













在Scrapy中如何利用Xpath選擇器從網頁中采集目標數據——詳細教程(上篇)

/前言/
上一篇文章我們講述了網頁結構和Xpath表達式語法知識,感興趣的小伙伴可以戳這篇文章:網頁結構的簡介和Xpath語法的入門教程。我們了解到Xpath表達式最好是通過自己進行網頁分析和針對性的選取唯一性的標簽進行定位,可以提高提取效率,而且還不容易出錯。
有了Xpath表達式基礎之后,這篇文章我們將通過Xpath表達式來進行提取數據,具體教程如下,仍然以之前的網站為例進行說明,我們的目標數據是標題、發布日期、主題、正文內容、點贊數、收藏數、評論數等。具體的教程如下。
/具體實現/

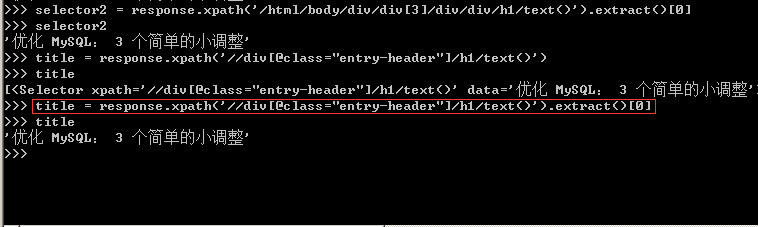
1、針對標題,在上篇文章中就有提及,其Xpath表達式有多種,任選其一即可,在scrapy shell腳本下進行調試,得到標題的提取方式,并寫入到爬蟲主體文件中。
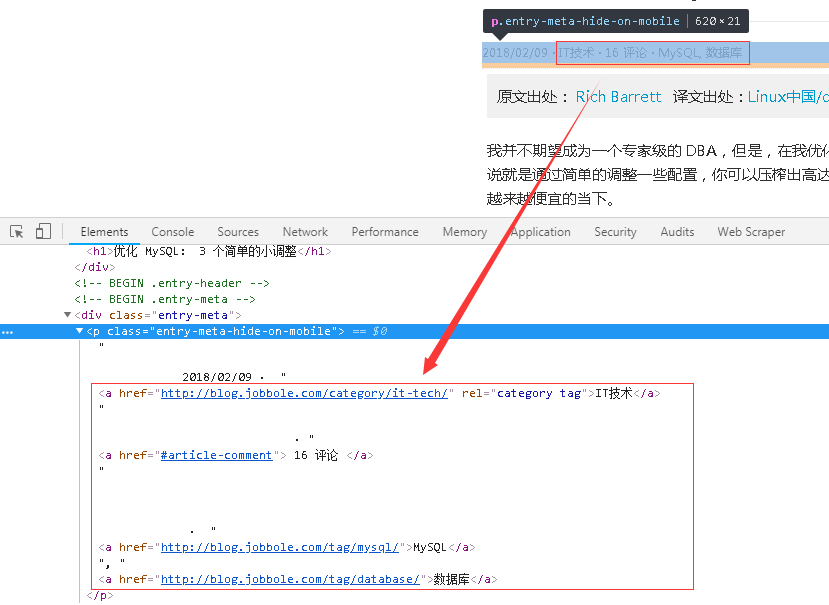
2、接下來是發布日期的提取,仍然是以交互式的方式實現網頁與源碼之間的交互,如下圖所示。
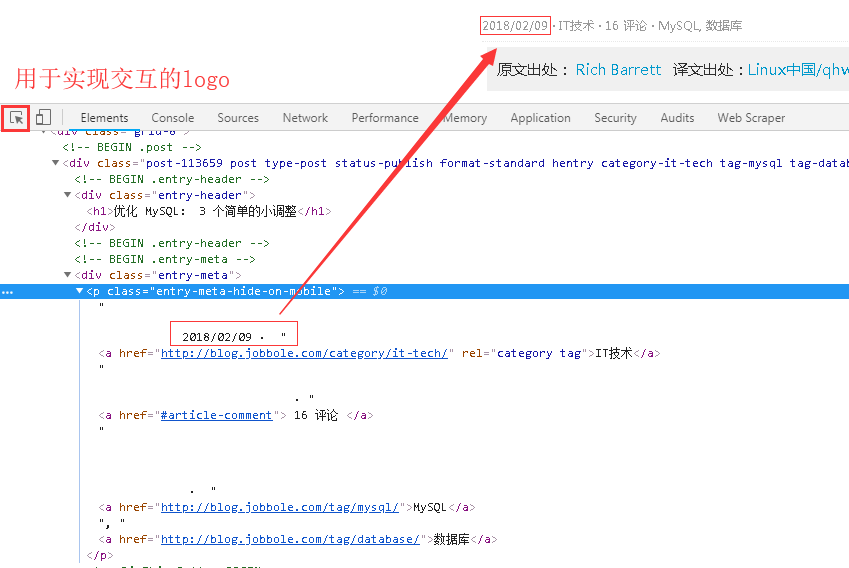
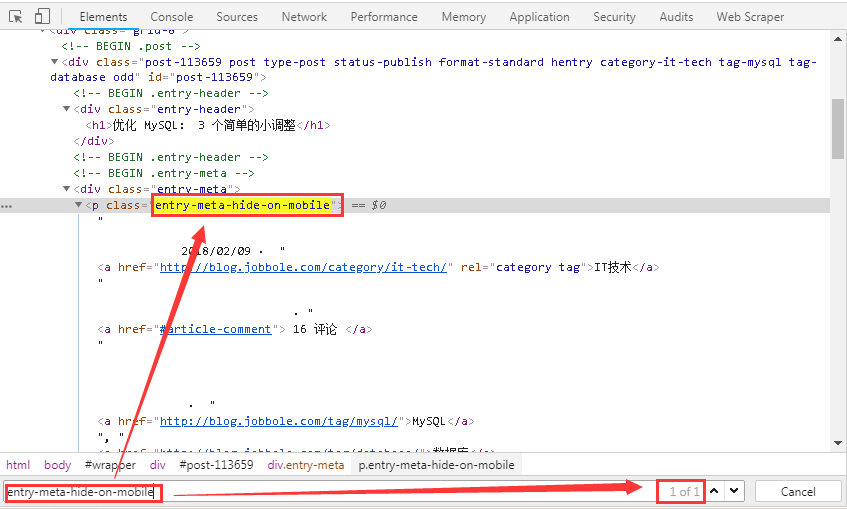
3、而且標簽“entry-meta-hide-on-mobile”具有全局唯一性,可以很方便的定位到元素。
4、根據網頁結構,我們可輕易的寫出發布日期的Xpath表達式,可以在scrapy shell中先進行測試,再將選擇器表達式寫入爬蟲文件中,詳情如下圖所示。
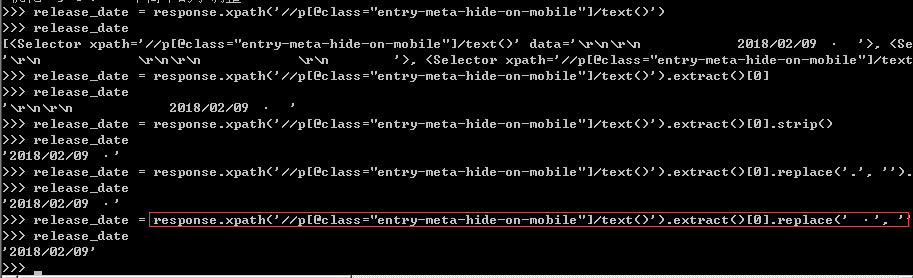
這里有部分雜質信息,需要利用strip()和replace()函數剔除多余的雜質,還日期一個“清白”。
5、關于文章主題標簽的Xpath表達式,可以看到其在網頁結構上處于日期的下方,如下圖所示。
因此可以通過更改一下發布日期的Xpath表達式,即可獲取到文章主題標簽。
6、文章主題標簽處于a標簽下,如下圖所示。
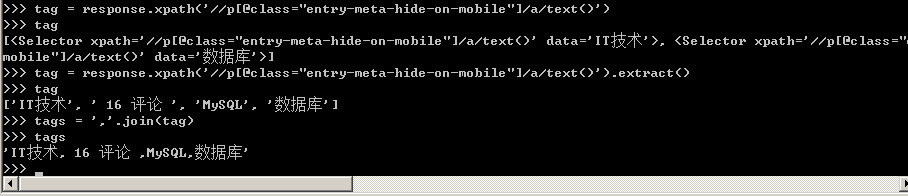
獲取到整個列表之后,利用join函數將數組中的元素以逗號連接生成一個新的字符串叫tags,然后寫入Scrapy爬蟲文件中去。
7、對于點贊數,其分析方法同之前一致,找到唯一的一個標簽“vote-post-up”即可定位到數據。
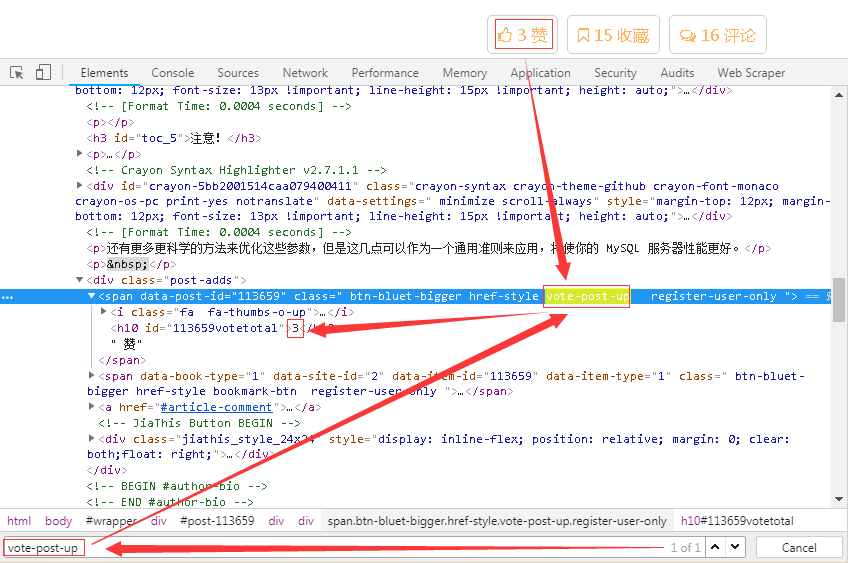
8、細心的小伙伴可能會看到“vote-post-up”屬性并不是class標簽中唯一一個屬性,所以一開始的Xpath表達式匹配的內容為空。
這里給大家安利一個小技巧,如果標簽中存在多個屬性,且屬性是唯一的時候,可以利用contains函數進行助攻,其用法是'//span[contains(@class,"vote-post-up"),務必要多加練習,否則容易忘記。根據網頁結構寫出Xpath表達式,調試的過程如下圖所示。
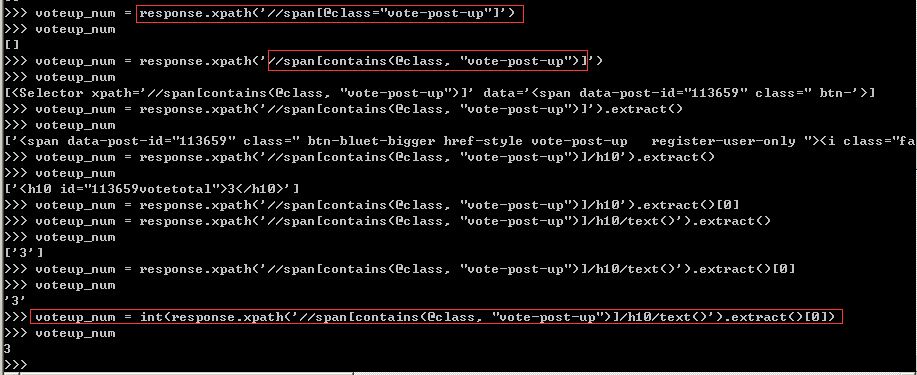
取出的點贊數是個字符串,需要利用int()將其強制轉換為數字。
未完待續~~~,下一篇文章將繼續分享Xpath表達式數據采集方法。
/小結/
本文基于Xpath理論基礎,主要介紹了Scrapy爬蟲框架中利用Xpath選擇器提取某個網頁中目標數據的方法,為后面抓取全網數據埋下伏筆,更精彩的操作在下篇文章奉上,希望對大家的學習有幫助。
















