五分鐘搞懂布隆過濾器,億級數據過濾算法值得擁有
本文轉載自微信公眾號「會點代碼的大叔」,作者會點代碼的大叔 。轉載本文請聯系會點代碼的大叔公眾號。
在正式講解布隆過濾器之前,先讓我們看看這個業務場景:
Redis 是軟件架構中常用的組件,最常見的用法是將熱點數據緩存到 Redis 中,以減少數據庫的壓力;查詢過程中最常見的用法是:查詢 Redis,如果能查詢到則直接返回,如果 Redis 中不存在則繼續查詢數據庫。
這種方式可以減少數據庫的訪問次數,但是“當緩存中沒有,就查詢數據庫”,在高并發的環境中依然會有風險,比如 90% 的請求數據都不在緩存中,那么這些請求就都會落到數據庫上,這就是緩存穿透。
那么有沒有什么辦法解決這個問題呢?這就可以使用【布隆過濾器】了,它可以確定“某項數據肯定不存在”。
01.布隆過濾器的概念
布隆過濾器是一個叫“布隆”的人提出的,它本身是一個很長的二進制向量(想象成數組)和一系列隨機映射函數(想象成多個 Hash 函數),二進制向量中存放的不是0,就是1(在學習布隆過濾器之前,可以先了解 BitMap 算法,便于理解)。
比如要根據客戶手機號做為條件查詢客戶信息,通常會把手機號碼設置成緩存中的 Key,讓我們設置一個長度為 16 的布隆過濾器。
布隆過濾器初始化都是 0;
對 13800000000 分別進行 hash1()、hash2()、hash3() 運算,得到三個結果 5、9、12,把對應位置設置成 1;
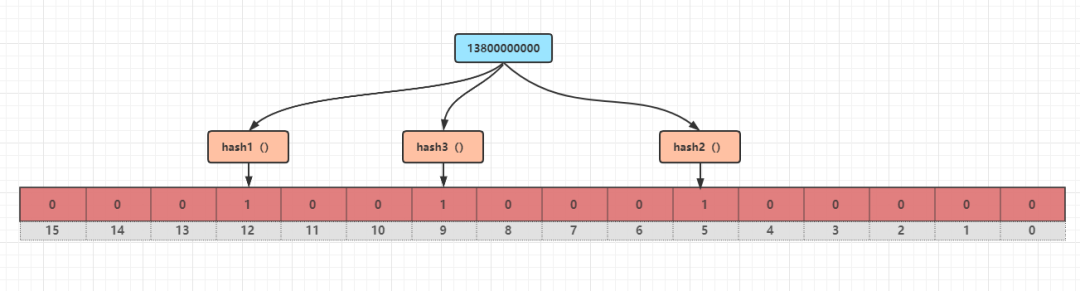
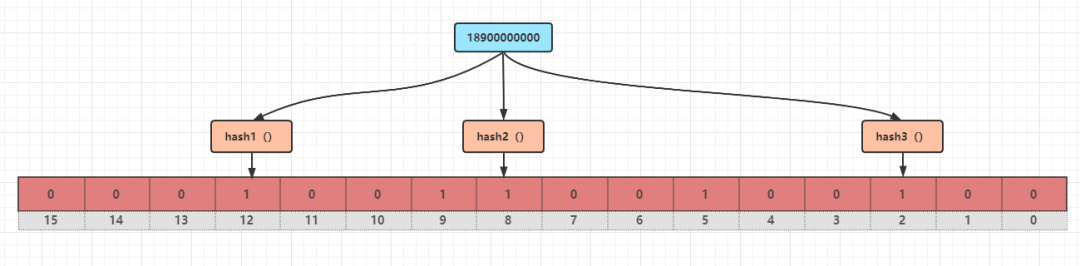
對 18900000000 分別進行 hash1()、hash2()、hash3() 運算,得到三個結果 2、8、12,把對應位置設置成 1,現在 2、5、8、9、12 都是 1,其余元素都是 0;
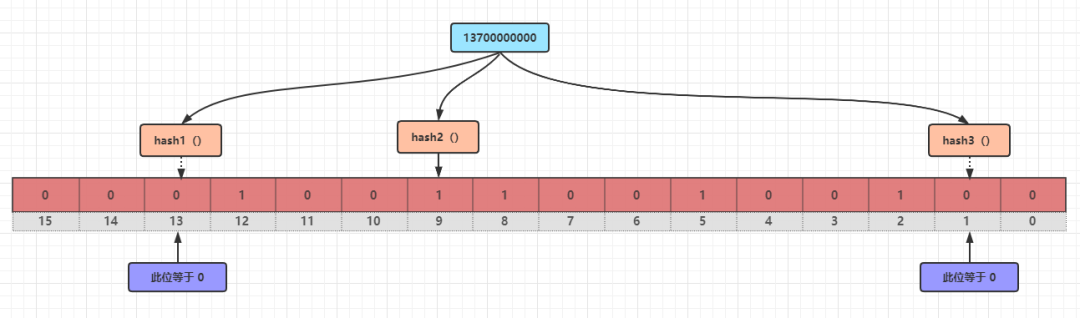
如果我們想要驗證某個電話號碼是否存在,需要怎么做呢?
對 13700000000 分別進行 hash1()、hash2()、hash3() 運算,得到三個結果 1、9、13,然后去判斷第 1、9、13 位上的值是 0 還是 1,如果不全是 1 的話,就說明 13700000000 不在這個布隆過濾器上;這就確定了“某項數據肯定不存在”。
當然我們也可以看出來布隆過濾器有個問題,那就是不能保證數據肯定存在,比如對 18000000000 分別進行 hash1()、hash2()、hash3() 運算,得到的結果是 5、8、9,恰好這三位都是 1,但實際上這條數據并不存在,所以布隆過濾器有一定的誤判率;
而且因為多個數據經過運算后可能會映射到同一個位置(138 和 189 的運算結果都有 12),所以布隆過濾器很難做到刪除,除非要為每一位增加一個計數器,刪除的時候需要給計數器減 1,直到計數器為 0 時,才將布隆過濾器對應位置修改成 0。
02.特點總結
可以確定一個元素肯定不存在,但是不能確定一個元素肯定存在;
二進制向量越長,映射函數越多,誤判率越低;如果提前可以確定誤判率,也可以反推出來布隆過濾器的長度;
可以添加元素,但是不能刪除元素(除非增加計數器);
在存儲空間和插入查詢的時間復雜度都有巨大優勢。
回到本文開頭的那個業務場景,為了防止緩存穿透,可以使用布隆過濾器過濾掉肯定不存在的數據,誤判的請求雖然還是會放到到數據庫,但已經極大地減少了穿透的數量。
03.手寫一個布隆過濾器
Code 不是目的,Coding 的過程是為了加深理解。
首先我們需要定義一個 bitmap,在 JDK 中,已經有對應實現的數據結構類 java.util.BitSet:
- //設置一個布隆過濾器
- private int DEFAULT_SIZE = 1 << 30;
- private BitSet bitset ;
我們還需要一組映射函數,這里可以使用加法 hash 函數,設置 6 個質數,對應 6 個不同的 hash 函數:
- //定義一個質數數組,長度為6,可以生成6個hash函數,用于隨機映射
- private int[] seeds = {3, 7, 13, 31, 37, 61};
- private HashFunction[] functions = new HashFunction[seeds.length];
在構造函數中進行初始化,設置 BitSet 的長度,生成映射函數:
- /**
- * 初始化
- */
- public BloomFilter() {
- bitset = new BitSet(DEFAULT_SIZE);
- for (int i = 0; i < seeds.length; i++) {
- functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
- }
- }
增加元素的時候,對入參進行 6 次 hash 運算,并將結果對應的位置修改成 1(BitSet 對應的位置修改成 true):
- /**
- * 添加一個元素,得到hash運算后的結果,將對應的位置修改成1(true)
- * @param value
- */
- public void add(String value) {
- if (value != null) {
- for (HashFunction f : functions) {
- bitset.set(f.hash(value), true);
- }
- }
- }
判斷元素是否在布隆管理器中,需要對入參進行 6 次 hash 運算,再查看結果對應的位置上是 0 還是 1(true or false),如果其中一位是 0,表示數據肯定不存在,如果都是 1,表示數據(大概率)可能存在。
- /**
- * 判斷元素是否在布隆過濾器中
- * @param value
- * @return
- */
- public boolean contains(String value) {
- if (value == null) {
- return false;
- }
- for (HashFunction f : functions) {
- if(!bitset.get(f.hash(value))){
- //一個位置上不為1(true),就證明不存在,直接返回false
- return false;
- }
- }
- return true;
- }
04.Guava 中的 BloomFilter
已經有很多開源框架幫我們實現了布隆管理器,比如 Google 出品的 Guava 工具庫,其中就有開箱即用的布隆過濾器;
- public class BloomFilterTest {
- public static void main(String[] args){
- int size = 1000000;
- //布隆過濾器
- BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.001);
- for (int i = 0; i < size; i++) {
- bloomFilter.put(i);
- }
- List<Integer> list = new ArrayList<Integer>(1000);
- for (int i = size + 1; i < size + 10000; i++) {
- if (bloomFilter.mightContain(i)) {
- list.add(i);
- }
- }
- System.out.println("誤判數量:" + list.size());
- }
- }