Kafka 消息存儲及檢索
Kafka是一個分布式的消息隊列系統,消息存儲在集群服務器的硬盤
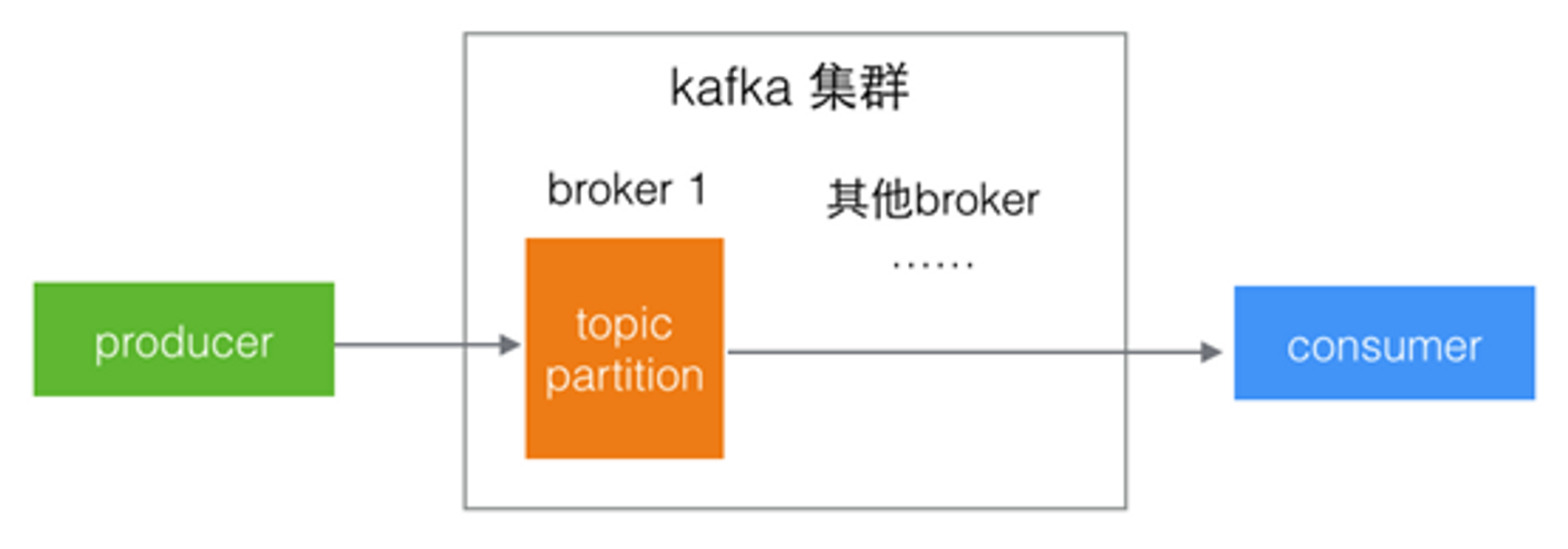
Kafka中可以創建多個消息隊列,稱為topic,消息的生產者向topic中發布消息,消息的消費者從topic中獲取消息
消息是海量的,為了消息的讀寫性能,topic被分為多個部分,稱為partition,kafka把每個topic的每個partition均勻的分布在集群中的不同服務器上
所以從整體來看,Kafka的邏輯關系就是:生產者向topic中的某個partition發送消息,消費者從partition獲取消息
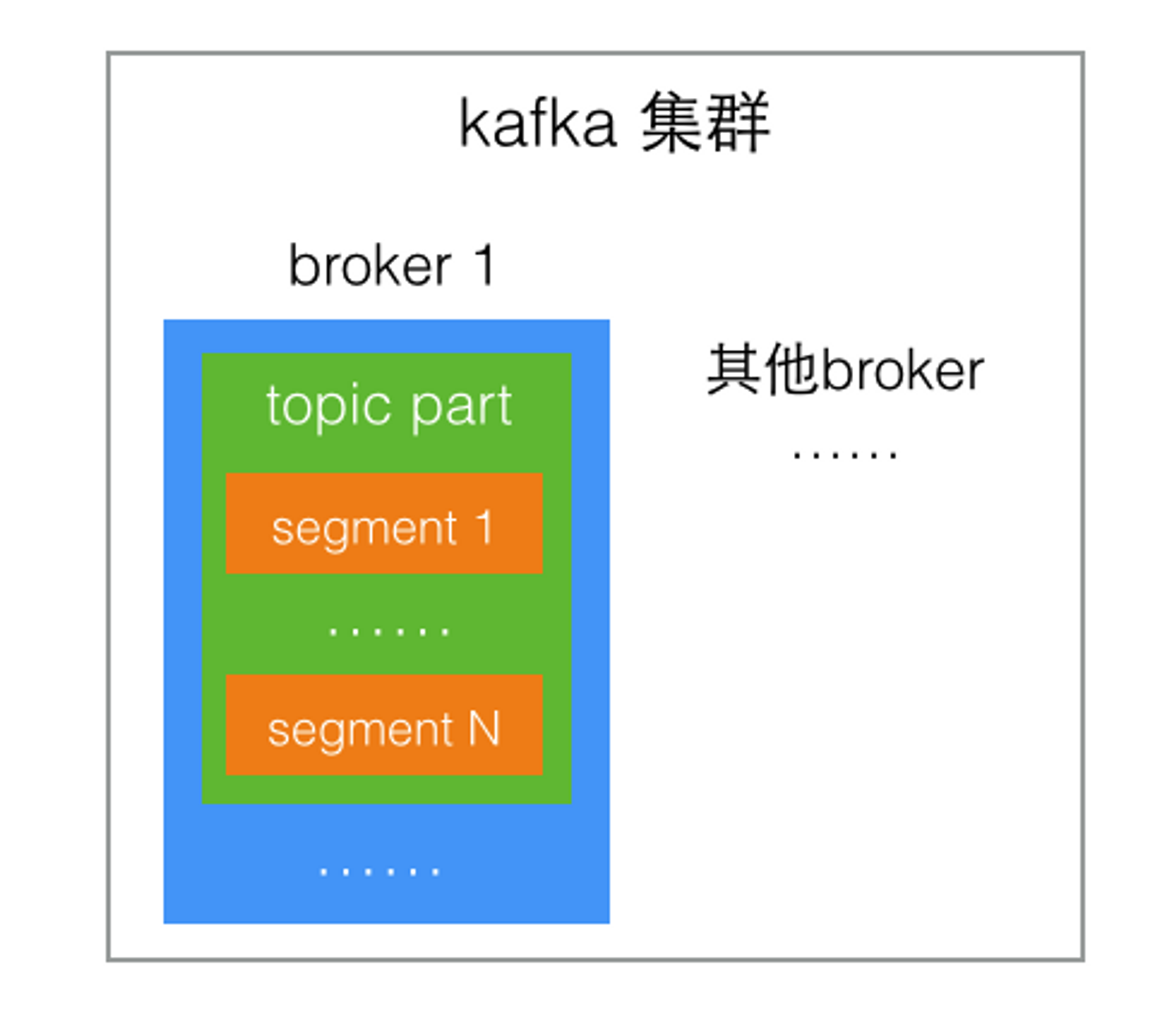
實際的存儲結構中,partition并不是存放消息的物理文件,而是一個目錄,命名規則是topic名稱加上partition序號,其中包含了這個partition的N個分段存儲文件segment。
分段存儲也是因為partition內容非常多,分成小文件更便于消息的寫入和檢索。
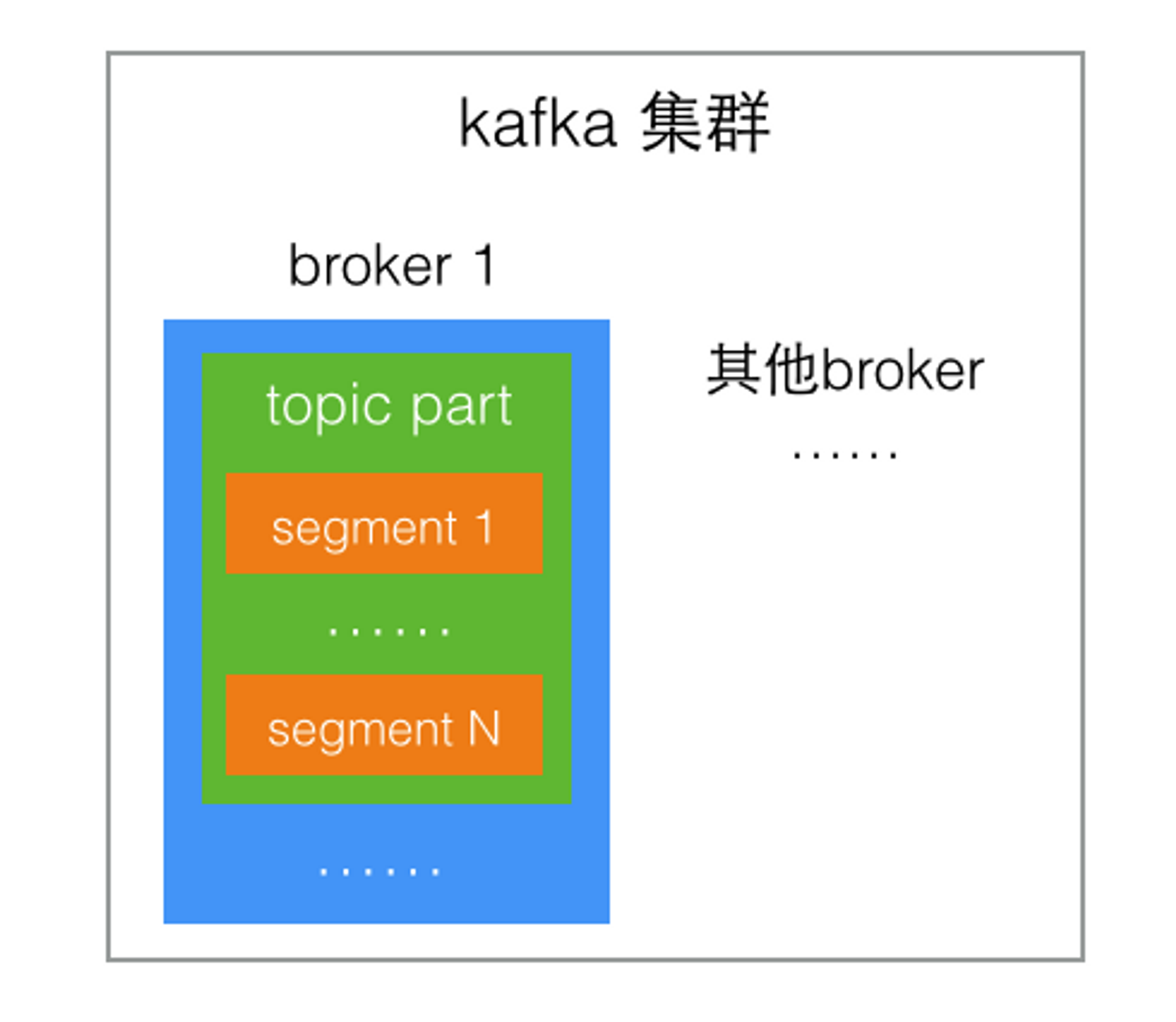
segment也不是一個文件,是由兩個物理文件構成:
.index索引文件、.log消息內容文件
這兩個文件是成對出現,名稱一樣,只是后綴不同
實際的存儲結構就是這樣的
消息是按照順序產生的,所以每個消息都有一個序號,稱為offset,表示partiion的第多少個message,從0開始
每個segment存儲了一段offset區間內的消息
segment文件以offset區間的起始值命名,長度固定20位,不足的位用0填充
例如存儲了第0-20條的消息,segment文件就是:
00000000000000000000.index
00000000000000000000.log
index文件結構很簡單,每一行都是一個key,value對
key 是消息的序號offset
value 是消息的物理位置偏移量
如
1,0
3,299
6,497
...
說明的就是第幾個消息的物理位置是哪兒
log文件中保存了消息的實際內容,和相關信息
如消息的offset、消息的大小、消息校驗碼、消息數據等
消息檢索過程示例
例如讀取offset=368的消息
(1)找到第368條消息在哪個segment
從partition目錄中取得所有segment文件的名稱,就相當于得到了各個序號區間
例如有3個segment
00000000000000000000.index
00000000000000000000.log
00000000000000000300.index
00000000000000000300.log
00000000000000000600.index
00000000000000000600.log
根據二分查找,可以快速定位
第368條消息是在00000000000000000300.log文件中
(2)從index文件中找到其物理偏移量
讀取00000000000000000300.index
以368為key,得到value,如299,就是消息的物理位置偏移量
(3)到log文件中讀取消息內容
讀取 00000000000000000300.log
從偏移量299開始讀取消息內容
完成了消息的檢索過程