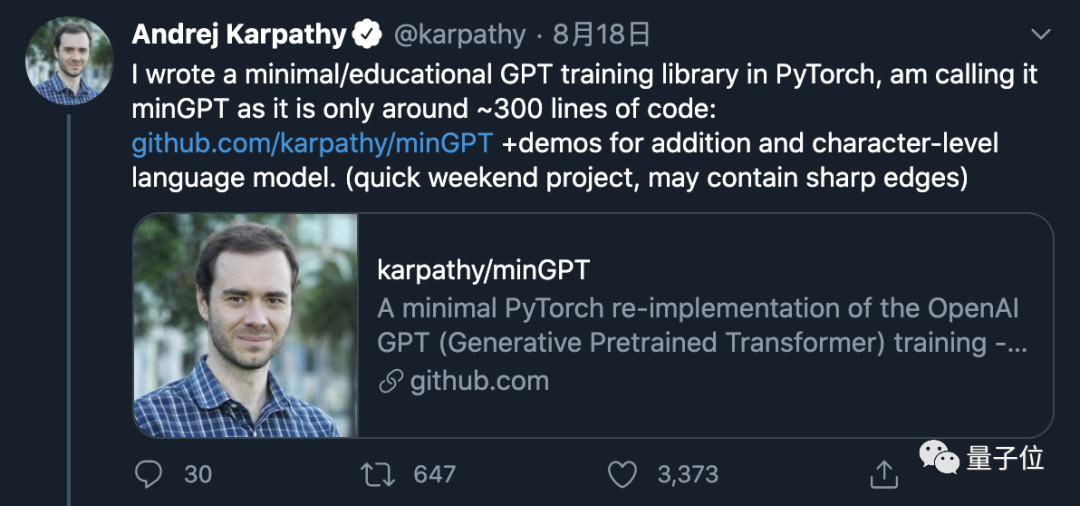
300行代碼實現“迷你版GPT”,上線三天收獲3.3k星
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
“GPT并不是一個復雜的模型。”
前OpenAI科學家、現任特斯拉AI總監的Andrej Karpathy在自己的GitHub項目里這樣寫道。
Karpathy這樣說是有底氣的,因為他自己只用大約300行PyTorch代碼就實現了一個“小型GPT”——minGPT。該項目上線3天以來,已經收獲了3.3k星。
“萬能”的NLP模型GPT-3這一個月來已經刷爆社交網絡,不過1750億個參數對算力的超高要求也讓人望而卻步。
但是在Karpathy看來,GPT所做的事情就是將一個索引序列放入一個transformer塊序列中,并得出下一個索引的概率分布。其余的復雜部分只是通過巧妙地進行批處理讓訓練更高效。
談到為何要開發minGPT,Karpathy本人在項目文檔里說,他是為了讓GPT做到小巧、簡潔、可解釋且具有教育意義,因為當前大多數可用的GPT工具都有些龐大。
如果原版的GPT是一艘巨型戰艦,那么minGPT就是一艘快艇。小快靈是minGPT的特點,你不能指望它去“打仗”。minGPT的作用是教育目的,讓你熟悉GPT的原理。

現在,minGPT已經能夠進行加法運算和字符級的語言建模,更強大的功能還在進一步開發中。
minGPT項目內容
minGPT實現大約包含300行代碼,包括樣板代碼和完全不必要的自定義因果自注意力模塊。
minGPT的核心庫包含兩個重要的文件:
- mingpt/model.py包含實際的Transformer模型定義
- mingpt/trainer.py是獨立于GPT的訓練模型的PyTorch樣板
為了防止初學者犯難,Karpathy在repo中還隨附3個Jupyter Notebook文件,教你如何使用這個庫來訓練序列模型:
- play_math.ipynb用于訓練專注于加法的GPT(這部分是受GPT-3論文中加法部分的啟發);
- play_char.ipynb用于將GPT訓練為任意文本上的字符級語言模型,類似于作者以前的char-rnn,但它使用的是Transformer而不是RNN;
- play_words.ipynb是一個字節對編碼(BPE)版本,目前尚未完成。
有了這些代碼并不意味著你能立刻復現出OpenAI的幾個GPT預訓練模型。
Karpathy表示,使用BPE編碼器、分布式訓練以及fp16,才可能復現GPT-1/GPT-2的結果,不過他本人還沒有嘗試過。(Karpathy在這句話后面寫著$$$,可能是沒錢吧。)
至于現在最火的GPT-3,可能無法實現,因為Karpathy認為是它不適合GPU顯存,而且需要更精細的模型并行處理。
minGPT的API用法示例如下:
- # you're on your own to define a class that returns individual examples as PyTorch LongTensors
- from torch.utils.data import Dataset
- train_dataset = MyDataset(...)
- test_dataset = MyDataset(...)
- # construct a GPT model
- from mingpt.model import GPT, GPTConfig
- mconf = GPTConfig(vocab_size, block_size, n_layer=12, n_head=12, n_embd=768) # a GPT-1
- model = GPT(mconf)
- # construct a trainer
- from mingpt.trainer import Trainer, TrainerConfig
- tconf = TrainerConfig(max_epochs=10, batch_size=256)
- trainer = Trainer(model, train_dataset, test_dataset, tconf)
- trainer.train()
- # (... enjoy the show for a while... )
- # sample from the model (the [None, ...] and [0] are to push/pop a needed dummy batch dimension)
- from mingpt.utils import sample
- x = torch.tensor([1, 2, 3], dtype=torch.long)[None, ...] # context conditioning
- y = sample(model, x, steps=30, temperature=1.0, sample=True, top_k=5)[0]
- print(y) # our model filled in the integer sequence with 30 additional likely integers
如果你有合適的硬件和數據集,不妨去試試吧。
關于Karpathy
提供minGPT的Andrej Karpathy今天才33歲,但已經是特斯拉的AI高級總監,負責領導自動駕駛神經網絡團隊。

在跳槽到特斯拉之前,他是OpenAI的科學家,主要研究計算機視覺、生成模型和強化學習中的深度學習。
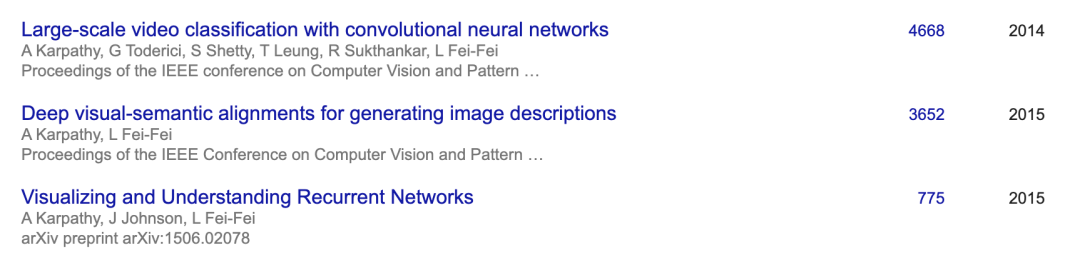
Karpathy在2011-2015年期間進入斯坦福大學攻讀博士學位,他的導師就是李飛飛。讀博期間,他發表的多篇論文都是CV領域的高引文章,還在Google、DeepMind兩家公司實習過。
而且斯坦福大學的著名計算機課程CS231n就是他和李飛飛一起設計的,Karpathy不僅是該課程的助教,也是主講人之一。
無論是當年的CS231n課程還是他的GitHub項目,都有很高的人氣。如此大牛的人物,他寫的GPT代碼你不去看看嗎?
minGPT項目地址:
https://github.com/karpathy/minGPT
Andrej Karpathy個人主頁:
https://karpathy.ai/