分布式系統的代碼檢視清單
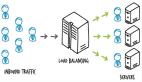
微服務架構是目前在軟件工程界廣泛采用的一種做法。 采用這種體系結構樣式的組織發現自己正在處理分布式故障的增加的復雜性(除了實現業務邏輯的復雜性之外)。
分布式計算的謬論有據可查,但難以發現。 結果,構建大規模,可靠的分布式系統架構是一個難題。 作為必然的結果,當我們向網絡中引入網絡交互的復雜性時,在非分布式系統中看起來不錯的代碼可能會成為一個巨大的問題。
在生產代碼中遇到故障模式數年并根源導致它們進入各種代碼位后,我(和許多其他人一樣)來確定一些更常見的故障模式。 這些在公司和語言堆棧之間略有不同(取決于內部基礎結構和工具的成熟度),但是其中一個或多個通常是導致生產問題的原因。
這是一些代碼檢查指南,它們是我檢查與分布式環境中的系統間通信有關的代碼的基本清單。 并非所有這些方法始終都適用,但是它們都是非常基本的問題,因此我覺得機械地將此列表下標,將缺失的項目標記為進一步的討論很有用且令人放心。 從這個意義上講,這是一個愚蠢的清單,您可能始終希望遵循該清單。
調用遠程系統時,遠程系統出現故障時會發生什么?
無論系統設計了多大的維護,它都會在某些時候失效-這是在生產環境中運行軟件的事實。 它可能由于錯誤,某些基礎結構問題,流量突然激增或忽略的緩慢衰減而失敗,但失敗了。 呼叫者如何處理此故障將確定整個體系結構的彈性和健壯性。
- 定義錯誤處理路徑:在代碼中必須有明確定義的錯誤處理路徑,而不僅僅是讓您的系統在最終用戶面前爆炸。 無論是設計合理的錯誤頁面,具有錯誤度量標準的異常日志,還是具有后備機制的斷路器,都必須明確地處理錯誤。
- 制定恢復計劃:考慮代碼中的每個遠程交互,并弄清楚我們需要做什么來恢復被中斷的工作。 我們的工作流程是否需要保持有狀態,以便從故障點被觸發? 我們是否將所有失敗的有效負載發布到重試隊列/數據庫表,并在遠程系統恢復運行時重試它們? 我們是否有腳本來比較兩個系統的數據庫并以某種方式使其同步? 在部署實際代碼之前,應實施并部署明確的,最好是系統的恢復計劃。
遠程系統變慢時會發生什么?
這比完全失敗更隱患,因為我們不知道遠程系統是否正常工作。 為了處理這種情況,應始終檢查以下內容。
始終在遠程系統調用上設置超時:這包括遠程API調用,事件發布和數據庫調用上的超時。 我在太多的代碼中發現了這個簡單的缺陷,以至于它同時令人震驚,但并非無法預料。 檢查是否為調用中的所有遠程系統設置了有限且合理的超時,以避免由于某種原因遠程系統無響應時在等待中浪費資源。
- 超時重試:網絡和系統不可靠,重試是系統彈性的絕對必要條件。 重試通常會消除系統間交互中的許多"漏洞"。 如果可能,請在重試中使用某種退避(固定的,指數的)。 在重試機制上增加一點抖動可以使呼吸變得有些呼吸。 如果負載很大,則將被調用的系統放置在房間中,可能會提高成功率。 重試的另一面是冪等,我們將在本文后面介紹。
- 使用斷路器:并沒有預包裝此功能的許多實現,但是我看到公司在內部編寫自己的包裝器。 如果您有這種選擇,請一定要練習。 如果您不這樣做,請考慮投資建設它。 有一個定義良好的框架來定義發生錯誤時的后備情況,這是一個很好的先例
- 不要像失敗一樣處理超時-超時不是失敗,而是不確定的情況,應該以支持解決不確定性的方式進行處理。 我們應該建立明確的解決機制,使系統可以在發生超時的情況下保持同步。 范圍從簡單的對帳腳本到有狀態的工作流再到死信隊列等等。
- 以可控制的方式使用批處理:如果要處理大量數據,請進行批處理遠程調用(API調用,數據庫讀取),而不是一對一地進行,以消除網絡開銷。 但是請記住,批處理大小越大,總的延遲就越大,可能失敗的工作單元也就越大。 因此,優化批處理以提高性能和容錯能力。
在構建系統時,其他人將調用
- 所有API都必須是冪等的:這是重試API超時的另一面。 僅當您的API安全重試且不會引起意外副作用時,調用方才可以重試。 API是指同步API和任何消息傳遞接口-客戶端可以發布同一條消息兩次(或者代理可以發送兩次)。
- 明確定義響應時間和吞吐量SLA,并遵循它們進行編碼:在分布式系統中,快速失敗比讓呼叫者等待要好得多。 誠然,吞吐量SLA難以實現(分布式速率限制本身很難解決),但是我們應該認識到我們的SLA,并規定如果要解決這些問題,可以主動使呼叫失敗。 另一個重要的方面是知道下游系統的響應時間,以便您可以確定系統最快的速度。
- 定義和限制批處理API:如果要公開批處理API,則最大批處理大小應由我們希望的SLA明確定義和限制。 這是兌現SLA的必然結果。
- 事先考慮可觀察性:可觀察性意味著能夠分析系統的行為而不必關注系統內部。 事先考慮一下您應該收集有關系統的哪些指標以及應收集哪些數據,這些數據將使您能夠回答以前未提出的問題。 然后對系統進行檢測以獲取此數據。 執行此操作的強大機制是識別系統的域模型并在域中每次發生事件時發布事件(例如,接收到請求ID 123,返回請求123的響應-請注意如何使用這兩個"域"事件 得出稱為"響應時間"的新指標。原始數據>>預先確定的匯總)。
一般準則
- 主動緩存:網絡是多變的,因此請盡可能多地緩存數據,以盡可能接近數據的使用情況。 當然,您的緩存機制也可以是遠程的(例如,在另一臺計算機上運行的Redis服務器),但是至少您可以將數據帶入您的控制域并減少其他系統的負載。
- 考慮故障單位:如果一個API或一條消息代表多個工作單元(批量),那么故障的單位是什么? 整個有效負載應全部失敗一次,還是各個單元可以獨立成功或失敗。 在部分成功的情況下,API是否以成功或失敗代碼響應?
- 在系統邊緣隔離外部域對象:從長遠來看,這是我看到的又一個麻煩。 我們不應該以重用的名義在整個系統中使用其他系統的域對象。 這將我們的系統與另一個系統對實體的建模耦合在一起,并且每次其他系統發生更改時,我們都會進行大量重構。 我們應該始終構建自己的實體表示,并將外部有效負載轉換為該架構,然后在系統內部使用它。
我希望您發現這些準則有助于減少分布式系統代碼中最常見的錯誤。 我想聽聽您是否認為其他一些考慮因素很容易應用但非常有效-我們可以在此處添加它們!