如果繼續(xù)增加Teacher資源,理論上EDL服務(wù)型蒸餾訓(xùn)練的速度是可以和普通訓(xùn)練速度持平的。當(dāng)然常規(guī)蒸餾訓(xùn)練如果加大資源,也是可以繼續(xù)加速的,不過這樣就占用了更多寶貴的v100訓(xùn)練資源了。
服務(wù)型蒸餾訓(xùn)練既然那么厲害,那它是怎么做到的呢?咱們來看看它的具體實(shí)現(xiàn)。
服務(wù)型蒸餾訓(xùn)練的實(shí)現(xiàn)方案
從具體實(shí)現(xiàn)的角度看,服務(wù)型蒸餾訓(xùn)練之所以被稱為服務(wù),就是因?yàn)樗鼘eacher模型部署成了服務(wù)端,而Student模型成了客戶端。如下圖所示,該方案可以描述為將Teacher模型被部署為在線可容錯彈性服務(wù),而在Student模型一側(cè)則通過DistillReader來封裝Student模型與Teacher模型之間的通信,訪問Teacher服務(wù)。下面咱們分別介紹下DistillReader和可容錯彈性服務(wù)都是啥?
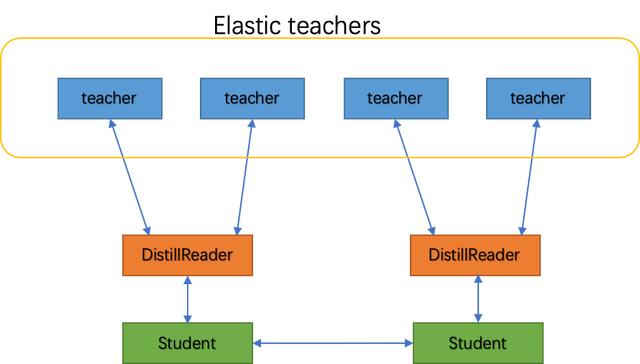
△ 服務(wù)型蒸餾訓(xùn)練架構(gòu)圖
DistillReader
DistillReader用來代表Student模型向Teacher模型進(jìn)行通信,從而產(chǎn)生可供Student模型訓(xùn)練的數(shù)據(jù)reader。如下圖所示,Student模型將訓(xùn)練樣本和標(biāo)簽傳入訓(xùn)練reader,DistillReader從訓(xùn)練reader中讀取訓(xùn)練樣本發(fā)送給Teacher模型,然后獲取推理結(jié)果。推理結(jié)果和原訓(xùn)練reader中的數(shù)據(jù)封裝在一起,返回一個包含推理結(jié)果的新reader給Student模型,這樣TEACHER模型的推理和STUDENT模型的訓(xùn)練就可以流水行并行起來了。
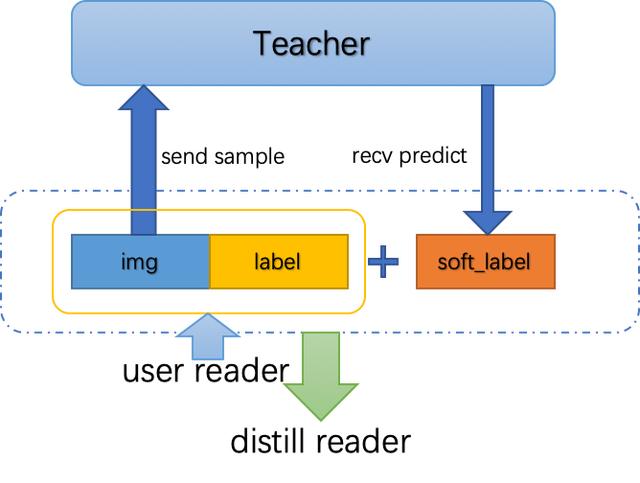
△ DistillReader功能示意圖
可容錯彈性服務(wù)
可容錯彈性服務(wù)的實(shí)現(xiàn)架構(gòu)如下圖所示,首先我們通過Paddle Serving將多個Teacher模型部署成服務(wù),并注冊服務(wù)到Redis數(shù)據(jù)庫中;Student模型則作為客戶端從服務(wù)發(fā)現(xiàn)中查詢所需的Teacher服務(wù);服務(wù)發(fā)現(xiàn)從Redis數(shù)據(jù)庫查詢并按某種負(fù)載均衡策略返回客戶端所需的Teacher列表;每當(dāng)Teacher變化時(shí),客戶端就可以實(shí)時(shí)拿到最新Teacher列表,連接Teacher進(jìn)行蒸餾訓(xùn)練,不用擔(dān)心發(fā)生由于連接到被收回的Teacher資源而導(dǎo)致任務(wù)失敗的請況。
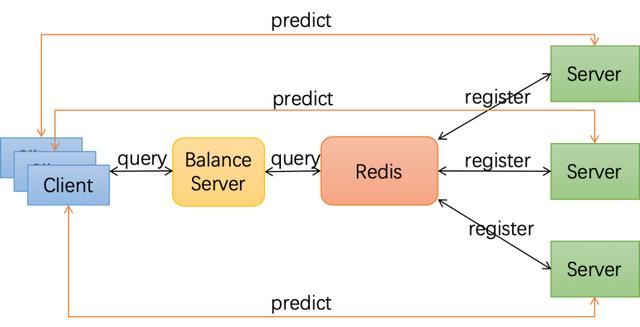
△ 彈性伸縮服務(wù)架構(gòu)圖
如下圖所示,該圖是服務(wù)型蒸餾訓(xùn)練運(yùn)行的流程圖,圖中可以看到STUDENT模型給TEACHER模型發(fā)送樣本并獲取推理結(jié)果,而TEACHER模型服務(wù)側(cè)則可以隨意增刪,彈性調(diào)整。
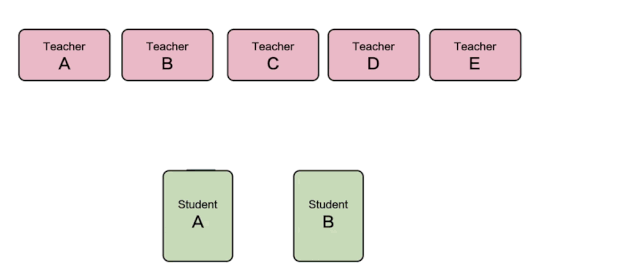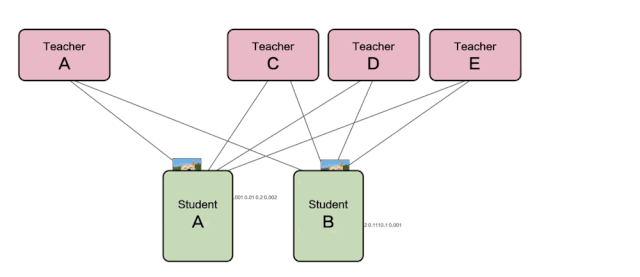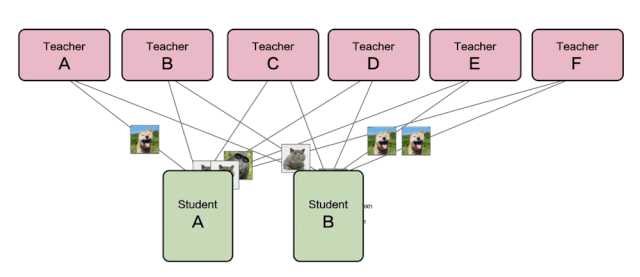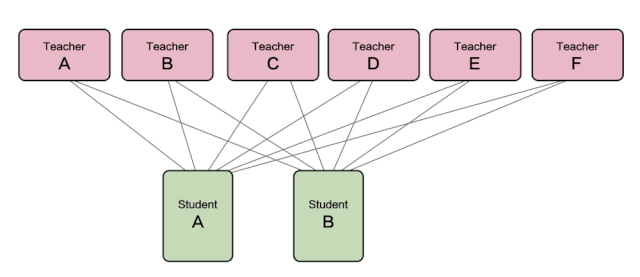
△ 服務(wù)型蒸餾訓(xùn)練流程圖
在了解了實(shí)現(xiàn)方案后,那么怎么使用服務(wù)蒸餾訓(xùn)練呢?下面我們通過一個操作示例為大家簡單介紹一下。
服務(wù)型蒸餾訓(xùn)練實(shí)踐
我們通過訓(xùn)練圖像分類模型來給大家演示下如何使用服務(wù)型蒸餾訓(xùn)練。由于僅是演示,這里我們使用的是單機(jī)環(huán)境,也就是說服務(wù)端和客戶端部署在了同一個服務(wù)器上,服務(wù)端的IP地址是127.0.0.1。如果部署在不同設(shè)備上,修改下代碼中的IP地址即可。
環(huán)境準(zhǔn)備
請執(zhí)行如下命令拉取鏡像,鏡像為CUDA9.0的環(huán)境,在里面我們預(yù)裝了EDL、飛槳核心框架和Padde Serving等相關(guān)依賴。
- docker pull hub.baidubce.com/paddle-edl/paddle_edl:latest-cuda9.0-cudnn7
- nvidia-docker run -name paddle_edl hub.baidubce.com/paddle-edl/paddle_edl:latest-cuda9.0-cudnn7 /bin/bash
啟動Teacher模型
請執(zhí)行如下命令在1號GPU卡啟動Teacher服務(wù),其中Teacher模型為圖像分類模型ResNeXt101_32x16d_wsl,服務(wù)的端口號為9898,并啟動了內(nèi)存優(yōu)化功能。
- cd example/distill/resnet
- wget --no-check-certificate https://paddle-edl.bj.bcebos.com/distill_teacher_model/ResNeXt101_32x16d_wsl_model.tar.gz
- tar -zxf ResNeXt101_32x16d_wsl_model.tar.gz
- python -m paddle_serving_server_gpu.serve \
- --model ResNeXt101_32x16d_wsl_model \
- --mem_optim True \
- --port 9898 \
- --gpu_ids 1
啟動Student模型訓(xùn)練
請執(zhí)行如下命令在0號GPU卡啟動Student模型,啟動的student模型為ResNet50_vd,。
- python -m paddle.distributed.launch --selected_gpus 0 \
- ./train_with_fleet.py \
- --model=ResNet50_vd \
- --data_dir=./ImageNet \
- --use_distill_service=True \
- --distill_teachers=127.0.0.1:9898
其中train_with_fleet.py是用于啟動訓(xùn)練的腳本,用戶需要在其中添加蒸餾訓(xùn)練相關(guān)的代碼,如果用戶想了解腳本的修改方法或可以參考如下地址。
https://github.com/elasticdeeplearning/edl/blob/develop/example/distill/README.md