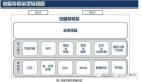
一分鐘搞定Scrapy分布式爬蟲、隊列和布隆過濾器
使用Scrapy開發一個分布式爬蟲?你知道最快的方法是什么嗎?一分鐘真的能 開發好或者修改出 一個分布式爬蟲嗎?
話不多說,先讓我們看看怎么實踐,再詳細聊聊細節。
快速上手
Step 0:
首先安裝 Scrapy-Distributed :
- pip install scrapy-distributed
如果你沒有所需要的運行條件,你可以啟動兩個 Docker 鏡像進行測試 (RabbitMQ 和 RedisBloom):
- # pull and run a RabbitMQ container.
- docker run -d --name rabbitmq -p 0.0.0.0:15672:15672 -p 0.0.0.0:5672:5672 rabbitmq:3
- # pull and run a RedisBloom container.
- docker run -d --name redis-redisbloom -p 0.0.0.0:6379:6379 redislabs/rebloom:latest
Step 1 (非必須):
如果你有一個現成的爬蟲,可以跳過這個 Step,直接到 Step 2。
創建一個爬蟲工程,我這里以一個 sitemap 爬蟲為例:
- scrapy startproject simple_example
然后修改 spiders 文件夾下的爬蟲程序文件:
- from scrapy_distributed.spiders.sitemap import SitemapSpider
- from scrapy_distributed.queues.amqp import QueueConfig
- from scrapy_distributed.dupefilters.redis_bloom import RedisBloomConfig
- class MySpider(SitemapSpider):
- name = "example"
- sitemap_urls = ["http://www.people.com.cn/robots.txt"]
- queue_conf: QueueConfigQueueConfig = QueueConfig(
- name="example", durable=True, arguments={"x-queue-mode": "lazy", "x-max-priority": 255}
- )
- redis_bloom_conf: RedisBloomConfigRedisBloomConfig = RedisBloomConfig(key="example:dupefilter")
- def parse(self, response):
- self.logger.info(f"parse response, url: {response.url}")
Step 2:
只需要修改配置文件 settings.py 下的SCHEDULER, DUPEFILTER_CLASS 并且添加 RabbitMQ和 Redis 的相關配置,你就可以馬上獲得一個分布式爬蟲,Scrapy-Distributed 會幫你初始化一個默認配置的 RabbitMQ 隊列和一個默認配置的 RedisBloom 布隆過濾器。
- # 同時集成 RabbitMQ 和 RedisBloom 的 Scheduler
- # 如果僅使用 RabbitMQ 的 Scheduler,這里可以填 scrapy_distributed.schedulers.amqp.RabbitScheduler
- SCHEDULER = "scrapy_distributed.schedulers.DistributedScheduler"
- SCHEDULER_QUEUE_CLASS = "scrapy_distributed.queues.amqp.RabbitQueue"
- RABBITMQ_CONNECTION_PARAMETERS = "amqp://guest:guest@localhost:5672/example/?heartbeat=0"
- DUPEFILTER_CLASS = "scrapy_distributed.dupefilters.redis_bloom.RedisBloomDupeFilter"
- BLOOM_DUPEFILTER_REDIS_URL = "redis://:@localhost:6379/0"
- BLOOM_DUPEFILTER_REDIS_HOST = "localhost"
- BLOOM_DUPEFILTER_REDIS_PORT = 6379
- # Redis Bloom 的客戶端配置,復制即可
- REDIS_BLOOM_PARAMS = {
- "redis_cls": "redisbloom.client.Client"
- }
- # 布隆過濾器誤判率配置,不寫配置的情況下默認為 0.001
- BLOOM_DUPEFILTER_ERROR_RATE = 0.001
- # 布隆過濾器容量配置,不寫配置的情況下默認為 100_0000
- BLOOM_DUPEFILTER_CAPACITY = 100_0000
你也可以給你的 Spider 類,增加兩個類屬性,來初始化你的 RabbitMQ 隊列或 RedisBloom 布隆過濾器:
- class MySpider(SitemapSpider):
- ......
- # 通過 arguments 參數,可以配置更多參數,這里示例配置了 lazy 模式和優先級最大值
- queue_conf: QueueConfigQueueConfig = QueueConfig(
- name="example", durable=True, arguments={"x-queue-mode": "lazy", "x-max-priority": 255}
- )
- # 通過 key,error_rate,capacity 分別配置布隆過濾器的redis key,誤判率,和容量
- redis_bloom_conf: RedisBloomConfigRedisBloomConfig = RedisBloomConfig(key="example:dupefilter", error_rate=0.001, capacity=100_0000)
- ......
Step 3:
- scrapy crawl example
檢查一下你的 RabbitMQ 隊列 和 RedisBloom 過濾器,是不是已經正常運行了?
可以看到,Scrapy-Distributed 的加持下,我們只需要修改配置文件,就可以將普通爬蟲修改成支持 RabbitMQ 隊列 和 RedisBloom 布隆過濾器的分布式爬蟲。在擁有 RabbitMQ 和 RedisBloom 環境的情況下,修改配置的時間也就一分鐘。
關于Scrapy-Distributed
目前 Scrapy-Distributed 主要參考了Scrapy-Redis 和 scrapy-rabbitmq 這兩個庫。
如果你有過 Scrapy 的相關經驗,可能會知道 Scrapy-Redis 這個庫,可以很快速的做分布式爬蟲,如果你嘗試過使用 RabbitMQ 作為爬蟲的任務隊列,你可能還見到過 scrapy-rabbitmq 這個項目。誠然 Scrapy-Redis 已經很方便了,scrapy-rabbitmq 也能實現 RabbitMQ 作為任務隊列,但是他們存在一些缺陷,我這里簡單提出幾個問題。
- Scrapy-Redis 使用 Redis 的 set 去重,鏈接數量越大占用的內存就越大,不適合任務數量大的分布式爬蟲。
- Scrapy-Redis 使用 Redis 的 list 作為隊列,很多場景會有任務積壓,會導致內存資源消耗過快,比如我們爬取網站 sitemap 時,鏈接入隊的速度遠遠大于出隊。
- scrapy-rabbitmq 等 RabbitMQ 的 Scrapy 組件,在創建隊列方面,沒有提供 RabbitMQ 支持的各種參數,無法控制隊列的持久化等參數。
- scrapy-rabbitmq 等 rabbitmq 框架的 Scheduler 暫未支持分布式的 dupefilter ,需要使用者自行開發或接入相關組件。
- Scrapy-Redis 和 scrapy-rabbitmq 等框架都是侵入式的,如果需要用這些框架開發分布式的爬蟲,需要我們修改自己的爬蟲代碼,通過繼承框架的 Spider 類,才能實現分布式功能。
于是,Scrapy-Distributed 框架就在這個時候誕生了,在非侵入式設計下,你只需要通過修改 settings.py 下的配置,框架就可以根據默認配置將你的爬蟲分布式化。
為了解決Scrapy-Redis 和 scrapy-rabbitmq 存在的一些痛點,Scrapy-Distributed 做了下面幾件事:
- 采用了 RedisBloom 的布隆過濾器,內存占用更少。
- 支持了 RabbitMQ 隊列聲明的所有參數配置,可以讓 RabbitMQ 隊列支持 lazy-mode 模式,將減少內存占用。
- RabbitMQ 的隊列聲明更加靈活,不同爬蟲可以使用相同隊列配置,也可以使用不同的隊列配置。
- Scheduler 的設計上支持多個組件的搭配組合,可以單獨使用 RedisBloom 的DupeFilter,也可以單獨使用 RabbitMQ 的 Scheduler 模塊。
- 實現了 Scrapy 分布式化的非侵入式設計,只需要修改配置,就可以將普通爬蟲分布式化。
目前框架還有很多功能正在添加,感興趣的小伙伴可以持續關注項目倉庫的動向,有什么想法也可以一起討論。