













漫畫講解Kafka高效的存儲設(shè)計(jì)


在開始講解之前,先帶著大家回憶一下kafka一些名詞概念:
a. Broker:提供數(shù)據(jù)存儲和數(shù)據(jù)讀寫服務(wù)實(shí)例,一個Kafka節(jié)點(diǎn)就是一個broker,多個broker可以組成一個Kafka集群。
b. Topic:代表的是一類消息,例如應(yīng)用日志的topic,應(yīng)用健康監(jiān)控指標(biāo)的topic等。
c. Partition:topic物理上的分組,一個topic可以分為多個partition。
d. Segment:partition物理上由多個segment組成,每個segment是一個文件。
e. offset:每個partition都由一系列有序的、不可變的消息組成,這些消息被連續(xù)的追加到partition中。partition中的每個消息都有一個連續(xù)的序列號叫做offset,用于partition唯一標(biāo)識一條消息.

下面是兩個topic,頁面瀏覽流量日志的topic page_view,和點(diǎn)擊日志 click_log,在kafka數(shù)據(jù)目錄下的分區(qū)存儲情況:
- |--page_view-0
- |--page_view-1
- |--page_view-2
- |--page_view-3
- |--click_log-0
- |--click_log-1
- |--click_log-2
- |--click_log-3

下圖說明了文件的存儲方式:
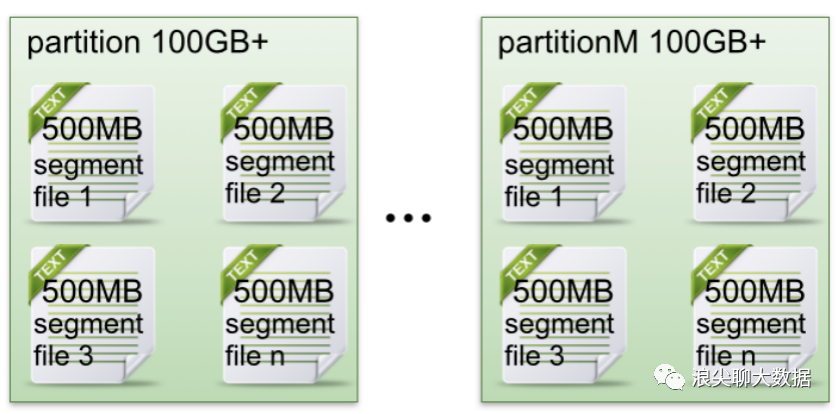
- 每個partion(目錄)相當(dāng)于一個巨型文件被平均分配到多個大小相等segment(段)數(shù)據(jù)文件中。但每個段segment file消息數(shù)量不一定相等,這種特性方便old segment file快速被刪除。
- 每個partiton只需要支持順序讀寫就行了,segment文件生命周期由服務(wù)端配置參數(shù)決定。
這樣做的好處就是能快速刪除無用文件,有效提高磁盤利用率。

partition中segment file組成和物理結(jié)構(gòu),細(xì)節(jié)如下:
- segment file組成:由2大部分組成,分別為index文件和data文件,這兩個文件一一對應(yīng),成對出現(xiàn),后綴”.index”和“.log”分別表示為segment索引文件、數(shù)據(jù)文件.
- segment文件命名規(guī)則:partion全局的第一個segment從0開始,后續(xù)每個segment文件名為上一個segment文件最后一條消息的offset值。數(shù)值最大為64位long大小,19位數(shù)字字符長度,沒有數(shù)字用0填充。
創(chuàng)建一個topicXXX包含1 partition,設(shè)置每個segment大小為500MB,并啟動producer向Kafka broker寫入大量數(shù)據(jù),該partition文件內(nèi)容如下:

圖1

還有一張細(xì)節(jié)的圖,說明一些index文件和log文件的對應(yīng)關(guān)系:
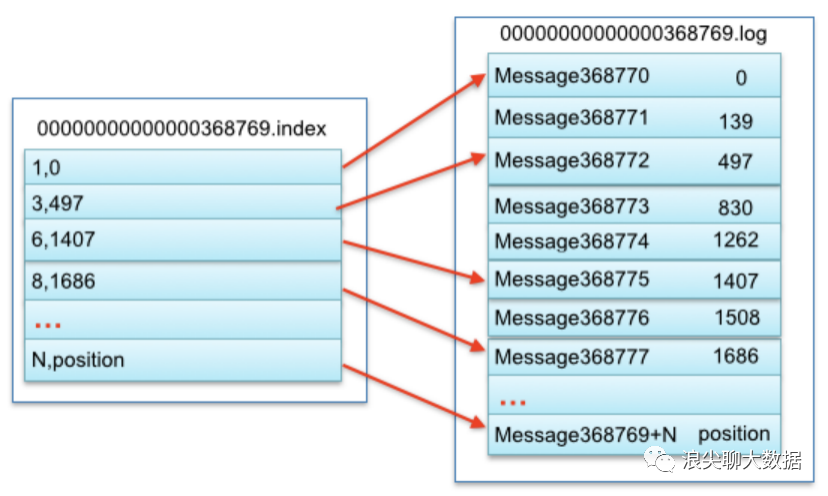
圖2
索引文件存儲大量元數(shù)據(jù),數(shù)據(jù)文件存儲大量消息,索引文件中元數(shù)據(jù)指向?qū)?yīng)數(shù)據(jù)文件中message的物理偏移地址。其中以索引文件中元數(shù)據(jù)3,497為例,依次在數(shù)據(jù)文件中表示第3個message(在全局partiton表示第368772個message)、以及該消息的物理偏移地址為497。

例如讀取offset=368776的message,需要通過下面2個步驟查找。
第一步查找segment file 以前面圖1為例,其中00000000000000000000.index表示最開始的文件,起始偏移量(offset)為0.第二個文件00000000000000368769.index的消息量起始偏移量為368770 = 368769 + 1.同樣,第三個文件00000000000000737337.index的起始偏移量為737338=737337 + 1,其他后續(xù)文件依次類推,以起始偏移量命名并排序這些文件,只要根據(jù)offset **二分查找**文件列表,就可以快速定位到具體文件。當(dāng)offset=368776時(shí)定位到00000000000000368769.index|log
第二步 圖2 ,通過segment file查找message 通過第一步定位到segment file,當(dāng)offset=368776時(shí),依次定位到00000000000000368769.index的元數(shù)據(jù)物理位置和00000000000000368769.log的物理偏移地址,然后再通過00000000000000368769.log順序查找直到offset=368776為止。
這樣做的優(yōu)點(diǎn)很明顯,segment index file采取稀疏索引存儲方式,它減少索引文件大小,通過mmap可以直接內(nèi)存操作,稀疏索引為數(shù)據(jù)文件的每個對應(yīng)message設(shè)置一個元數(shù)據(jù)指針,它比稠密索引節(jié)省了更多的存儲空間,但查找起來需要消耗更多的時(shí)間。

本文轉(zhuǎn)載自微信公眾號「浪尖聊大數(shù)據(jù)」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系浪尖聊大數(shù)據(jù)公眾號。













