阿粉教你如何使用爬蟲來對比某東上的數據
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲。轉載本文請聯系Java極客技術公眾號。
自從阿粉經歷過上次的大數據殺熟事件之后,明顯感覺現在的平臺對于用戶非常的不友好呀,只要你高頻的搜索某些關鍵詞的同時,卻往往是越對比,直接就買在了最高峰,就和買股票一樣,每次總感覺能抄底,殊不知買在了天臺。于是阿粉想了個辦法,把所有的數據扒拉下來,我自己做對比,也不去搜索了,省的平臺上總是根據我的搜索內容去進行推薦。
Java如何做爬蟲
大家在想到爬蟲的時候,一定想說,爬蟲,這東西不是學Python的人員才能做的么?我們Java能做呢?阿粉想告訴大家的是,可以,Java語言這么多年,歷時這么久,怎么可能沒有這些內容呢,于是阿粉就開始了學習了 Java 的爬蟲道路。
Jsoup
阿粉在介紹這個類之前,肯定先得說說我們通常看到的內容是由什么組成的,現在比如說我們做開發的都知道,至少我們在電腦端訪問某東,某寶的數據的時候,他們給我們反饋的數據都是通過 HTML 來進行展示的,比如說這個樣子:
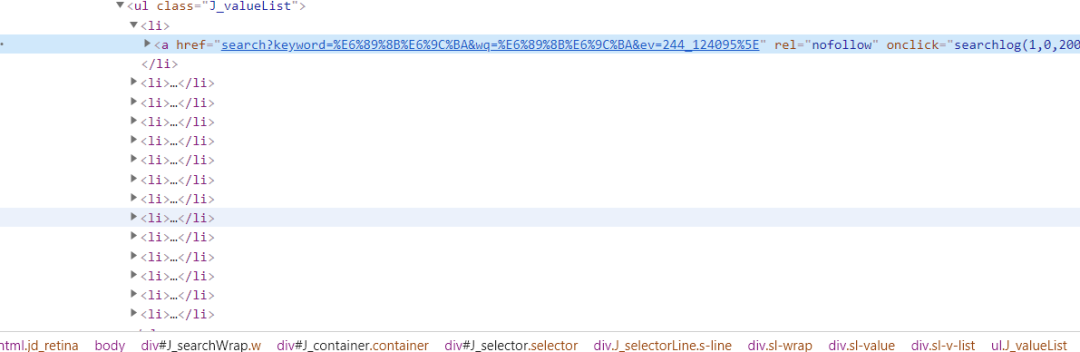
在開發的肯定都是知道,這些都是些什么意思,阿粉在這里我們就不再進行詳細的介紹,說這個 HTML 到底是個啥東西了,阿粉需要介紹的是 Jsoup ,然后告訴大家怎么使用 Jsoup 這個類爬取京東的數據。
正如官方文檔所給我們提示的內容,怎么去解析一段 HTML 代碼 :
- String html = "<html><head><title>First parse</title></head>"
- + "<body><p>Parsed HTML into a doc.</p></body></html>";
- Document doc = Jsoup.parse(html);
而這個 Document是什么呢?我們可以輸出一下看一眼,順帶著看看源碼解釋,畢竟嘛,開發人員不看這個類是干嘛的,就不是個合格的程序員不是,
輸出內容:
- <html>
- <head>
- <title>First parse</title>
- </head>
- <body>
- <p>Parsed HTML into a doc.</p>
- </body>
- </html>
其實可以看出這里,Document實際上是給我們輸出了一個新的文檔,而且是整理之后的,相當于為之后的分析 HTML 做了專業的準備。
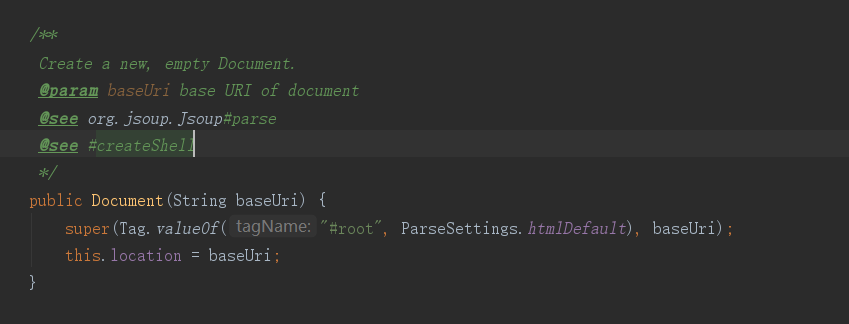
而我們在看源碼的注釋的時候,不難看出,Jsoup不單單是能解析我們給的這個字符串,還可以是一個URL,也可以是一個文件。
它把我們給他的 HTML 字符串轉換成了一個對象,這個對象就是我們上面看到的 Document,然后我們就可以順利成章的去使用 Document 對象里面的元素了。
上面是解析字符串,那我們看下面這個解析 URL 的存在:
- public static void main(String[] args) {
- try {
- Document doc = Jsoup.connect("https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_f38cf584e9fb4328a3e0d2bb515e1458").get();
- String title = doc.title();
- System.out.println(title);
- }catch (IOException e){
- e.printStackTrace();
- }
- }
大家執行以下的話,就一定能夠看到這個 title 到底是什么,而結果是這個樣子的:

和我們在百度搜索的時候是不是不太一樣了,因為這個是進入之后的主頁。
Element
而在我們看源碼的時候,我們能清晰的看到,Document 是繼承了 Element 的類,那么必然可以調用 Element 里面的方法,比如說:
- getElementById(String id); //是不是有點眼熟,像不像Js里面的ID選擇器
- getElementsByTag(String tagName);// 通過標簽來選擇
- getAllElements();//獲取所有的Element的元素
關于方法,阿粉就不再一一的進行敘述了,大家有興趣的可以去看看官方文檔,或者去看看這個源碼,包名送上 package org.jsoup.nodes
有人肯定開始煩了,說阿粉,你就別介紹了,那你說了太多廢話了,趕緊介紹爬京東,好的,這就開始,
我們在爬取之前肯定先分析京東的網址,比如說我搜索硬盤:
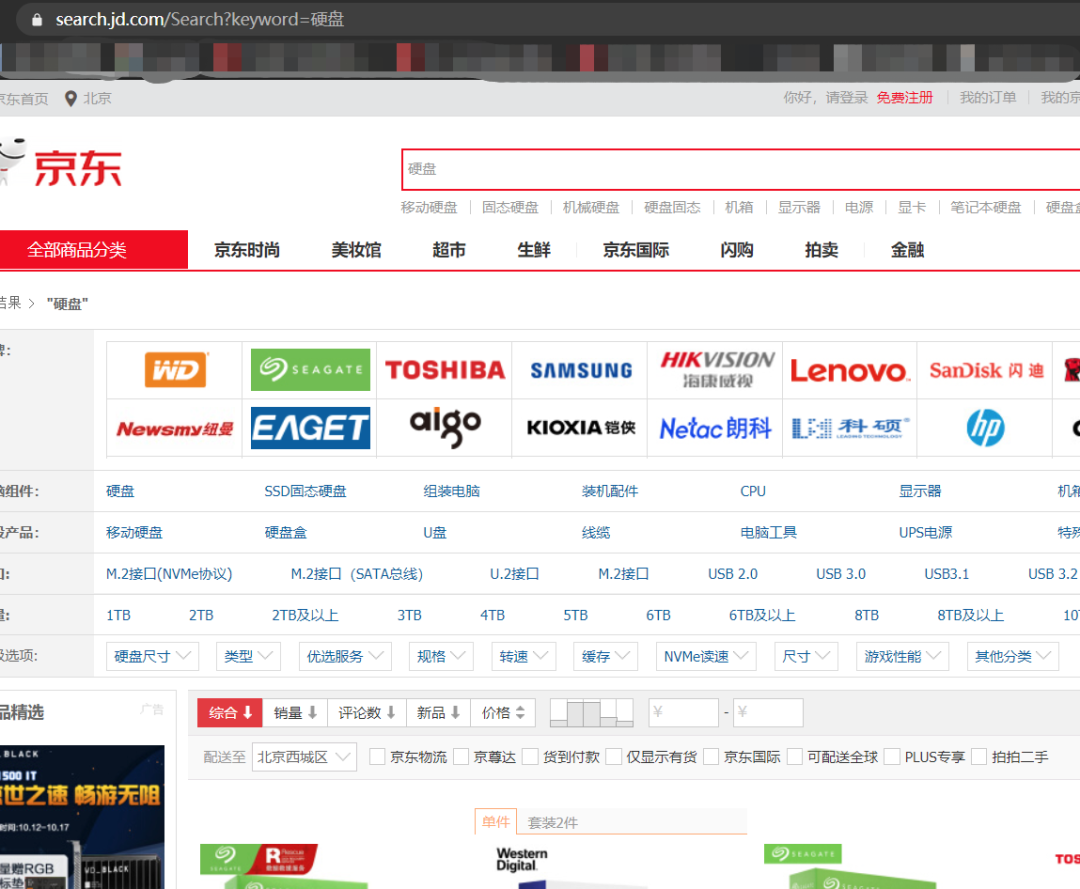
下面就出來了一堆數據,而我們則需要解析的就是在 HTML 種最有用的那一部分,比如:
- <div class="p-price">
- <strong class="J_54994027563" data-done="1">
- <em>¥</em><i>879.00</i>
- </strong>
- </div>
在這里我們就記下了這個價格,然后我們去找我們要的名字

看,p-name就是我們需要的名字,那么我們就可以寫代碼了。
- //這是京東的搜索網址,我們把這個keyword關鍵詞提取出來,注意中英文,中文要處理一下
- String url = "https://search.jd.com/Search?keyword=" + keyword;
- url = url + "&enc=utf-8";
- Document document = Jsoup.parse(new URL(url), 40000);
- //我們先找這個 List,然后一層一層的遍歷
- Element element = document.getElementById("J_goodsList");
- Elements elements = element.getElementsByTag("li");
- for (Element el : elements) {
- String img = el.getElementsByTag("img").eq(0).attr("source-data-lazy-img");
- String price = el.getElementsByClass("p-price").eq(0).text();
- String title = el.getElementsByClass("p-name").eq(0).text();
- String shop = el.getElementsByClass("p-shop").eq(0).text();
- System.out.println("=========================");
- System.out.println("標題:" + title);
- System.out.println("圖片url:" + img);
- System.out.println("店鋪:" + shop);
- System.out.println("價格:" + price);
- }
大家看執行的效果圖:

如果你還有興趣的話,你可以直接在for循環里面新建一個對象,弄一個List集合,然后在最后的的時候,執行一下插入數據庫的方法,這樣是不是就能完整的把數據都保存下來了呢?
寫在最后
為什么阿粉介紹爬取某東,而不去爬取某寶,因為某東是允許你爬取我的數據的,他沒有做任何的反扒機制,而某寶則不行,正是應了那句話
“某東:我賣的是真貨,你說我騙人,我賠給你,某寶:我賣假貨,但是我不承認,你能拿我怎么辦?某多多:親,假一賠十,結果發過來11件假貨,”