Pandas閃回咒!如何在Python中重寫SQL查詢?

工作中,頻繁切換是件麻煩事兒。一些程序員只熟悉SQL中的數據操作,卻不熟悉Python中的數據操作,因此在完成項目時,我們不得不頻繁地在SQL和Python之間進行切換,導致了工作效率低下和生產能力下降。
本文就教你一種方法,使用Pandas在Python中輕松重現SQL結果。
入門指南
如果電腦中沒有pandas包,則需要先安裝一下:
- Conda install pandas
在這個階段,我們將使用著名的Kaggle泰坦尼克數據集:https://www.kaggle.com/c/titanic/data?select=test.csv。
安裝軟件包并下載數據后,需要將其導入Python環境中:
- import pandas as pd
- titanic_df = pd.read_csv("titanic_test_data.csv")
我們將使用pandas數據框架來存儲數據,還將用到各種pandas函數來操作數據框架。
- SELECT, DISTINCT, COUNT, LIMIT
讓我們從經常使用的簡單SQL查詢開始。

titanic_df [“ age”]。unique()將在此處返回唯一值的數組,因此需要使用len()來獲取唯一值的計數。
- SELECT,WHERE,OR,AND,IN(有條件選擇)
現在你知道了如何以簡單的方式探索數據框架,接著來嘗試一些條件吧(在SQL中是WHERE子句)。

如果只想從數據框架中選擇特定的列,則可以使用另一對方括號進行選擇。注意,如果要選擇多列,則需要在方括號內放置數組[“ name”,“ age”]。
isin()與SQL中的IN完全相同。要使用NOT IN,需要在Python中使用negation(〜)來獲得相同的結果。
- GROUP BY,ORDER BY,COUNT
GROUP BY和ORDER BY也是用來探索數據的流行SQL,讓我們在Python中嘗試一下。

如果只想對COUNT進行排序,可以將布爾值傳遞給sort_values函數;如果想對多列進行排序,則必須將布爾數組傳遞給sort_values函數。sum()函數將提供數據框架中的所有聚合數值總和列,如果只需要特定列,則需要使用方括號指定列名。
- MIN,MAX,MEAN,MEDIAN
最后,來嘗試一些常見的統計功能,這些功能對于數據探索非常重要。
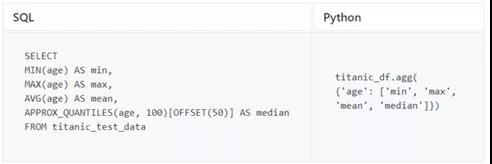
由于SQL沒有中位數函數,因此將使用BigQuery APPROX_QUANTILES獲取年齡中位數。pandas聚合函數.agg()還支持其他函數,例如sum。
拒絕頻繁切換,輕松重現查詢,你值得擁有!
你可以在我的Github中查看完整的腳本:https://github.com/chingjunetao/medium-article/tree/master/rewrite-sql-with-python
本文轉載自微信公眾號「讀芯術」,可以通過以下二維碼關注。轉載本文請聯系讀芯術公眾號。