













有限數據量如何最大化提升模型效果?百度工程師構建數據增強服務
在AI模型開發的過程中,許多開發者被不夠充足的訓練數據擋住了提升模型效果的腳步,一個擁有出色效果的深度學習模型,支撐它的通常是一個龐大的標注數據集。因此,提升模型的效果的通用方法是增加數據的數量和多樣性。但在實踐中,收集數目龐大的高質量數據并不容易,在某些特定領域與應用場景甚至難以獲取大量數據。那么如何能在少量數據的情況下提升模型的效果呢?
隨著深度學習的發展,數據增強技術可以協助開發者解決數據量不夠充足的問題。數據增強技術通過對數據本身進行一定程度的擾動從而產生“新”數據,模型通過不斷學習大量的“新”數據來提升泛化能力。
不同數據集的數據特性決定了其所適用的數據增強策略組合,在沒有對數據特性有專業理解能力的情況下,用戶很難構建出能與數據集特性強相關的數據增強策略組合。比如在標準的ImageNet數據預處理流程中有使用Random Crop (隨機剪裁)、Random Flip (隨機翻轉) 等數據增強技術,取得了不錯的效果增益,但在某些特定用戶場景(如零售場景SKU摳圖場景)數據邊緣存在重要信息時Random Crop會導致信息的損失、在某些特定用戶場景(如數字識別)時Random Flip會導致特征的混淆。因此如何根據數據特征來自動化搜索數據增強策略組合成為了一個熱門的研究方向。
追溯學術界對自動數據增強領域的研究,最具影響力的一篇論文是Google在2018年提出的AutoAugment技術。隨后,相關的優化論文層出不窮,簡單梳理依據現有方法的一些建模思想,如圖1。
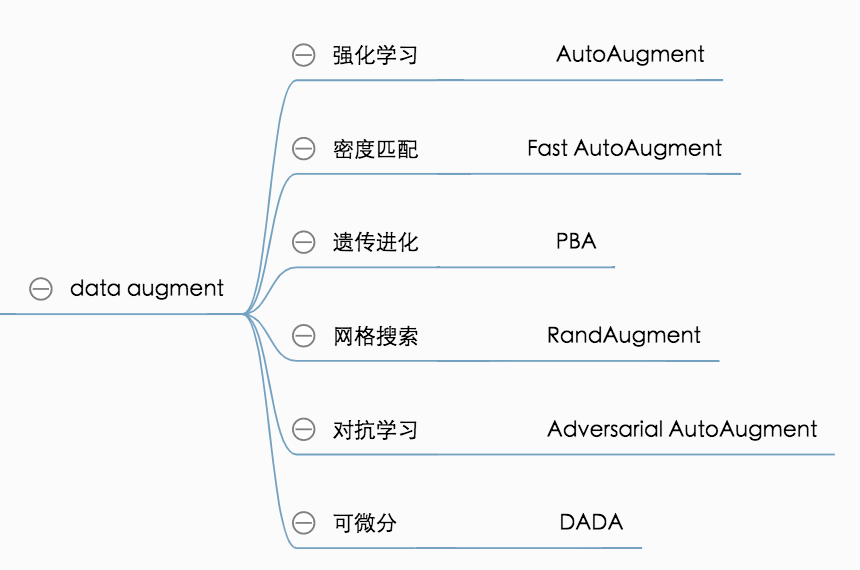
圖1 自動數據增強算法建模思路歸類
1)強化學習: AutoAugment [1] 借鑒了基于強化學習的架構搜索算法,在離散化的搜索空間內通過PPO (Proximal Policy Optimization)算法來訓練一個policy generator, policy generator的獎勵信號是其生成的policy應用于子網絡訓練完畢后的驗證集準確率。其問題在于AutoAugment的搜索成本非常高,還無法滿足工業界的業務需求,難以應用在業務模型開發中。
2)密度匹配: Fast AutoAugment [2] 采用了密度匹配的策略,希望驗證數據通過數據增強后的數據點能與原始訓練數據集的分布盡量匹配。這個思路直覺上可以排除一些導致數據集畸變的增強策略,但沒有解決“如何尋找最優策略”這一問題。
3)遺傳進化: PBA [3] 采用了PBT的遺傳進化策略,在多個網絡的并發訓練中不斷“利用”和“擾動”網絡的權重,以期獲得最優的數據增強調度策略。這個思路直覺上是可以通過優勝劣汰來搜索到最優策略。
4)網格搜索: RandAugment [4] 通過統一的強度和概率參數來大幅減小搜索空間,期望能用網格搜索就解決數據增強搜索的問題。但這一技術并不具備策略的可解釋性,拋開實現手段不談,這篇論文更像是對AutoAugment的自我否定(注: RandAugment也是Google出品的論文)。
5)對抗學習: Adversarial AutoAugment [5] 在AutoAugment的基礎上借鑒了GAN的對抗思想,讓policy generator不斷產生難樣本,并且使policy generator和分類器能并行訓練,降低了搜索時長。但整體搜索成本還是非常高。
6)可微分: DADA[6]借鑒了DARTS的算法設計思路,將離散的參數空間通過Gumbel-Softmax重參數化成了可微分的參數優化問題,大大降低了搜索成本。
在上述的建模思路中,遺傳進化和可微分的建模思路更適合應用到模型開發中,因為這兩種思路將自動數據增強搜索的成本降低到了線上業務承受的資源范圍內,并且具備較好的策略可解釋性。基于對建模思路的評估和判斷,百度工程師決定將遺傳進化和可微分思路應用到零門檻AI開發平臺EasyDL中,便于開發者進一步優化模型效果。
EasyDL面向企業開發者提供智能標注、模型訓練、服務部署等全流程功能,針對AI模型開發過程中繁雜的工作,提供便捷高效的平臺化解決方案,并且內置了豐富的預訓練模型與優化的多種算法網絡,用戶可在少量業務數據上獲得高精度的模型效果。EasyDL面向不同人群提供了經典版、專業版、行業版三種產品形態。
目前,遺傳進化PBA技術已經在EasyDL平臺中的成功實現,可微分的技術思路在EasyDL業務中的實踐也在持續探索中。
PBA采用了PBT [7]的遺傳進化策略,通過訓練一群神經網絡(種群, Trials)來找出超參數調度。Trials之間會周期性地將高性能Trial的權重復制給低性能的Trial(exploit),并且會有一定的超參擾亂策略(explore),如圖2的PBT流程圖。
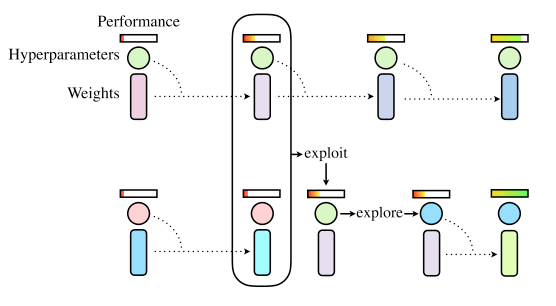
圖2 PBT算法流程圖
然而實際將能力落地到平臺中并不容易,工程師們在復現論文開源代碼的過程中發現了一些問題:
1)開源代碼采用了Ray的Population Based Training實現,但這個接口并不能保證并行的Trials一定能實現同步的exploit, 尤其在資源受限的情況下,很大概率會出現進化程度較高的Trial和進化程度較低的Trial之間的exploit,這樣的錯誤進化是不可接受的。
2)開源代碼僅實現了單機多卡版本的搜索能力,想擴展到多機多卡能力,需要基于Ray做二次開發。
3)開源代碼僅實現了圖像分類的自動數據增強搜索,并未提供物體檢測等其他任務的數據增強搜索能力。
4)開源代碼現有增強算子實現方式比較低效。
綜合以上考慮,最終百度工程師從零開始構建了基于PBA的自動數據增強搜索服務。
這一自研自動數據增強搜索服務有以下幾個特點:
- 實現了標準的PBT算法,支持種群Trials的同步exploit、explore,保證公平進化。
- 支持分布式拓展,可不受限的靈活調節并發種群數,支持。
- 搜索服務與任務解耦,已支持飛槳深度學習平臺的圖像分類、物體檢測任務,并且可擴展到其他的視覺任務與文本任務。
- 數據增強算子基于C++高效實現。
自研的能力效果如何呢?在公開數據集上,百度工程師基于自研的自動數據增強搜索服務與現有的Benchmark進行了對齊,其中表一的ImageNet Benchmark在PaddleClas[8]框架上訓練,表二的Coco Benchmark在PaddleDetection [9]框架上訓練。
結果顯示,EasyDL自動數據增強服務能達到與AutoAugment同樣高的精度,并有大幅的速度優勢。目前,用于數據增強搜索的分類、檢測算子已經與AutoAugment對齊,后續將會持續不斷擴充更多更高效的算子,進一步提升模型效果。
|
模型 |
數據變化策略 |
TOP1 Acc |
數據增強策略搜索時長(GPU hours) |
|
ResNet50 |
標準變換 |
0.7731 |
\ |
|
AutoAugment |
0.7795 |
15000[1](P100) |
|
|
EasyDL自動數據增強服務 |
0.7796 |
45(V100) |
|
|
MobileNetV3_ small_x1_0 |
標準變換 |
0.682 |
\ |
|
EasyDL自動數據增強服務 |
0.68679 |
28(V100) |
表一 ImageNet Benchmark [8]
|
模型 |
數據變化策略 |
Box AP |
增強策略搜索時長(GPU hours) |
|
Faster_RCNN_R50_ VD_FPN_3x |
AutoAugment |
39.9 |
48*400[10](TPU) |
|
EasyDL自動數據增強服務 |
39.3 |
90(V100) |
表二 Coco Benchmark [9]
EasyDL目前已在經典版上線了手動數據增強服務,在專業版上線了自動數據增強搜索服務。在圖像分類單標簽的任務上,工程師隨機挑選了11個線上任務進行效果評測。如下圖,使用專業版自動數據增強服務后,11個任務準確率平均提長了5.42%, 最高一項任務獲得了18.13%的效果提升。
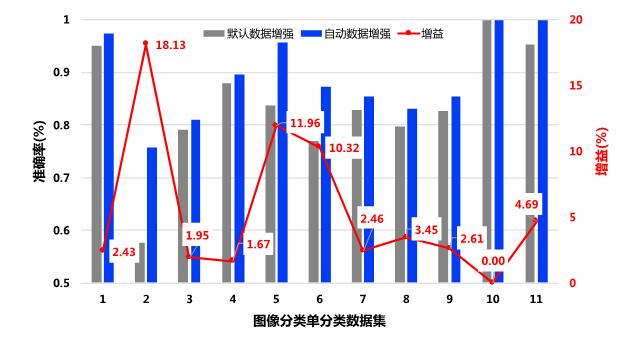
圖3 圖像分類單分類效果評測
在物體檢測任務上,通過隨機挑選的12個線上任務進行了效果評測,效果對比如下圖,使用專業版自動數據增強服務后11個任務準確率平均提升了1.4%, 最高一項任務獲得了4.2%的效果提升。
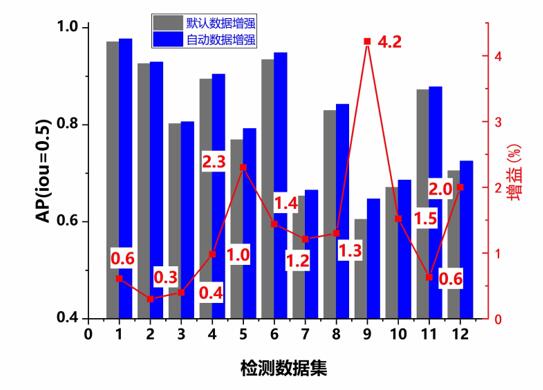
圖4 物體檢測效果評測
EasyDL平臺通過交互式的界面,為用戶提供簡單易上手的操作體驗。同樣,使用EasyDL的數據增強服務操作非常簡便。
目前,由于訓練環境的資源消耗不同,EasyDL經典版與專業版提供兩種數據增強策略。
在經典版中,已經上線了手動配置數字增強策略。如圖5,用戶可以在訓練模型頁面選擇“手動配置”,實現數據增強算子的使用。
在專業版中,由于提供訓練環境的多種選擇,目前已支持自動搜索策略。如圖6,在新建任務頁面的“數據增強策略”中選擇“自動搜索”,再設置需要搜索的算子范圍,即可立刻實現自動數據增強。
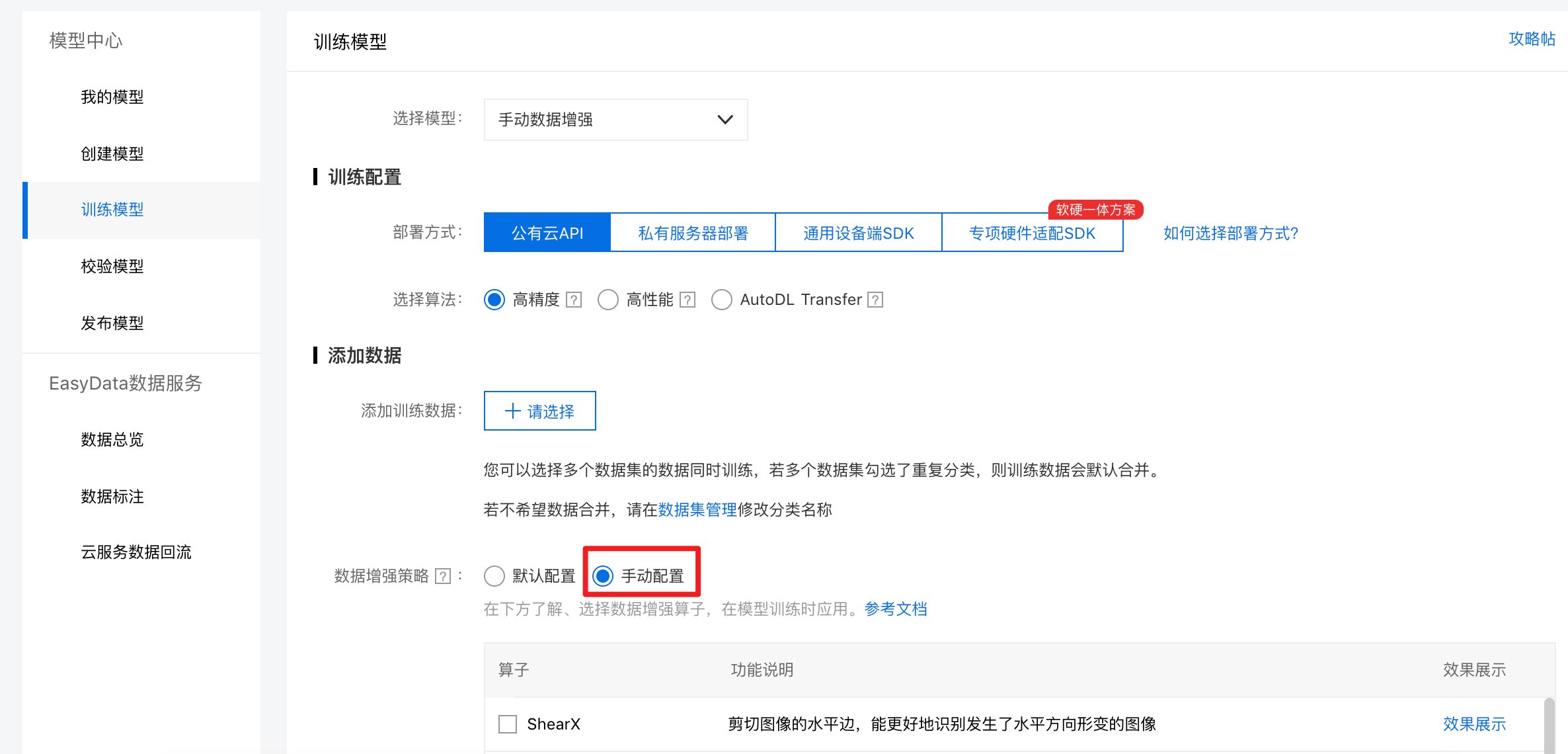
圖5 經典版手動數據增強使用流程
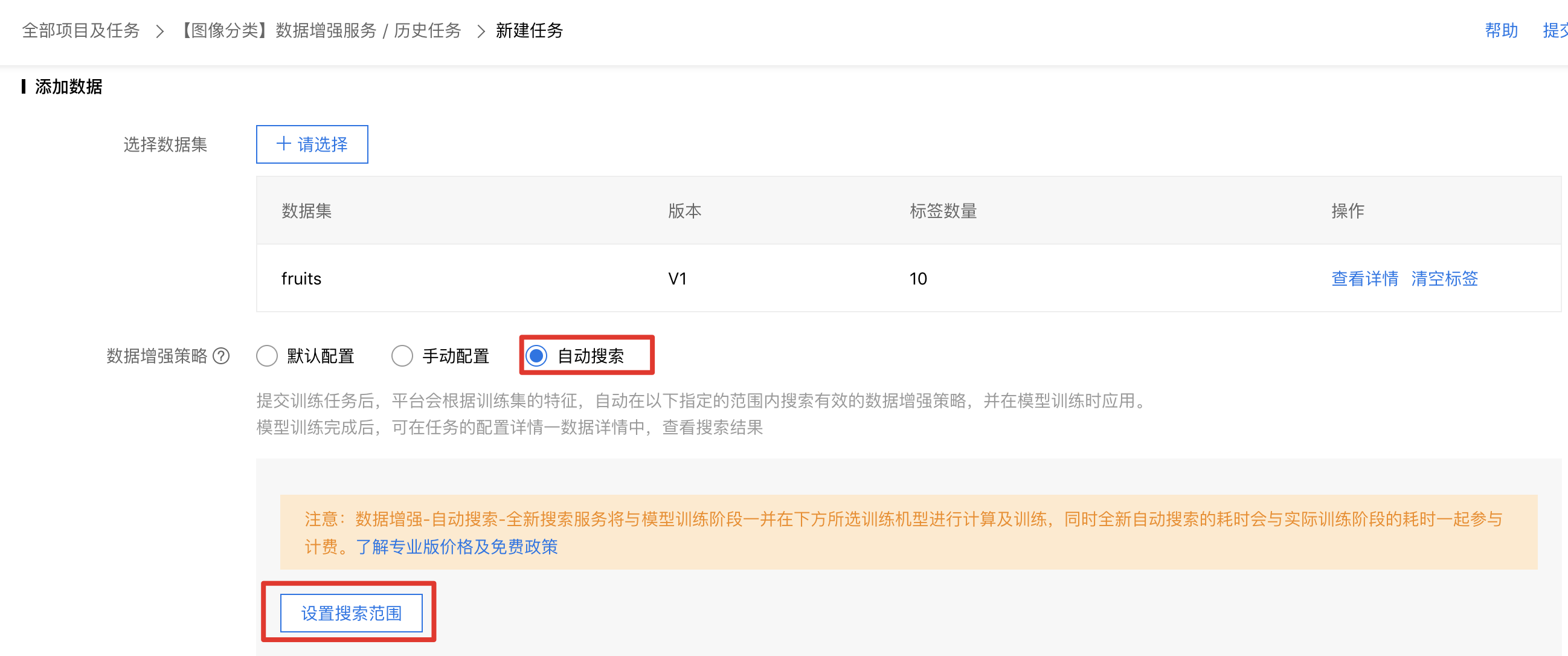
圖6 專業版自動數據增強使用流程
為了讓開發者使用EasyDL更便捷高效地開發效果出色的模型,EasyDL在框架設計中內置了多個組件與多種能力。如EasyDL智能搜索服務的整體架構圖(圖7)所示,其底層基礎組件是分布式智能搜索,具備多機多卡搜索、訓練容錯、支持多種搜索優化算法等特性。基于分布式智能搜索提供的核心能力,產品構建了自動數據增強搜索、超參搜索、NAS搜索等服務,盡可能讓用戶可以在無需關心技術細節的情況下,簡便使用EasyDL提供的多項搜索服務,獲得模型效果的優化。
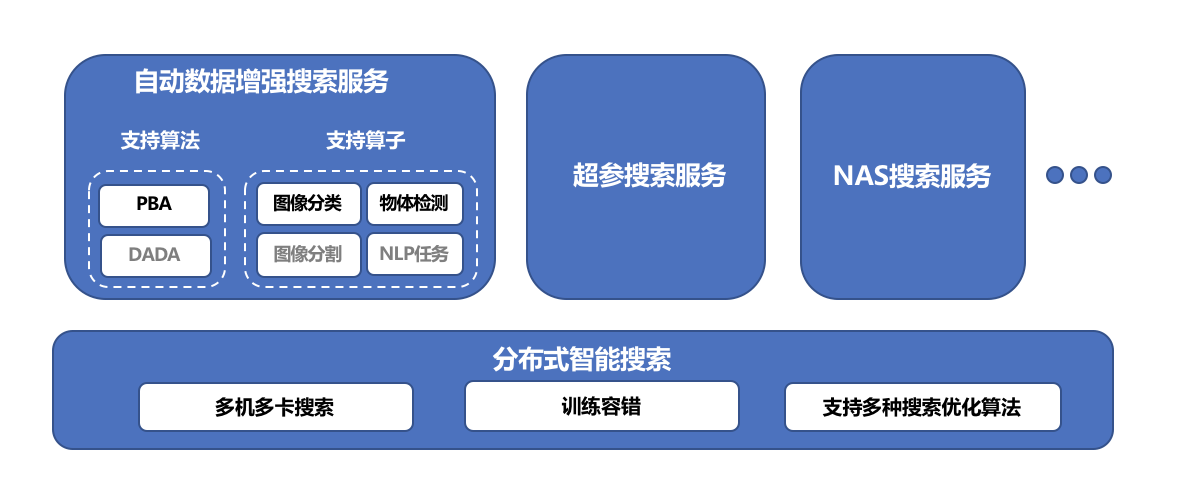
圖7 EasyDL智能搜索服務整體架構圖
在各行各業加速擁抱AI的今天,有越來越多的企業踏上智能化轉型之路,借助AI能力完成降本增效。但在AI賦能產業的過程中,大規模的商業化落地十分復雜,需要企業投入大量的精力。由于不同行業、場景存在著差異化與碎片化,對AI的需求也不盡相同。因此,一個能夠隨場景變化定制開發AI模型的平臺至關重要。通過零算法門檻的平臺能力覆蓋千變萬化的場景需求,并提供靈活適應具體業務的多種部署方式,這就是EasyDL。
EasyDL零門檻AI開發平臺,目前已在工業制造、智能安防、零售快消、交通運輸、互聯網、教育培訓等行業廣泛落地。
同時,除了零門檻AI開發平臺EasyDL,百度也推出了全功能AI開發平臺BML,面向企業數據科學家和算法工程師團隊,提供功能全面、可靈活定制和被深度集成的機器學習開發平臺。
百度搜索“EasyDL”或訪問鏈接,開發高精度AI模型。https://ai.baidu.com/easydl/
[1]:Cubuk E D, Zoph B, Mane D, et al. Autoaugment: Learning augmentation policies from data[J]. arXiv preprint arXiv:1805.09501, 2018.
[2]:Lim S, Kim I, Kim T, et al. Fast autoaugment[C]//Advances in Neural Information Processing Systems. 2019: 6665-6675.
[3]:Ho D, Liang E, Chen X, et al. Population based augmentation: Efficient learning of augmentation policy schedules[C]//International Conference on Machine Learning. 2019: 2731-2741.
[4]:Cubuk E D, Zoph B, Shlens J, et al. Randaugment: Practical automated data augmentation with a reduced search space[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 702-703.
[5]:Zhang X, Wang Q, Zhang J, et al. Adversarial autoaugment[J]. arXiv preprint arXiv:1912.11188, 2019.
[6]:Li Y, Hu G, Wang Y, et al. DADA: Differentiable Automatic Data Augmentation[J]. arXiv preprint arXiv:2003.03780, 2020.
[7]:Jaderberg M, Dalibard V, Osindero S, et al. Population based training of neural networks[J]. arXiv preprint arXiv:1711.09846, 2017.
[8]:https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/image_augmentation/ImageAugment.html#id6
[9]:https://github.com/PaddlePaddle/PaddleDetection/tree/master/configs/autoaugment
[10]: Zoph B, Cubuk E D, Ghiasi G, et al. Learning data augmentation strategies for object detection[J]. arXiv preprint arXiv:1906.11172, 2019.
















