多模態深度學習:用深度學習的方式融合各種信息
使用深度學習融合各種來源的信息。
多模態數據
我們對世界的體驗是多模態的 —— 我們看到物體,聽到聲音,感覺到質地,聞到氣味,嘗到味道。模態是指某件事發生或經歷的方式,當一個研究問題包含多個模態時,它就具有多模態的特征。為了讓人工智能在理解我們周圍的世界方面取得進展,它需要能夠同時解釋這些多模態的信號。
例如,圖像通常與標簽和文本解釋相關聯,文本包含圖像,以更清楚地表達文章的中心思想。不同的模態具有非常不同的統計特性。
多模態深度學習
雖然結合不同的模態或信息類型來提高效果從直觀上看是一項很有吸引力的任務,但在實踐中,如何結合不同的噪聲水平和模態之間的沖突是一個挑戰。此外,模型對預測結果有不同的定量影響。在實踐中最常見的方法是將不同輸入的高級嵌入連接起來,然后應用softmax。
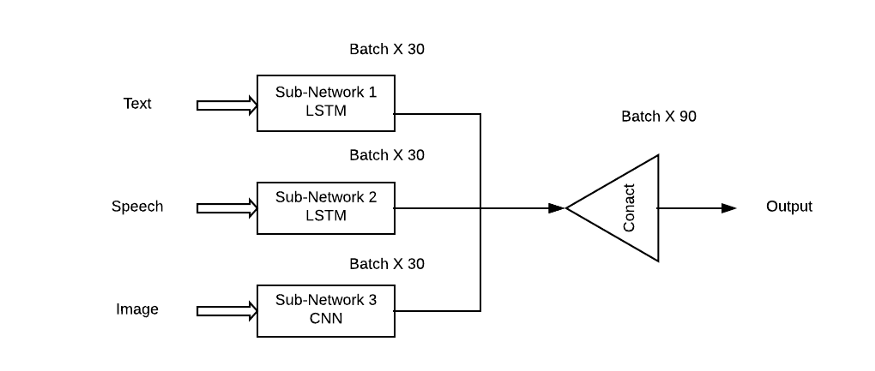
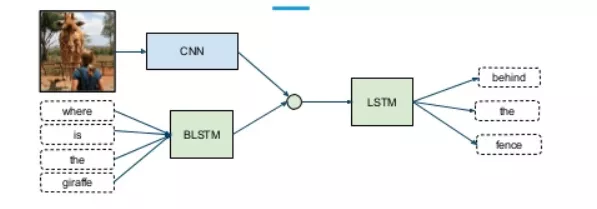
多模態深度學習的例子,其中使用不同類型的神經網絡提取特征
這種方法的問題是,它將給予所有子網絡/模式同等的重要性,這在現實情況中是非常不可能的。
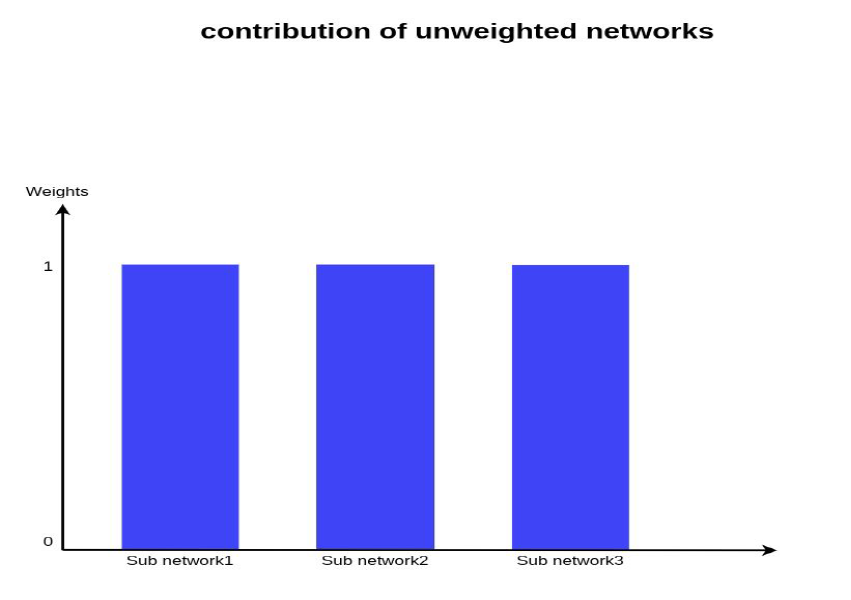
所有的模態對預測都有相同的貢獻
對網絡進行加權組合
我們采用子網絡的加權組合,以便每個輸入模態可以對輸出預測有一個學習貢獻(Theta)。
我們的優化問題變成-
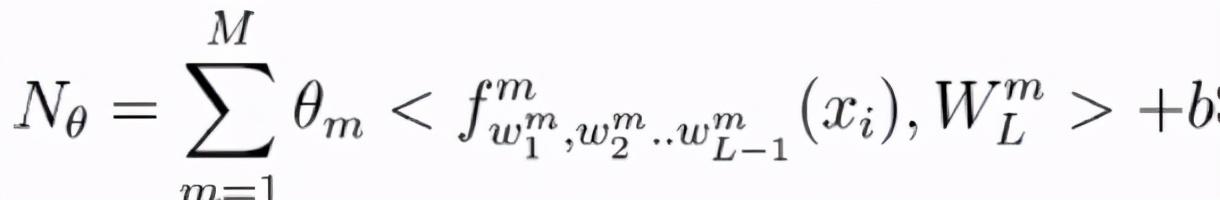
對每個子網絡給出Theta權值后的損失函數。
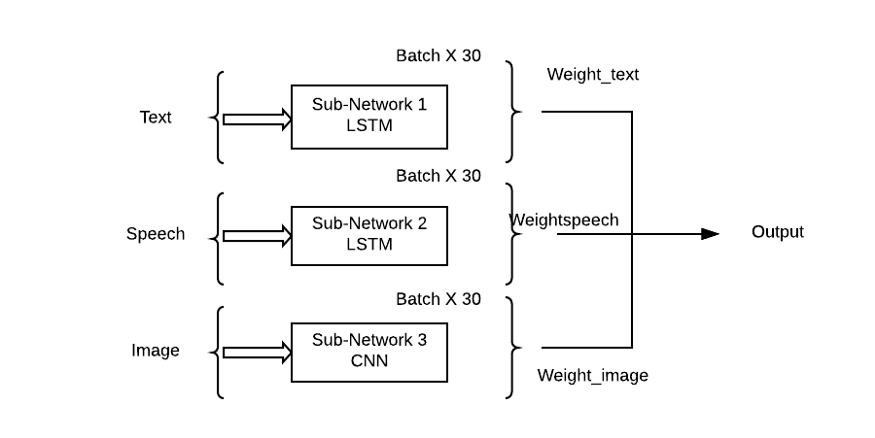
將權值附加到子網后預測輸出。
把所有的都用起來!
準確性和可解釋性
我們在兩個現實多模態數據集上得到了SOTA:
Multimodal Corpus of Sentiment Intensity(MOSI) 數據集 —— 有417個標注過的視頻,每毫秒標注的音頻特征。共有2199個標注數據點,其中情緒強度定義為從strongly negative到strongly positive,線性尺度從- 3到+3。
模態包括:
1、文本
2、音頻
3、語言
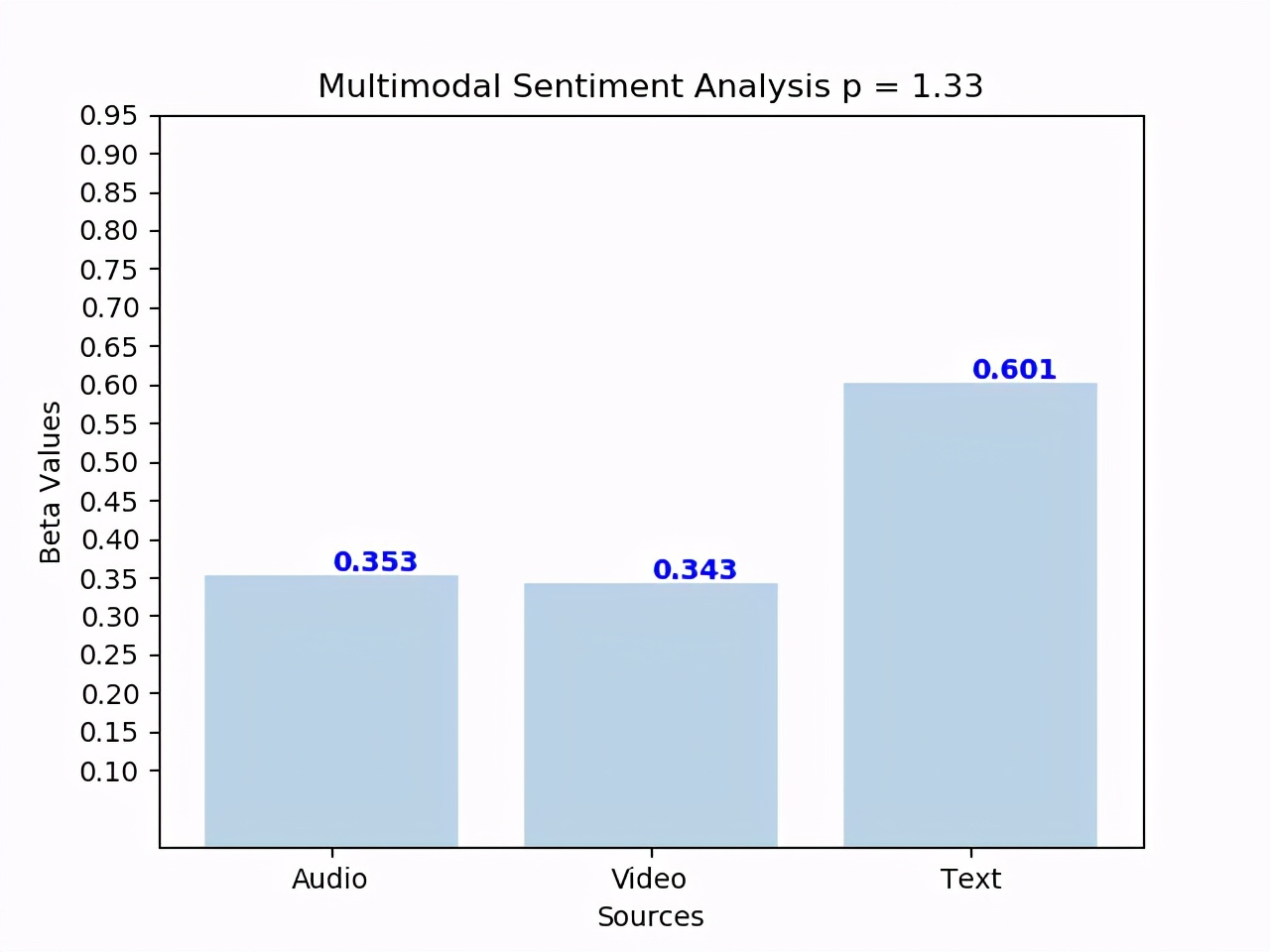
每種模態對情緒預測的貢獻量
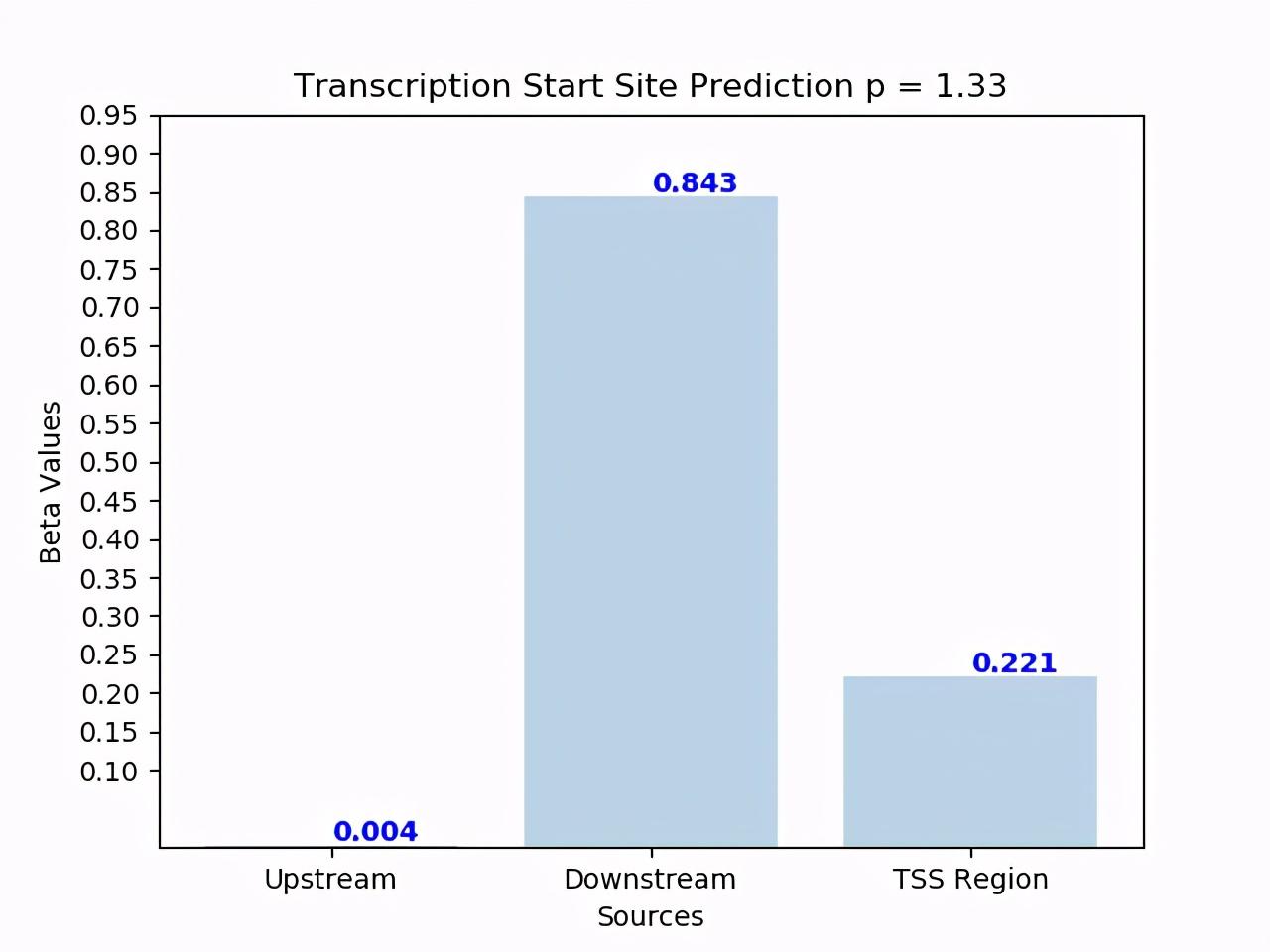
Transcription Start Site Prediction(TSS)數據集 —— Transcription是基因表達的第一步,在這一步中,特定的DNA片段被復制到RNA (mRNA)中。Transcription起始位點是transcription開始的位置。DNA片段的不同部分具有不同的特性,從而影響其存在。我們將TSS分為三個部分:
- 上游DNA
- 下游DNA
- TSS位置
我們取得了前所未有的改善,比之前的最先進的結果3%。使用TATA box的下游DNA區域對這一過程影響最大。