手把手教你寫網絡爬蟲(3):開源爬蟲框架對比
作者:佚名
我們從今天開始學習開源爬蟲框架Scrapy,如果你看過《手把手》系列的前兩篇,那么今天的內容就非常容易理解了。Scrapy的靈活性幾乎能夠讓我們完成任何苛刻的抓取需求,它的“難用”也讓我們不知不覺的研究爬蟲技術。
本系列:

| Project | Language | Star | Watch | Fork |
| Nutch | Java | 1111 | 195 | 808 |
| webmagic | Java | 4216 | 618 | 2306 |
| WebCollector | Java | 1222 | 255 | 958 |
| heritrix3 | Java | 773 | 141 | 428 |
| crawler4j | Java | 1831 | 242 | 1136 |
| Pyspider | Python | 8581 | 687 | 2273 |
| Scrapy | Python | 19642 | 1405 | 5261 |
看到了嗎?星星數***的Scrapy比其他所有的加起來都要多,我仿佛聽到他這樣說:






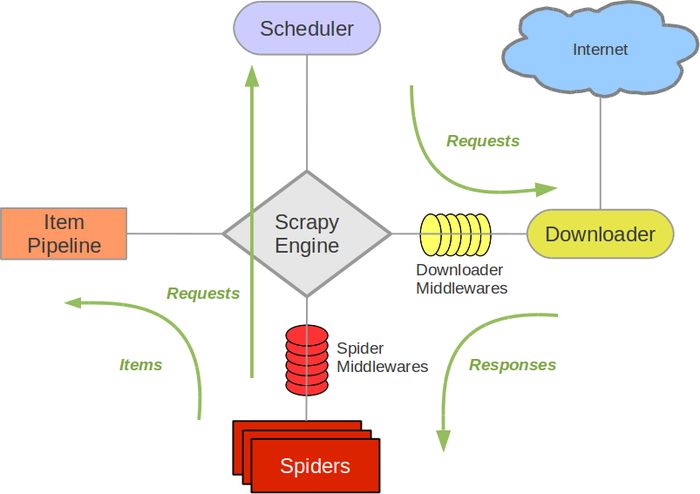
優點:
- 極其靈活的定制化爬取。
- 社區人數多、文檔完善。
- URL去重采用布隆過濾器方案。
- 可以處理不完整的HTML,Scrapy已經提供了selectors(一個在lxml的基礎上提供了更高級的接口),可以高效地處理不完整的HTML代碼。
缺點:
- 不支持分布式部署。
- 原生不支持抓取JavaScript的頁面。
- 全命令行操作,對用戶不友好,需要一定學習周期。
結論
篇幅有限,就先選擇這三個最有代表性的框架進行PK。他們都有遠超別人的優點,比如:Nutch天生的搜索引擎解決方案、Pyspider產品級的WebUI、Scrapy最靈活的定制化爬取。也都各自致命的缺點,比如Scrapy不支持分布式部署,Pyspider不夠靈活,Nutch和搜索綁定。究竟該怎么選擇呢?
我們的目標是做純粹的爬蟲,不是搜索引擎,所以先把Nutch排除掉,剩下人性化的Pyspider和高可定制的Scrapy。Scrapy的靈活性幾乎能夠讓我們完成任何苛刻的抓取需求,它的“難用”也讓我們不知不覺的研究爬蟲技術。現在還不是享受Pyspider的時候,目前的當務之急是打好基礎,應該學習最接近爬蟲本質的框架,了解它的原理,所以把Pyspider也排除掉。
最終,理性的從個人的需求角度對比,還是Scrapy勝出!其實Scrapy還有更多優點:
- HTML, XML源數據選擇及提取的原生支持。
- 提供了一系列在spider之間共享的可復用的過濾器(即 Item Loaders),對智能處理爬取數據提供了內置支持。
- 通過 feed導出 提供了多格式(JSON、CSV、XML),多存儲后端(FTP、S3、本地文件系統)的內置支持。
- 提供了media pipeline,可以 自動下載 爬取到的數據中的圖片(或者其他資源)。
- 高擴展性。您可以通過使用 signals ,設計好的API(中間件, extensions, pipelines)來定制實現您的功能。
- 內置的中間件及擴展為下列功能提供了支持:
- cookies and session 處理
- HTTP 壓縮
- HTTP 認證
- HTTP 緩存
- user-agent模擬
- robots.txt
- 爬取深度限制
- 針對非英語語系中不標準或者錯誤的編碼聲明, 提供了自動檢測以及健壯的編碼支持。
- 支持根據模板生成爬蟲。在加速爬蟲創建的同時,保持在大型項目中的代碼更為一致。
- 針對多爬蟲下性能評估、失敗檢測,提供了可擴展的 狀態收集工具 。
- 提供 交互式shell終端 , 為您測試XPath表達式,編寫和調試爬蟲提供了極大的方便。
- 提供 System service, 簡化在生產環境的部署及運行。
- 內置 Telnet終端 ,通過在Scrapy進程中鉤入Python終端,使您可以查看并且調試爬蟲。
- Logging 為您在爬取過程中捕捉錯誤提供了方便。
- 支持 Sitemaps 爬取。
- 具有緩存的DNS解析器。
下一步
吹了半天的Scrapy,時間也到了,如果大家能夠喜歡上它,學習的效率一定會成倍提升!下次我會為大家帶來滿滿的干貨,并完成更具挑戰性的爬蟲任務,我們下期再見!
原文鏈接:http://www.cnblogs.com/tuohai666/p/8861422.html
責任編輯:龐桂玉
來源:
Python開發者