透徹理解深度學習背后的各種思想和思維
深度神經網絡在2012年興起,當時深度學習模型能夠在傳統機器學習問題,例如圖像分類和語音識別,擊敗***進的傳統方法。這要歸功于支撐深度學習的各種哲學思想和各種思維。
抓住主要矛盾,忽略次要矛盾--池化
神經網絡中經過池化后,得到的是突出化的概括性特征。相比使用所有提取得到的特征,不僅具有低得多的維度,同時還可以防止過擬合。
比如max_pooling: 夜晚的地球俯瞰圖,燈光耀眼的穿透性讓人們只注意到最max的部分,產生亮光區域被放大的視覺錯覺。故而 max_pooling 對較抽象一點的特征(如紋理)提取更好。
池化是一種降采樣技術,減少參數數量,也可防止過擬合。如卷積核一樣,在池化層中的每個神經元被連接到上面一層輸出的神經元,只對應一小塊感受野的區域。
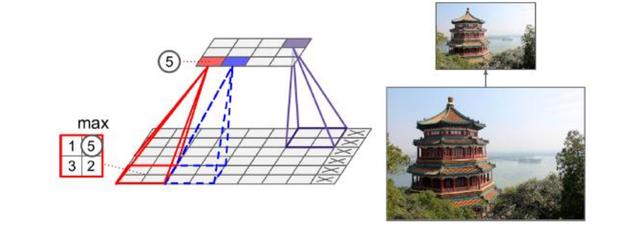
池化體現了“抓住主要矛盾,忽略次要矛盾”哲學思想,在抽取特征的過程中,抓住圖片特征中最關鍵的部分,放棄一些不重要、非決定性的小特征。
避免梯度消失--ReLU和批歸一化
深度神經網絡隨著層數的增多,梯度消失是一個很棘手的問題。
ReLU主要好處是降低梯度彌散可能性和增加稀疏性。
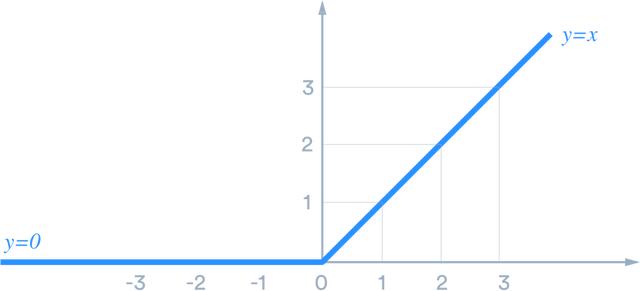
線性整流函數ReLU(Rectified Linear Unit)的定義是h = max(0,a)其中a = Wx + b。
降低梯度消失可能性。特別是當a > 0時,此時梯度具有恒定值。作為對比,隨著x的絕對值增加,sigmoid函數的梯度變得越來越小。ReLU的恒定梯度導致更快的學習。
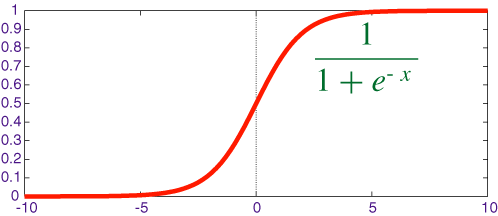
增加稀疏性。當a≤ 0稀疏性出現。網絡層中存在的這樣單元越多,得到越多的表示稀疏性。另一方面,Sigmoid激活函數總是可能產生一些非零值,從而產生密集的表示。稀疏表示比密集表示更有益。
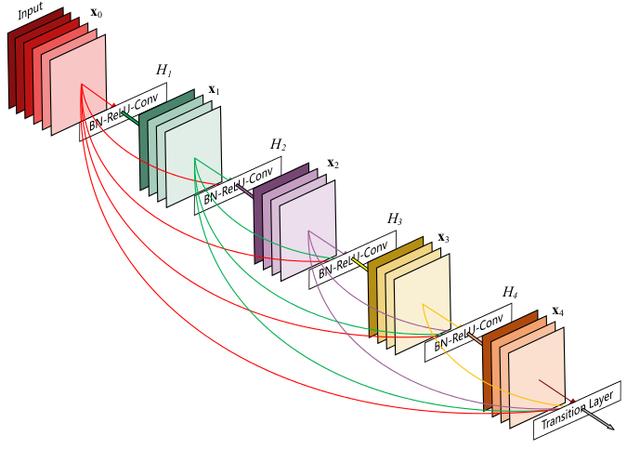
批歸一化BN(Batch Normalization)很好地解決了梯度消失問題,這是由其減均值除方差保證的:
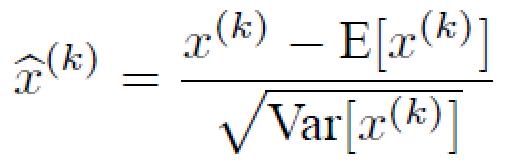
把每一層的輸出均值和方差規范化,將輸出從飽和區拉倒了非飽和區(導數),很好的解決了梯度消失問題。下圖中對于第二層與***層的梯度變化,在沒有使用BN時,sigmoid激活函數梯度消失5倍,使用BN時,梯度只消失33%;在使用BN時,relu激活函數梯度沒有消失。
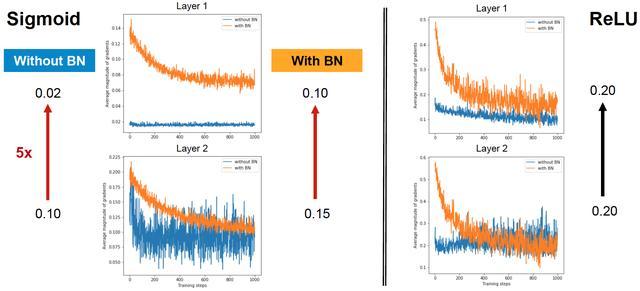
集成學習的思想--Dropout
Dropout是可以避免過擬合的一種正則化技術。
Dropout是一種正則化形式,它限制了網絡在訓練時對數據的適應性,以避免它在學習輸入數據時變得"過于聰明",因此有助于避免過度擬合。
dropout本質上體現了集成學習思想。在集成學習中,我們采用了一些"較弱"的分類器,分別訓練它們。由于每個分類器都經過單獨訓練,因此它學會了數據的不同"方面",并且它們的錯誤也不同。將它們組合起來有助于產生更強的分類器,不容易過度擬合。隨機森林、GBDT是典型的集成算法。
一種集成算法是裝袋(bagging),其中每個成員用輸入數據的不同子集訓練,因此僅學習了整個輸入特征空間的子集。
dropout,可以看作是裝袋的極端版本。在小批量的每個訓練步驟中,dropout程序創建不同的網絡(通過隨機移除一些單元),其像往常一樣使用反向傳播進行訓練。從概念上講,整個過程類似于使用許多不同網絡(每個步驟一個)的集合,每個網絡用單個樣本訓練(即極端裝袋)。
在測試時,使用整個網絡(所有單位)但按比例縮小。在數學上,這近似于整體平均。
顯然這是一種非常好應用于深度學習的集成思想。
深層提取復雜特征的思維
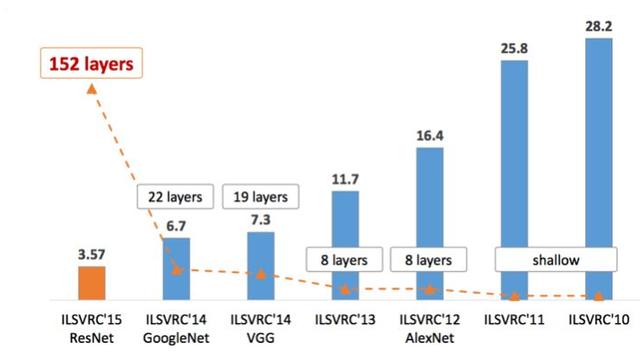
今天深度學習已經取得了非常多的成功。深度神經網絡,由AlexNet的8層到GoogLeNet的22層,再到ResNet的152層,隨著層數的增加,top5錯誤率越來越低,達到3.57%。
由于圖像和文本包含復雜的層次關系,因此在特征提取器中找到表示這些關系的公式并不容易。深度學習系統具有多層表示能力,它能夠讓網絡模擬所有這些復雜的關系。
所以在學習和應用深度學習時,不要懼怕網絡層次之深,正是這種深層結構才提取了圖像、文本、語音等原始數據的抽象的本質特征。
神經網絡構建一個逐步抽象的特征層次結構。
每個后續層充當越來越復雜的特征的過濾器,這些特征結合了前一層的特征。
- 每一層對其輸入應用非線性變換,并在其輸出中提供表示。
- 每一層中的每個神經元都會將信息發送到下一層神經元,下一層神經元會學習更抽象的數據。
所以你上升得越高,你學到的抽象特征就越多。。目標是通過將數據傳遞到多個轉換層,以分層方式學習數據的復雜和抽象表示。感官數據(例如圖像中的像素)被饋送到***層。因此,每層的輸出作為其下一層的輸入提供。
深層次網絡結構所具有的強大的抽象學習和表征能力
拿圖像識別舉例,在***層,是像素這些東西。當我們一層一層往上的時候,慢慢的可能有邊緣,再往上可能有輪廓,甚至對象的部件,等等。總體上,當我們逐漸往上的時候,它確實是不斷在對對象進行抽象。而由現象到本質的抽象過程中,是需要很多階段、很多過程的,需要逐步去粗取精、逐步凸顯,才能最終完成。
層數為什么要那么多?這其中體現了從整體到部分、從具體到抽象的認識論哲學思想。
抽取共同的、本質性的特征,舍棄非本質的特征。這過程本來就是一個逐漸抽象的過程,抽絲剝繭、層層萃取、逐漸清晰、統一匯總,層數少抽取出的特征是模糊的、無法表征的!
非線性思維
每一層進行非線性變換是深度學習算法的基本思想。數據在深層架構中經過的層越多,構造的非線性變換就越復雜。這些變換表示數據,因此深度學習可以被視為表示學習算法的特例,其在深層體系結構中學習具有多個表示級別的數據表示。所實現的最終表示是輸入數據的高度非線性函數。
深層體系結構層中的非線性變換,試圖提取數據中潛在的解釋因素。不能像PCA那樣使用線性變換作為深層結構層中的變換算法,因為線性變換的組合產生另一種線性變換。因此,擁有深層架構是沒有意義的。
例如,通過向深度學習算法提供一些人臉圖像,在***層,它可以學習不同方向的邊緣; 在第二層中,它組成這些邊緣以學習更復雜的特征,如嘴唇,鼻子和眼睛等臉部的不同部分。在第三層中,它組成了這些特征,以學習更復雜的特征,如不同人的面部形狀。這些最終表示可以用作面部識別應用中的特征。
提供該示例是為了簡單地以可理解的方式解釋深度學習算法如何通過組合在分層體系結構中獲取的表示來找到更抽象和復雜的數據表示。
省去特征工程的思維
傳統機器學習中,特征工程作為機器學習技能的一部分。在這種情況下,需要以可以理解的形式將數據轉換并輸入到算法中。然而,在訓練和測試模型之前,并不知道這些特征的用處,數據挖掘人員往往會陷入開發新特征、重建模型、測量結果的繁雜循環中,直到對結果滿意為止。這是一項非常耗時的任務,需要花費大量時間。
穿著黑色襯衫的男人正在彈吉他
這個圖像的下邊的標題是由神經網絡生成的,它與我們想象這個圖片的方式非常相似。對于涉及此類復雜解釋的案例,必須使用深度學習。這背后的主要原因是超參數。標題圖像所需的超參數的數量將非常高,并且在SVM的情況下手動選擇這些超參數幾乎是不可能的。但是深度神經網絡可以通過訓練集和學習來自主地進行。