













快到起飛的Kafka,是如何設(shè)計(jì)的?
圖片來(lái)自包圖網(wǎng)
消息隊(duì)列主要解決了應(yīng)用耦合、異步處理、流量削鋒等問(wèn)題,當(dāng)前使用較多的消息隊(duì)列有 RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMQ 等。
而部分?jǐn)?shù)據(jù)庫(kù)如 Redis,MySQL 以及 phxsql 也可實(shí)現(xiàn)消息隊(duì)列的功能。
消息隊(duì)列在實(shí)際應(yīng)用場(chǎng)景:
- 應(yīng)用解耦:多應(yīng)用間通過(guò)消息隊(duì)列對(duì)同一消息進(jìn)行處理,避免調(diào)用接口失敗導(dǎo)致整個(gè)過(guò)程失敗。
- 異步處理:多應(yīng)用對(duì)消息隊(duì)列中同一消息進(jìn)行處理,應(yīng)用間并發(fā)處理消息,相比串行處理,減少處理時(shí)間。
- 限流削峰:廣泛應(yīng)用于秒殺或搶購(gòu)活動(dòng)中,避免流量過(guò)大導(dǎo)致應(yīng)用系統(tǒng)掛掉的情況。
今天分享一篇經(jīng)典的 Kafka 設(shè)計(jì)剖析文章給大家,Kafka 作為頂級(jí)消息中間件,據(jù) Confluent 稱,超過(guò)三分之一的財(cái)富 500 強(qiáng)公司使用 Apache Kafka。
Kafka 的性能快,吞吐量大,并且高于其他消息隊(duì)列一個(gè)水平,即使在消息量巨大的情況下還能保持高性能,在互聯(lián)網(wǎng)公司中非常流行,希望大家領(lǐng)悟到 Kafka 設(shè)計(jì)的核心原理。
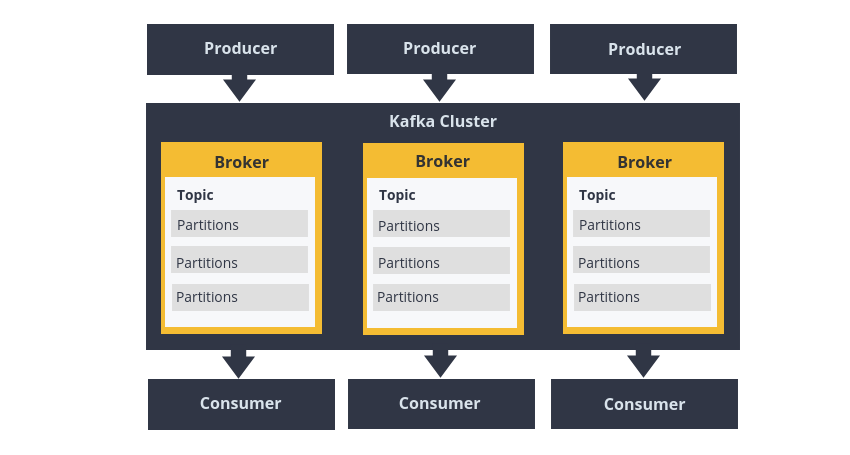
Kafka 架構(gòu)
Kafka 是一個(gè)被精心設(shè)計(jì)的東西,我只能這樣說(shuō)。我這里所謂的精心不是說(shuō)它很完備的實(shí)現(xiàn)了某種規(guī)范。
像個(gè)學(xué)生那般完成了某個(gè)作業(yè),比如 JMS,恰恰相反,Kafka 突破了類似 JMS 這種規(guī)范性的束縛,它是卓越的,乃 yet another JMS。
當(dāng)我用 yet…如此稱呼一個(gè)技術(shù)的時(shí)候,意味著這玩意兒已經(jīng)進(jìn)入了我的視野。好了,現(xiàn)在是 Kafka 和 Storm 時(shí)間,本文先談 Kafka。
Kafka 是什么?
參見(jiàn)官方文檔,它是 Apache 的一個(gè)項(xiàng)目。它是一個(gè)消息隊(duì)列。
消息隊(duì)列若何:消息隊(duì)列是生產(chǎn)者和消費(fèi)者之間的信使,避免了二者之間直接的接觸。
在效果上,它可能和緩存所起的作用一樣,平滑了生產(chǎn)者和消費(fèi)者之間的代謝速率差,但是在其根本目的上,它是為了解除生產(chǎn)者和消費(fèi)者之間的耦合。如果你覺(jué)得有點(diǎn)費(fèi)解,那么簡(jiǎn)單點(diǎn)說(shuō)。
fire and forget,這句話的意思再簡(jiǎn)單點(diǎn)說(shuō),就是真男人從不看爆炸,煙頭往油箱里一丟,把風(fēng)衣的領(lǐng)子一豎,手插褲兜里,徑直走開(kāi),決不不回頭。
消息隊(duì)列,以下簡(jiǎn)稱 MQ,就是造就這種真男人的。它能讓生產(chǎn)者把消息扔進(jìn) MQ 就不管了,然后消費(fèi)者從 MQ 里取消息即可,不用和生產(chǎn)者交互。
下面的篇幅,我將逐步用我的方式演化出 Kafka 的原型,為了掌握整體脈絡(luò),難免會(huì)隱掉很多細(xì)節(jié)。
當(dāng)然這些細(xì)節(jié)可以隨便在其官方文檔以及別人的博客里搜到,我的目的只是希望能整理出一個(gè)脈絡(luò),在設(shè)計(jì)類似的系統(tǒng)的時(shí)候,見(jiàn)招拆招以備參考。
MQ 朝著“正確”方向的演化
Kafka 就一定正確嗎?客觀講,肯定不,但是它是本文的主角,所以它就一定正確。
我們先來(lái)看看作為通用的 MQ,其最簡(jiǎn)單的形式,一般而言,這是大家在首次接觸到 MQ 后的一個(gè)課后作業(yè)。

現(xiàn)在有個(gè)問(wèn)題,如果有兩個(gè)或者多個(gè)消費(fèi)者需要消費(fèi)消息,怎么辦?很簡(jiǎn)單,廣播唄:
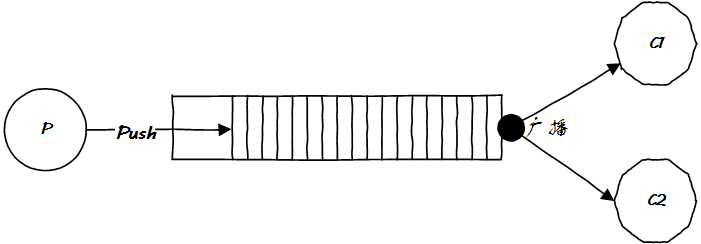
消費(fèi)者是上帝,很難搞的,你推給它們的東西,并不是它們?nèi)慷枷胍模灰徊糠衷趺崔k?
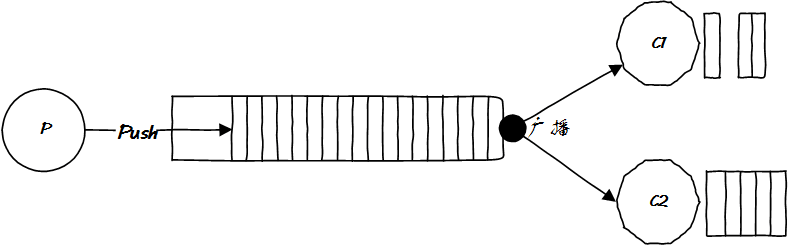
好吧,消費(fèi)者一定在怪 MQ 服務(wù)不周,然而 MQ 有什么錯(cuò),它又不理解消息的語(yǔ)義,面對(duì)百般刁難的消費(fèi)者,它最多只能要求生產(chǎn)者把消息細(xì)分一下,因此就出現(xiàn)了多個(gè) Topic:
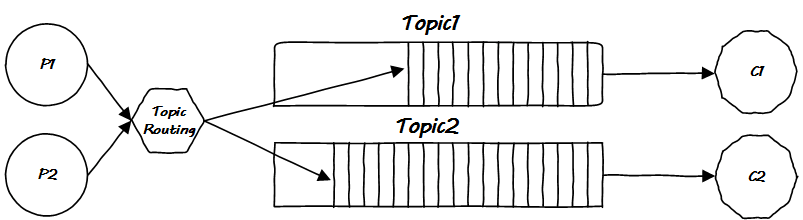
這是很顯然的想法,就是是在消息入隊(duì)處區(qū)分消息的 Topic,然消費(fèi)者從取自己感興趣的消息隊(duì)列取消息即可。
但還是會(huì)潛在的多個(gè)消費(fèi)對(duì)同一 Topic 消息感興趣的情況:
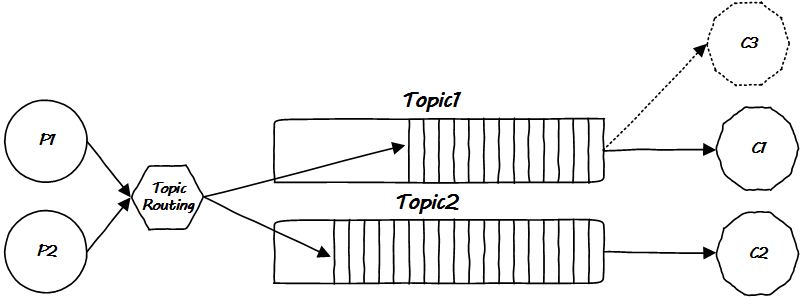
如果采用廣播,那么就仍然會(huì)出現(xiàn)冗余傳播問(wèn)題,如果單播,那么一個(gè)消費(fèi)者取出消息后,這條消息該不該刪除呢?如果刪除了,另一個(gè)消費(fèi)者怎么辦?廣播會(huì)浪費(fèi)帶寬,不廣播也不行…
這貌似進(jìn)入了一個(gè)死循環(huán),必須一勞永逸地從根源解決問(wèn)題才行。顯然的想法是下面的方案(至少我自己設(shè)計(jì)的話就會(huì)這么做):
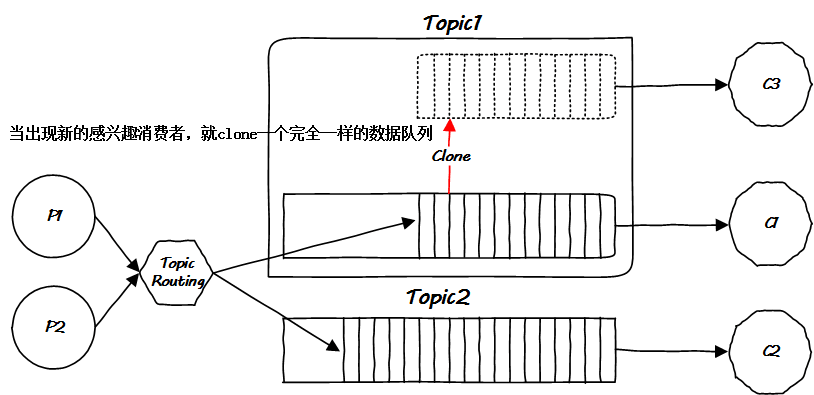
問(wèn)題是解決了,然而我的天啊,仔細(xì)想一下先前的架構(gòu),把簡(jiǎn)圖畫(huà)出來(lái)后,會(huì)發(fā)現(xiàn)事情會(huì)一發(fā)而不可收拾,MQ 本身的邏輯太復(fù)雜了:

回到 UNIX 哲學(xué),遇到新問(wèn)題的時(shí)候,要新編一個(gè)程序,而不是為已有的程序添加一個(gè)功能。
本著這個(gè)思路,為什么不把這件因?yàn)橄M(fèi)者而導(dǎo)致復(fù)雜化的事情完全交給消費(fèi)者呢?
有點(diǎn)往 Kafka 上靠了啊。如果把 MQ 里面的數(shù)據(jù)全部持久化存儲(chǔ),消費(fèi)者不就可以各取所需了嗎?
這是一個(gè)根本的轉(zhuǎn)變,如果以前的方式是限量商務(wù)套餐-套餐強(qiáng)行推給你,不想要的自己扔掉,那么現(xiàn)在的方式就是無(wú)限量自助餐-想要什么自己去拿即可。
消息自取,消息永遠(yuǎn)都在 MQ,消費(fèi)者隨便取,取哪個(gè)消息都行,什么時(shí)候取都行。
消費(fèi)者只需要告訴 MQ 它想要哪個(gè)消息就好,因此需要傳遞一個(gè)消息的 offset 參數(shù):
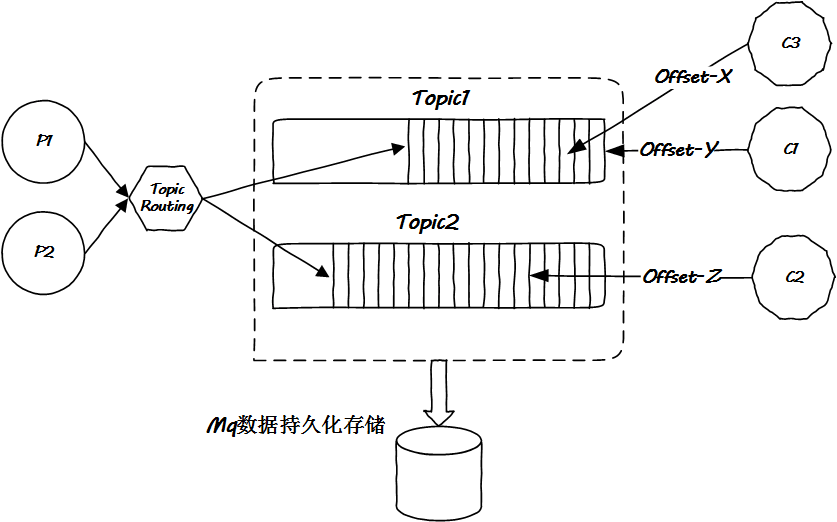
然而自助餐也有打烊的時(shí)候,部分也會(huì)限制就餐時(shí)長(zhǎng),這是 Kafka 策略化存儲(chǔ)的問(wèn)題,詳見(jiàn)文檔。
簡(jiǎn)化一下,現(xiàn)在看下圖:
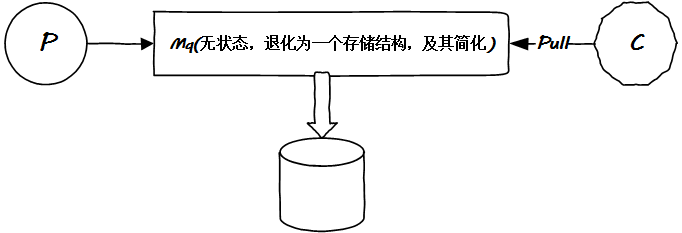
一切 OK 了。嗯,是的,這就是 Kafka 的原始模型。然而 Kafka 遠(yuǎn)不僅此而已。且看下文繼續(xù)演化。
集群化,容錯(cuò)
先看一下現(xiàn)在的情況:
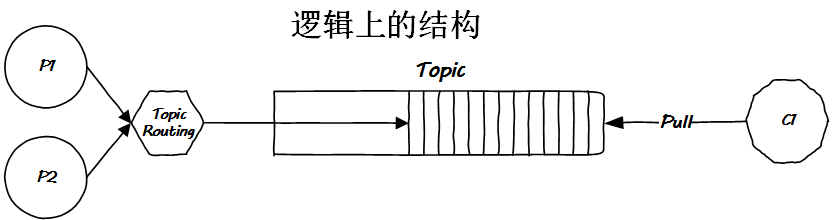
這是在邏輯上一個(gè) Kafka 類似的 MQ 應(yīng)有的結(jié)構(gòu)。但是在物理實(shí)現(xiàn)上,它又如何呢?
常聽(tīng)人說(shuō),Kafka 一開(kāi)始就是為分布式而生的,這話怎么理解呢?我們只需要先理解它如何擴(kuò)容,然后再理解它如何將擴(kuò)容作用于不同的機(jī)器即可。先看擴(kuò)容。
類似高速公路,一般當(dāng)你聽(tīng)到廣深高速的時(shí)候,我們知道這是從廣州到深圳的一條高速公路,這是邏輯上的說(shuō)法,類似到目前為止我們討論的 MQ 的 Topic。
然而這條高速公路到底長(zhǎng)什么樣子,沿途怎么路由,這就是物理實(shí)現(xiàn)了。此外,所有的道路都會(huì)分多個(gè)車(chē)道用于并行。
嚴(yán)格來(lái)講,每一個(gè)車(chē)道都會(huì)被細(xì)分,比如小型車(chē)道,客車(chē)道,大貨車(chē)道,超車(chē)道等等,所有這些車(chē)道上的車(chē)都是到達(dá)同一個(gè)目的地(屬于同一個(gè) Topic),然而它們確實(shí)是細(xì)分的不同種類。
把一個(gè)叫做 partition 的概念類比為車(chē)道,如下圖:
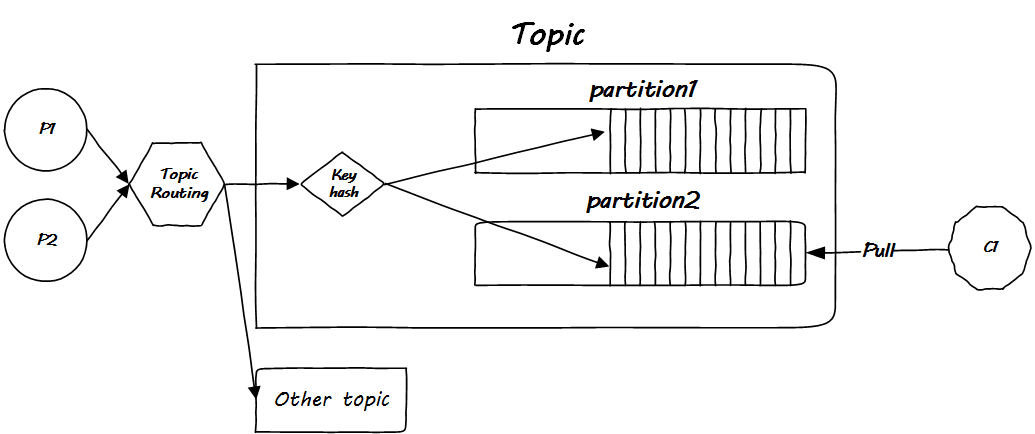
注意這個(gè) key hash 模塊,這里就是區(qū)分車(chē)子要進(jìn)入哪個(gè)車(chē)道的邏輯。在 Kafka 的術(shù)語(yǔ)中,車(chē)道就是 partition,即分區(qū)。
在同一個(gè) Topic 中分發(fā)消息的時(shí)候,你要自己設(shè)計(jì) hash 函數(shù),該 hash 函數(shù)就是一個(gè)分發(fā)策略,決定把消息按序放到哪一個(gè)分區(qū)中去。
溫州皮鞋廠老板說(shuō)類比和舉例不好,但這是技術(shù)散文,不是技術(shù)文檔,多半是給自己看,所以還要類比。
Topic Routing 做的事是決定從哪條高速公路到哪里,而 key hash 則是決定你是坐轎車(chē),客車(chē)還是卡車(chē)過(guò)去。
值得注意的是,Kafka 只保證同一 Topic 內(nèi)同一 partition 內(nèi)消息的有序性,無(wú)法做到全局有序性。
這并不是一個(gè)缺陷,這是兩全不能齊美的。完全的順序就需要串行化,然而串行化就無(wú)法并行,這簡(jiǎn)直就是廢話!
現(xiàn)在,在 Topic 之下,我們又有了一個(gè)新的單位,叫做 partition,這個(gè)叫做 partition 的就是 Kafka 中最基本的部署單位,這一點(diǎn)務(wù)必要記住,它關(guān)乎到如何組織你的集群。
好了,看一下這些 Topic 以及其旗下的 partition 是如何部署在 M1 和 M2 兩臺(tái)機(jī)器上的吧:
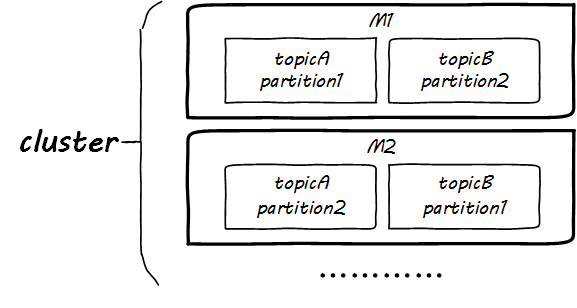
以上是花開(kāi)兩朵,各表一枝,現(xiàn)在該說(shuō)說(shuō)消費(fèi)者了。
消費(fèi)者面對(duì) MQ 本身進(jìn)化到如此細(xì)粒度,該如何應(yīng)對(duì)呢?其實(shí)消費(fèi)者也有橫向擴(kuò)展的需求,如果說(shuō)消費(fèi)者對(duì)應(yīng) partition,那么對(duì)應(yīng) Topic 的就是消費(fèi)者的上級(jí)了。
因此多加了一個(gè)層次,引出消費(fèi)組的概念,解決問(wèn)題:
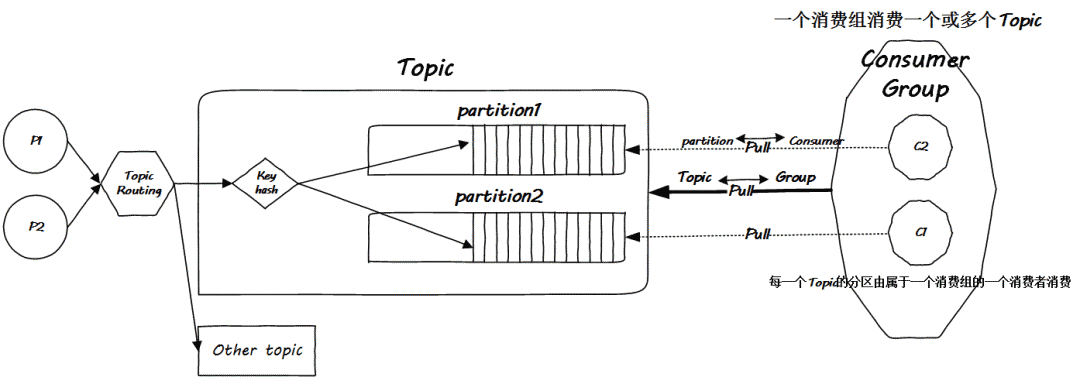
從 CPU cache 到 Kafka,設(shè)計(jì)思路殊途同歸,這就是一個(gè)典型的全方位組相聯(lián)結(jié)構(gòu):
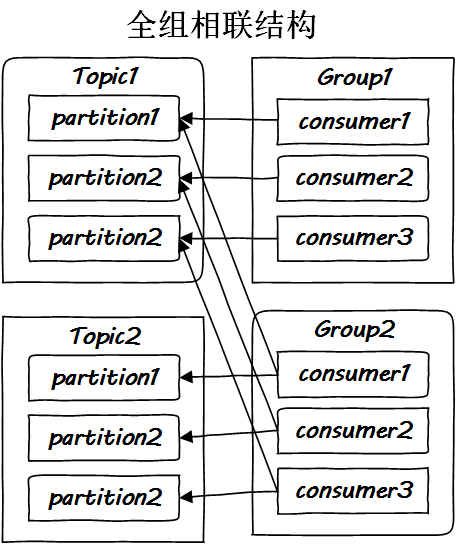
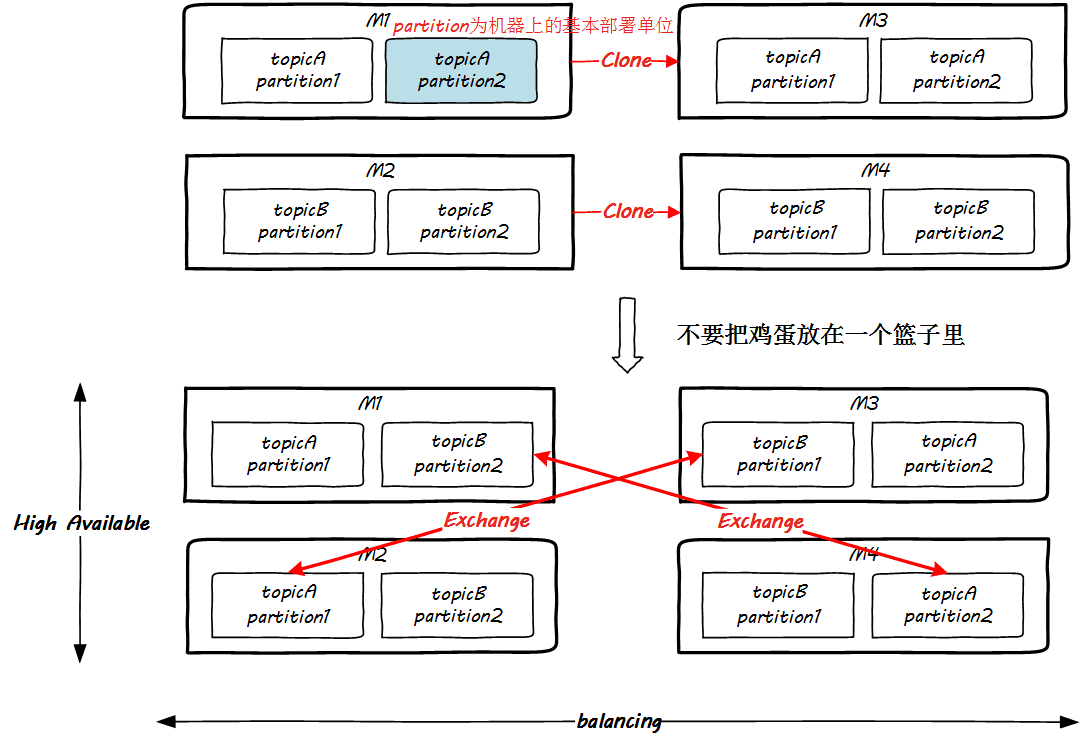
到此為止,全部圖景已經(jīng)完全繪制完畢,是時(shí)候展示集群的部署了。我們知道所謂的 Kafka 集群,就是將各個(gè) Topic 的 partition 部署在不同的機(jī)器上,達(dá)到兩個(gè)目的。
一個(gè)是負(fù)載均衡,即提供訪問(wèn)的并行性,另一個(gè)就是提供高可用性,即做熱備份,這兩個(gè)功能我希望能用一個(gè)圖展示:
總體的一個(gè)結(jié)構(gòu)如下:
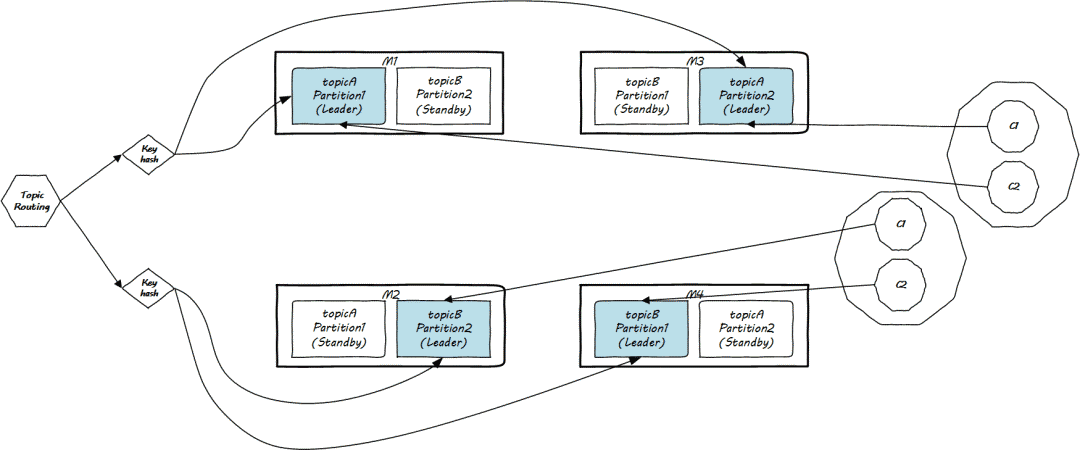
持久化存儲(chǔ)/查詢機(jī)制
上面的兩個(gè)小節(jié),我已經(jīng)展示了 Kafka 是如何一步一步地肚子里面的勾當(dāng)內(nèi)外有別的,雖然我不知道作者怎么去設(shè)計(jì),但如果是我自己,我肯定就是上面這個(gè)思路了…
前面的敘述終究是概覽,不甚過(guò)癮。本節(jié)將給出半點(diǎn)細(xì)節(jié),瑾闡釋一下 Kafka 存儲(chǔ)的半景。
我們知道,Kafka 為了卸載 MQ 本身的復(fù)雜性,為了其真正無(wú)狀態(tài)的設(shè)計(jì),它將狀態(tài)維護(hù)機(jī)制這口鍋完全甩給了消費(fèi)者。
因此取消息的問(wèn)題就轉(zhuǎn)化成了消費(fèi)者拿著一個(gè) offset 索引來(lái) Kafka 存儲(chǔ)器里取消息的問(wèn)題,這就涉及到了性能。But 如何能查的更快?How?
還是先給出一個(gè)最簡(jiǎn)單的場(chǎng)景。假設(shè) Kafka 的每一個(gè) partition 都一個(gè)完整獨(dú)立的文件,那么如果這個(gè)文件非常大,事實(shí)上也確實(shí)非常大(有可能到達(dá) T 級(jí)別甚至 P 級(jí)別…)。
那么在大文件中檢索一個(gè)特定的消息本身就是一個(gè)頭疼的問(wèn)題,并且該文件還在磁盤(pán)中,這更是雪上加霜,我們都知道磁盤(pán)的隨機(jī)讀寫(xiě)是硬傷,順序讀寫(xiě)也好不到哪去,這怎么辦?
遍歷?如果每一個(gè) partition 只是一個(gè)獨(dú)立文件,那么只能遍歷:
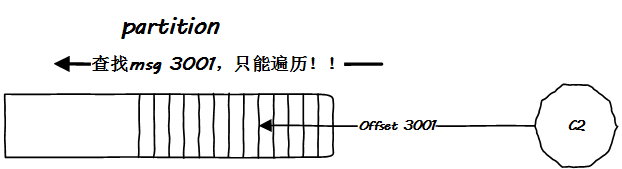
面對(duì)這個(gè)遍歷問(wèn)題,一般的解決方案就是建立索引,并且把索引數(shù)據(jù)常駐內(nèi)存,很多數(shù)據(jù)庫(kù)就是這么干的,Kafka 當(dāng)然也可以這么干。
Kafka 比較帥的一點(diǎn)就是它并不借助任何特殊的文件系統(tǒng),它的數(shù)據(jù)就存在一般的文件中。
然而它把一個(gè) partition 分成了等大小的一系列小文件,因此在物理上,并不存在一個(gè)完整的 partition 文件,partiotion 只是表現(xiàn)為一個(gè)目錄。
我們知道,文件系統(tǒng)管理幾個(gè)等大的文件是非常方便的:
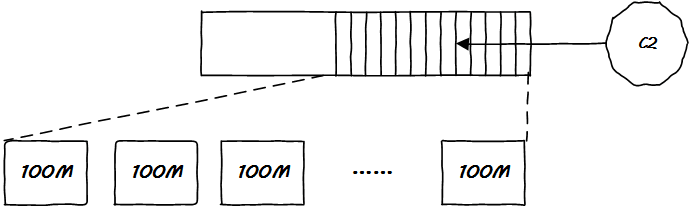
以上的例子中,一個(gè) partiton 被分成了 100M 大小的文件,這種小文件叫做分段。
在 Kafka 存儲(chǔ)的時(shí)候,每一個(gè)段文件存滿為止再開(kāi)辟下一個(gè),由于消息的長(zhǎng)度并不一定統(tǒng)一,因此每一個(gè)小段文件里面包含的消息數(shù)量并不一定一樣多。
但是不管怎樣,抽取每一個(gè)段文件的首尾消息偏移作為元數(shù)據(jù)保存起來(lái)是一件一勞永逸的事情,這便于建立一個(gè)常駐內(nèi)存的索引:
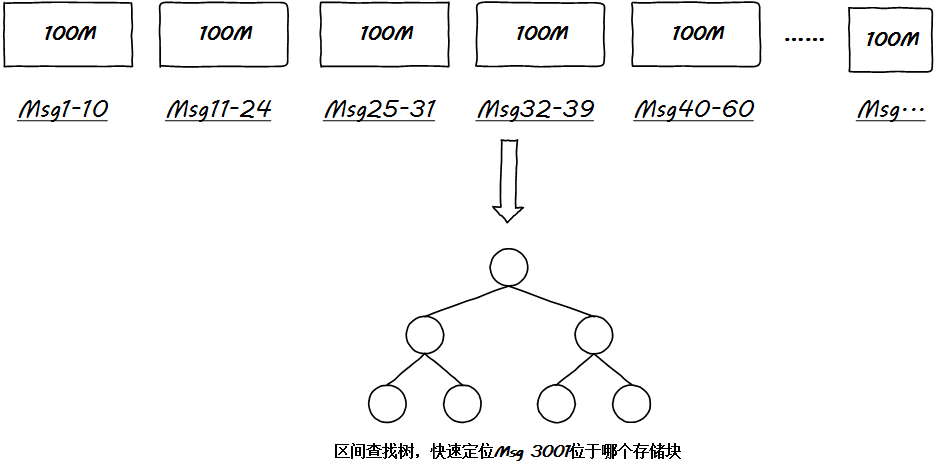
通過(guò)這個(gè)區(qū)間查找樹(shù),很快就能定位到特定的段文件,但是事情并沒(méi)有結(jié)束。
在 Kafka 中,每一個(gè) partition 的段文件,均配帶一個(gè) index 索引文件,這個(gè)文件是做什么的呢?它是段文件內(nèi)部消息的稀疏索引,見(jiàn)下圖:
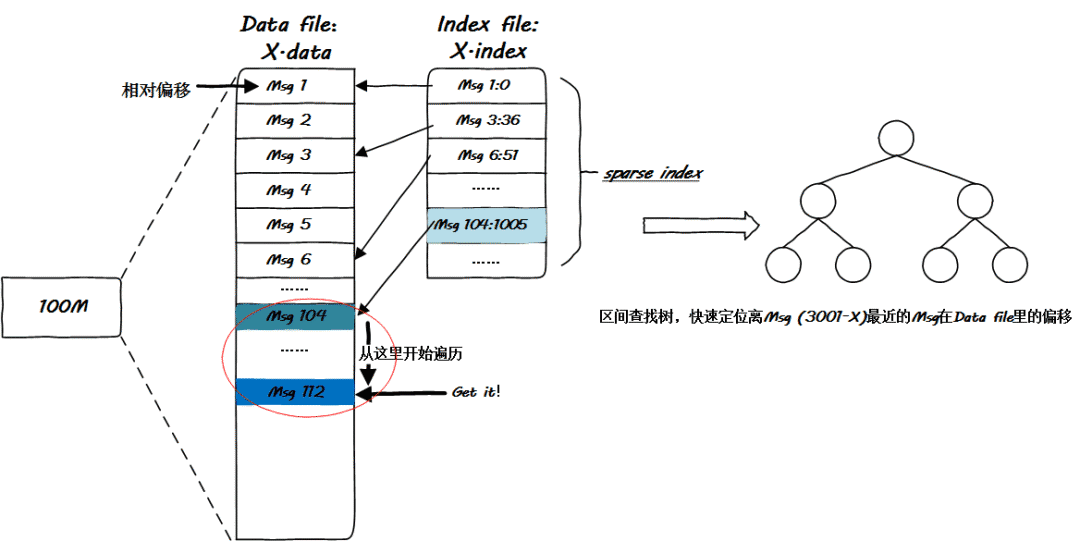
最終,經(jīng)過(guò)兩次區(qū)間樹(shù)查找之后,最多再經(jīng)歷一次簡(jiǎn)單的遍歷即可完成 offset 定位工作。
誠(chéng)然,最終的遍歷可能是少不了的,但是 Kafka 盡可能地避免了大長(zhǎng)段耗時(shí)的遍歷計(jì)算,而是將遍歷壓縮到一個(gè)很小的量級(jí),這是一個(gè)權(quán)衡!跟誰(shuí)權(quán)衡呢?為什么不把段文件所有消息的索引均建立起來(lái)呢?
很簡(jiǎn)單,建立全部的索引會(huì)造成索引非常大,這樣如果你還想其常駐內(nèi)存的話,內(nèi)存占用會(huì)很大,這確實(shí)又是一個(gè)時(shí)間和空間之間的權(quán)衡了。
稀疏索引閑談
稀疏索引很有用,除了本文列舉的 Kafka 的 segment index 稀疏索引之外,還有兩個(gè)更為常見(jiàn)的例子(我不是應(yīng)用編程的,我是搞內(nèi)核網(wǎng)絡(luò)協(xié)議棧的,所以在我看來(lái) Kafka 更不常見(jiàn))
索引整個(gè)內(nèi)存地址空間,稀疏化的做法就是分頁(yè),即采用規(guī)則的方式將內(nèi)存劃分為等大小的塊,叫做內(nèi)存頁(yè),然后索引這些內(nèi)存頁(yè)即可,頁(yè)表而不是地址表稀疏化索引,減小索引的大小。
另外,IP 地址具有地域聚集性,因此對(duì)于路由器物理設(shè)備而言,對(duì)于每一個(gè)接口引出的方向,其 IP 地址集在很大程度上是可以聚集的。
路由表一開(kāi)始采用地址分類的方法,后來(lái)采用了前綴匹配的方法稀疏化索引,地址分類有點(diǎn)像內(nèi)存地址分頁(yè),只是頁(yè)面有多種大小而不僅僅是一種。
而這里的地址前綴則比較像 Kafka 使用的兩種索引,第一種是段索引,這是規(guī)則的,第二種是消息索引,這是不規(guī)則的。因?yàn)橄⒉⒉欢ㄩL(zhǎng)。
兩種說(shuō)法總結(jié)如下:
OS 內(nèi)存頁(yè)表:在從虛擬地址定位物理地址的時(shí)候,需要一一對(duì)應(yīng)定位到每一個(gè)地址嗎?
假如真是這樣子,那么光頁(yè)表項(xiàng)這種管理內(nèi)存就要耗多少你算過(guò)嗎?虛擬地址和物理地址將會(huì)是全相聯(lián)結(jié)構(gòu)。
采用稀疏索引后,只需要定位一個(gè) 4K 大小的頁(yè)面即可,這將大大減小內(nèi)存頁(yè)表的內(nèi)存占用。從而更加高效。
路由表:將每一個(gè) IP 地址均對(duì)應(yīng)到路由器設(shè)備的接口嗎?這不現(xiàn)實(shí)。解決方案一開(kāi)始是基于分配機(jī)構(gòu)的分類地址稀疏索引,后來(lái)采用了基于使用結(jié)構(gòu)的無(wú)類子網(wǎng)的前綴系數(shù)索引,無(wú)論哪種情況,均大大減少了路由表項(xiàng)的數(shù)量。
UNIX 哲學(xué)的出路
沒(méi)出路了!Why?因?yàn)橹挥袕?fù)雜才能體現(xiàn)自己的工作量。
人們都希望制造門(mén)檻,把程序做的非常復(fù)雜,方才體現(xiàn)自己的能力,畢竟簡(jiǎn)單的東西大家都會(huì),想體現(xiàn)區(qū)別,只能讓自己的東西更復(fù)雜。
如果你用幾行 Bash 腳本完成了一項(xiàng)艱巨的工作,經(jīng)理大概率會(huì)覺(jué)得你這是奇技淫巧,完全無(wú)法和 C++ 的方案相比。Python 好一點(diǎn),Java 則更好。
4,5 年以前的曾經(jīng),我們有個(gè)編程道場(chǎng)的活動(dòng),有一次的一個(gè)題目是拼接字符串,即 join 操作,當(dāng)時(shí)的經(jīng)理兼主持者強(qiáng)調(diào)盡量用現(xiàn)成的接口,然而…
多少個(gè)優(yōu)秀的極簡(jiǎn)方案沒(méi)有被表?yè)P(yáng),最后被表?yè)P(yáng)的方案你們知道其特征是什么嗎?其特征就是復(fù)雜。
我記得當(dāng)時(shí)這個(gè)方案的作者上臺(tái)介紹他的方案,上來(lái)就說(shuō)”我這個(gè)設(shè)計(jì)非常簡(jiǎn)單…”結(jié)果呢,唉,用技術(shù)術(shù)語(yǔ)講,過(guò)度設(shè)計(jì)了,用白話講,裝逼了。主持者顯然也是完全半瓶子晃蕩的吧,哈哈。
事情必須做的盡量復(fù)雜,這樣才是能力的體現(xiàn),2 行能搞定的東西,必須湊夠 30 行才算牛逼。UNIX 哲學(xué),在我們這,顯然不合適吧。
作者:極客重生
編輯:陶家龍
出處:轉(zhuǎn)載自公眾號(hào)極客重生(ID:geek__coding)




















