













用Python講解偏度和峰度
之前筆者在做一個金融數據項目時,有朋友問我,衡量股票收益率有沒有什么好的方法。這個問題讓筆者也思索了好久,其實股票的收益率如果我們從本質來看不就是數據嗎,無非就是收益率我們就想讓其越高越好,也就是讓這個數據增加得越多越好。而衡量數據我們經常用到的方法有均值、方差、偏度和峰度。均值和方差是我們見到和用到最多的方法,甚至在中學課本里都有提及,那么筆者今天就講一下偏度和峰度這兩個大家不太常用的方法,并結合python代碼講一下偏度和峰度在數據分析中的簡單應用。
首先還是介紹一下偏度和峰度的概念。
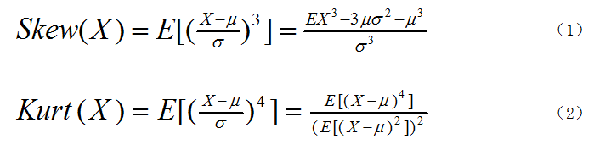
圖1. 偏度和峰度公式
偏度(skewness)又稱偏態、偏態系數,是描述數據分布偏斜方向和程度的度量,其是衡量數據分布非對稱程度的數字特征。對于隨機變量X,其偏度是樣本的三階標準化矩,計算公式如圖1中的式(1)所示。
偏度的衡量是相對于正態分布來說,正態分布的偏度為0。因此我們說,若數據分布是對稱的,偏度為0;若偏度>0,則可認為分布為右偏,也叫正偏,即分布有一條長尾在右;若偏度<0,則可認為分布為左偏,也叫負偏,即分布有一條長尾在左。正偏和負偏如圖2所示,在圖2中,左邊的就是正偏,右邊的是負偏。
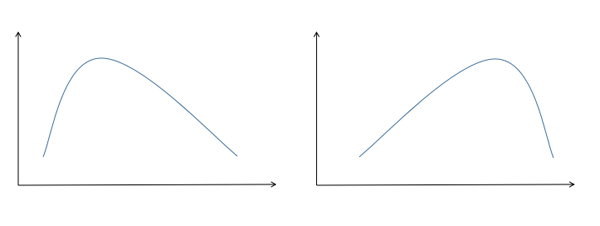
圖2. 偏度的示意圖
而峰度(Kurtosis)則是描述數據分布陡峭或平滑的統計量,通過對峰度的計算,我們能夠判定數據分布相對于正態分布而言是更陡峭還是平緩。對于隨機變量X,其峰度為樣本的四階標準中心矩,計算公式如圖1中的式2所示。
當峰度系數>0,從形態上看,它相比于正態分布要更陡峭或尾部更厚;而峰度系數<0,從形態上看,則它相比于正態分布更平緩或尾部更薄。在實際環境當中,如果一個分部是厚尾的,這個分布往往比正態分布的尾部具有更大的“質量”,即含又更多的極端值。我們常用的幾個分布中,正態分布的峰度為0,均勻分布的峰度為-1.2,指數分布的峰度為6。
峰度的示意圖如圖3所示,其中第一個子圖就是峰度為0的情況,第二個子圖是峰度大于0的情況,第三個則是峰度小于0。
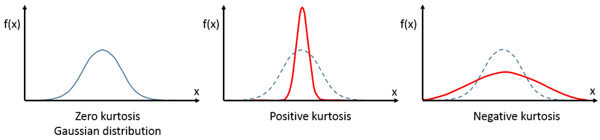
圖3. 峰度的示意圖
在說完基本概念之后,我們就再講一下怎么基于偏度和峰度進行正態性檢驗。這里主要有兩種方法,一是Omnibus檢驗,二是Jarque - Bera檢驗。
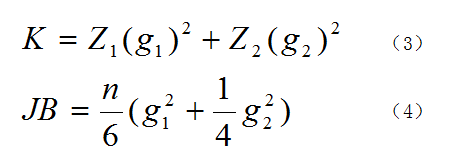
圖4. Omnibus和JB檢驗的公式
Omnibus檢驗的公式如圖4中公式(3)所示,式中Z1和Z2是兩個正態化函數,g1和g2則分別是偏度和峰度,在Z1和Z2的作用下,K的結果就接近于卡方分布,我們就能用卡方分布來檢驗了。這個公式的原理比較復雜,大家如想了解可自行查找相關資料。
Jarque - Bera檢驗的公式如圖4中公式(4)所示,式中n是樣本量,這個結果也是接近于卡方分布,其原理也不在這里贅述。這兩個檢驗都是基于所用數據是正態分布的,即有如下假設。
原假設H0:數據是正態分布的。
備擇假設H1:數據不是正態分布。
下面我們用代碼來說明一下偏度和峰度。
首先看一下數據,這個數據很簡單,只有15行2列。數據描述的是火災事故的損失以及火災發生地與最近消防站的距離,前者單位是千元,后者單位是千米,數據如圖5所示。其中distance指火災發生地與最近消防站的距離,loss指火災事故的損失。

圖5. 數據示例
下面是代碼,首先導入需要的庫。
- import pandas as pd
- import matplotlib.pyplot as plt
- import statsmodels.stats.api as sms
- import statsmodels.formula.api as smf
- from statsmodels.compat import lzip
- from statsmodels.graphics.tsaplots import plot_acf
接下來是讀取數據并作圖,這些代碼都非常簡單,筆者不做過多的解釋。
- file = r'C:\Users\data.xlsx'
- df = pd.read_excel(file)
- fig, ax = plt.subplots(figsize=(8,6))
- plt.ylabel('Loss')
- plt.xlabel('Distance')
- plt.plot(df['distance'], df['loss'], 'bo-', label='loss')
- plt.legend()
- plt.show()
結果如圖6所示,從結果中我們可以看到這些點大致在一條直線上,那么我們就用一元線性回歸來擬合這些數據。
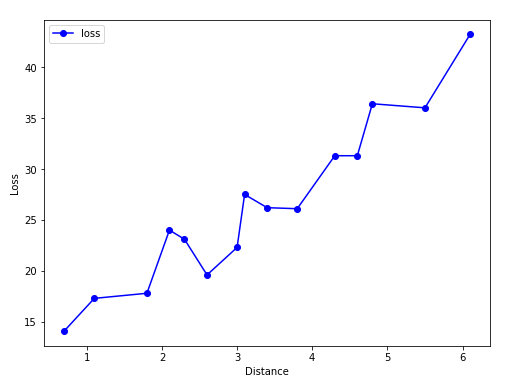
圖6. 數據連線圖
下面是生成模型,并輸出模型的結果。
- expr = 'loss ~ distance'
- results = smf.ols(expr, df).fit() #生成回歸模型
- print(results.summary())
結果如圖7所示。從圖中我們可以看到,Prob (F-statistic)的值為1.25e-08,這個值非常小,說明我們的一元線性回歸模型是正確的,也就是loss和distance的線性關系是顯著的。而圖中還可以看到Skew=-0.003,說明這部分數據非常接近正態分布,而Kurtosis=1.706,說明我們的數據比正態分布更陡峭,是一個尖峰。此外,從圖中還可以看到Omnibus=2.551,Prob(Omnibus)=0.279,Jarque-Bera (JB)=1.047,Prob(JB)=0.592,這里我們很難直接從Omnibus和Jarque-Bera的數值來判斷是否支持前面的備擇假設,但我們可以從Prob(Omnibus)和Prob(JB)這兩個數值來判斷,因為這兩個數值都比較大,那么我們就無法拒絕前面的原假設,即H0是正確的,說明我們的數據是服從正態分布的。
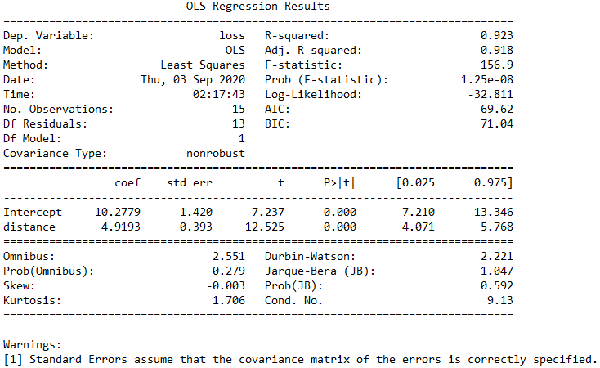
圖7. 模型結果說明
接下來我們再驗證一下Skew、Kurtosis、Omnibus和Jarque-Bera (JB)這些數值,用的是statsmodels自帶的方法。代碼如下。
- omnibus_label = ['Omnibus K-squared test', 'Chi-squared(2) p-value']
- omnibus_test = sms.omni_normtest(results.resid) #omnibus檢驗
- omnibus_results = lzip(omnibus_label, omnibus_test)
- jb_label = ['Jarque-Bera test', 'Chi-squared(2) p-value', 'Skewness', 'Kurtosis']
- jb_test = sms.jarque_bera(results.resid) #jarque_bera檢驗
- jb_results = lzip(jb_label, jb_test)
- print(omnibus_results)
- print(jb_results)
這里omnibus_label和jb_label是兩個list,里面包含了我們所要檢驗的項目名稱,sms.omni_normtest就是statsmodels自帶的omnibus檢驗方法,sms.jarque_bera就是statsmodels自帶的jarque_bera檢驗方法。results.resid是殘差值,一共有15個值,我們的數據本身就只有15個點,這里的每個殘差值就對應前面的每個數據點,sms.omni_normtest和sms.jarque_bera就是通過殘差值來進行檢驗的。而lzip這個方法很少見,其用法和python中原生函數zip差不多,筆者在這里更多地是想讓大家了解statsmodels,所以用了lzip,這里直接用zip也是可以的,至于lzip和zip的區別,留給大家自行去學習。而上面得到的結果如圖8所示。從圖8中可以看到,我們得到的結果和前面圖7中的結果一模一樣。這里用sms.omni_normtest和sms.jarque_bera來進行驗證,主要是對前面圖7中的結果的一個解釋,幫助大家更好地學習statsmodels。
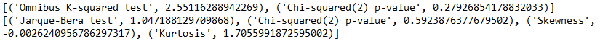
圖8. omnibus和jb檢驗的結果
本文主要通過statsmodels來解釋一下偏度和峰度在數據分析中的一些基本應用,想要更深入了解偏度、峰度以及statsmodels的讀者,可以自行查閱相關資料。














