沒有足夠多的數據怎么辦?計算機視覺數據增強方法總結
當沒有足夠多的數據量時該怎么辦?學者們針對這一問題已經研發看各種巧妙的解決方案,以避在深度學習模型中數據少的問題。近來,在做活體檢測和打 Kaggle 比賽過程中查找了很多相關文獻和資料,現整理后與大家分享。一般有以下幾種方法解決的數據量少的問題:
Transfer learning: 其的工作原理是在大型數據集(如 ImageNet)上訓練網絡,然后將這些權重用作新的分類任務中的初始權重。通常,僅復制卷積層中的權重,而不復制包括完全連接的層的整個網絡。這是非常有效的,因為許多圖像數據集共享低級空間特征,而大數據可更好地學習這些特征。
Self/Semi Supervised learning: 傳統上,要么選擇有監督的路線,然后只對帶有標簽的數據進行學習;要么將選擇無監督的路徑并丟棄標簽,以進行 Self Supervised learning,而 Semi Supervised learning 這類方法就是訓練模型的時候,僅需要使用少量標簽和大量未標簽的數據。
Few/One-shot and Zero-shot learning: Few/One-Shot Learning 目的在于從每個類別中的少量樣本/一個樣本中學習有關對象的特征,而 Zero-Shot Learning 的核心目標在于用訓練好的模型對訓練集中沒有出現過的類別進行相應的預測。近些年 Few/One-Shot Learning 和 Zero-Shot Learning 技術發展迅速,模型的性能得到了大幅度的提升。
Regularization technique: 如 dropout、batch normalization 等等正則化方法也能夠緩解數據量過少帶來的過擬合現象。
Data Augmentation: 數據增強是根據已有的數據生成新的數據。與上述技術相反,數據增強從問題的根源(訓練數據集)著手解決問題。使用數據增強方法擴展數據集不僅有助于利用有限的數據,還可以增加訓練集的多樣性,減少過度擬合并提高模型的泛化能力。
在本文中,我們將重點關注 Data Augmentation,因為計算機視覺是當前研究領域中最活躍的領域之一,所以,本文更聚焦于圖像增強,但是其中很多技術技術都可以應用于其他領域。我們把圖像的數據增強分為以下 4 類:
-
Basic Image
-
Geometric Transformations
-
Color Space Transformations
-
RandomRrase/GridMask
-
Mixup/Cutmix
-
Mosaic
-
-
Feature space augmentation
-
MoEx
-
-
GAN-based Data Augmentation
-
NAS
-
AutoAugment
-
Fast AutoAugment
-
DADA
-
-
Other
-
UDA
-
基本圖像處理的擴增
常見的就是對圖像進行幾何變換,圖像翻轉,裁剪,旋轉和平移等等,還可以使用對比度,銳化,白平衡,色彩抖動,隨機色彩處理和許多其他技術來更改圖像的色彩空間。
此外,還可以使用遮擋類的方法,如 CutOut、RandomRrase、GridMask。Cutmix 就是將一部分區域 cut 掉但不填充 0 像素而是隨機填充訓練集中的其他數據的區域像素值,分類結果按一定的比例分配,CutMix 的操作使得模型能夠從一幅圖像上的局部視圖上識別出兩個目標,提高訓練的效率。
而 Mosaic 數據增強方法是 YOLOV4 論文中提出來的,主要思想是將四張圖片進行隨機裁剪,再拼接到一張圖上作為訓練數據,這樣做的好處是豐富了圖片的背景。
基礎的圖形擴增方法在很多深度學習框架中都有實現,例如:torchvision。還有一些更加全面豐富的數據擴增庫,如 albumentations 等等。
特征空間擴增

論文標題: On Feature Normalization and Data Augmentation(MoEx)
論文鏈接: https://arxiv.org/abs/2002.11102
代碼鏈接: https://github.com/Boyiliee/MoEx
在上面的示例中,我們在圖像空間上進行變換,此外,還可以在特征空間中變換。借助神經網絡,我們可以非常有效地以低維或高維的形式表示圖像,這樣,中間的潛在張量包含有關數據集的所有信息,并且可以提取出來做各種事情,包括數據增強。MoEx 這篇文章作者在特征空間進行增強的嘗試。具體做法如下圖所示:
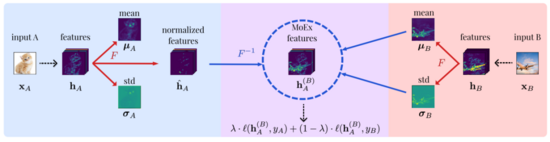
1. 對 hA 做 normalization 的到 hˆA,然后計算 hB 的 µB,σB
2. 接著對 hˆA 反歸一化如下:
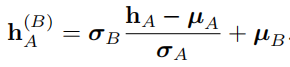
3. 使用新的損失函數計算 loss:
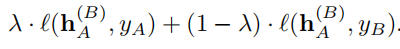
MoEx 的實驗包括:ImageNet、Speech Commands、IWSLT 2014、ModelNet40 等。可以說涵蓋了圖像、NLP、語音三大領域,可見其優點很明顯,由于是在特征空間做數據增強,所以不受輸入數據類型的限制,對于圖像、音頻以及文本等數據具有通用性。
GAN-based Data Augmentation
生成建模是當前最火的技術之一,生成模型學習數據的分布,而不是數據之間的邊界,因此,可以生成全新的圖像。
GAN 由兩個網絡組成:生成器和鑒別器。生成器的工作是生成僅具有噪聲作為輸入的偽造數據。鑒別器接收真實圖像和偽圖像(由發生器產生)作為輸入,并學會識別圖像是偽圖像還是真實圖像。
隨著兩個網絡相互競爭,在對抗訓練的過程中,生成器在生成圖像方面變得越來越好,因為其最終目標是欺騙鑒別器,而鑒別器在區分偽造品和真實圖像方面變得越來越好,因為它的目標是不被欺騙,最終生成器生成了令人難以置信的真實偽數據。
需要說明的是,GAN 生成的數據是要因地制宜。據說在這篇文章右下角 double click 的同學會有奇效(哈哈)。

論文標題: Emotion classification with data augmentation using generative adversarial networks.
論文鏈接: https://arxiv.org/abs/1711.00648

本文在情緒識別驗證了 GAN 做數據擴增的有效性。情緒識別數據集 FER2013 包含了7種不同的情緒:憤怒,厭惡,恐懼,快樂,悲傷,驚奇和中立。,這些類是不平衡的。而本文使用 CycleGAN 將其他幾類的圖像轉換為少數類的樣本,使得模型準確性提高了 5-10%。

論文標題:Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro
論文鏈接:https://arxiv.org/abs/1701.07717
代碼鏈接:https://github.com/layumi/Person-reID_GAN
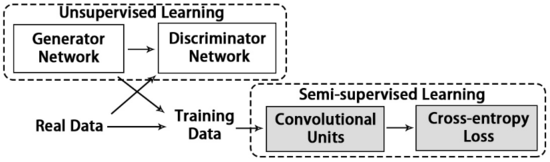
這篇文章想法在當時情況下還是比較好的。沒有 ReID 的 GAN,那就用原始數據訓練一個 GAN,然后生成圖片,沒有標簽就用 ReID 網絡生成 pseudo label。這樣一來,就從監督學習轉化為了半監督學習。
NAS-based Data Augmentation
數據增強方法在各個領域都得到了廣泛應用,不過即使在一些特定的數據集已經找到了適合的數據增強方法,但這些方法通常也不能有效地轉移到其他數據集上去。
例如,由于不同數據集中存在不同的對稱性要求,在 CIFAR-10 數據集上訓練階段水平翻轉圖像是的有效數據增強方法,但對 MNIST 卻不適用。因而, 讓網絡自主的尋找數據增強方法逐漸成為一種無論是學術或者工程上都不可或缺的需求。
Google DeepMind 率先提出了利用 NAS 的方法 AutoAugment,在數據增強的策略搜索空間中利用數據集上評定特定策略的質量,自動搜索出合適的數據增強的策略。相關的文獻還有:Fast AutoAugment 以 及 DADA 等等。

論文標題:
AutoAugment: Searching for best Augmentation policies Directly on the Dataset of Interest
論文鏈接:
https://arxiv.org/abs/1805.09501
代碼鏈接:
https://github.com/tensorflow/models/tree/master/research/autoaugment
AutoAugment 是 Google 提出的自動選擇最優數據增強方案的研究,它的基本思路是使用強化學習從數據本身尋找最佳圖像變換策略,對于不同的任務學習不同的增強方法。流程如下:
AutoAugment 的控制器決定當前哪個增強策略看起來最好,并通過在特定數據集的一個子集上運行子實驗來測試該策略的泛化能力。在子實驗完成后,采用策略梯度法 (Proximal policy Optimization algorithm, PPO),以驗證集的準確度作為更新信號對控制器進行更新。
總的來說,控制器擁有 30 個 softmax 來分別預測 5 個子策略的決策,每個子策略又具有 2 個操作,而每個操作又需要操作類型,幅度和概率。
而數據增強操作的搜索空間一共有 16 個:ShearX/Y,TranslateX/Y,Rotate,AutoContrast,Invert,Equalize,Solarize,Posterize,Contrast,Color,Brightness,Sharpness,Cutout,Sample Pairing。
在實驗中發現 AutoAugment 學習到的已有數據增強的組合策略,對于門牌數字識別等任務,研究表明剪切和平移等幾何變換能夠獲得最佳效果。而對于 ImageNet 中的圖像分類任務,AutoAugment 學習到了不使用剪切,也不完全反轉顏色,因為這些變換會導致圖像失真。AutoAugment 學習到的是側重于微調顏色和色相分布。
AutoAugment 的方法在很多數據集上達到 state-of-the-art 的水平。在 CIFAR-10 上,實現了僅 1.48% 的錯誤率,比之前 state-of-the-art 的方法又提升了 0.65%;
在 SVHN 上,將 state-of-the-art 的錯誤率從 1.30% 提高到 1.02%;在一些 reduced 數據集上,在不使用任何未標記數據的情況下實現了與半監督方法相當的性能;在 ImageNet 上,實現了前所未有的 83.54% 的精度。
Other
在上面我們介紹了一些對有監督的數據進行數據增強的方法,但是對有監督的數據進行數據增強大多被認為是“蛋糕上的櫻桃”,因為雖然它提供了穩定但是有限的性能提升,下面,將介紹一種半監督技術中的數據增強方法。

論文標題:Unsupervised Data Augmentation for Consistency Training(UDA)
論文鏈接:https://arxiv.org/abs/1904.12848
代碼鏈接:https://github.com/google-research/uda
UDA 訓練過程如下圖所示:
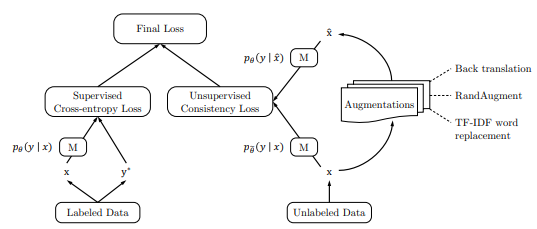
1. 最小化未標記數據和增強未標記數據上預測分布之間的 KL 差異:
其中,x 是原始未標記數據的輸入,x^ 是對未標簽數據進行增強(如:圖像上進行裁剪、旋轉,文本進行反翻譯)后的數據。
2. 為了同時使用有標記的數據和未標記的數據,添加了標記數據的 Supervised Cross-entropy Loss 和(1)中定義的一致性/平滑性目標 Unsupervised Consistency Loss,權重因子 λ 為我們的訓練目標,最終目標的一致性損失函數定義如下:
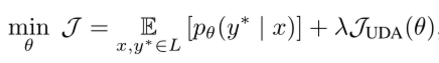
此外,UDA 為了解決未標記的數據和標記數據不平衡導致數據過擬合的問題,提出了新的訓練技巧 Training Signal Annealing 簡稱 TSA,TSA 的思路是隨著模型被訓練到越來越多的未標記數據上,逐漸減少標記數據的訓練信號,而不會過度擬合它們。實驗結果方面,UDA 在很大程度上優于現有的半監督學習方法。
總結
眾所周知,深度學習的模型訓練依賴大量的數據。如果沒有訓練數據,那么即使是優秀的算法也基本上很難發揮作用。本文總結了幾種方法常見的解決的數據量少的問題的方法,并對 Data augment 進行了詳細的總結,希望對您有所幫助。