如何利用Scrapy爬蟲框架抓取網頁全部文章信息(上篇)

前一階段我們已經實現了通過Scrapy抓取某一具體網頁頁面的具體信息,關于Scrapy爬蟲框架中meta參數的使用示例演示(上)、關于Scrapy爬蟲框架中meta參數的使用示例演示(下),但是未實現對所有頁面的依次提取。首先我們理一下爬取思路,大致思想是:當獲取到第一個頁面的URL之后,爾后將第二頁的URL發送給Scrapy,讓Scrapy去自動下載該網頁的信息,之后通過第二頁的URL繼續獲取第三頁的URL,由于每一頁的網頁結構是一致的,所以通過這種方式如此反復進行迭代,便可以實現整個網頁中的信息提取。其具體的實現過程將通過Scrapy框架來進行實現,具體的教程如下。
/具體實現/
1、首先URL不再是某一篇具體文章的URL了,而是所有文章列表的URL,如下圖所示,將鏈接放到start_urls里邊,如下圖所示。

2、接下來我們將需要更改parse()函數,在這個函數中我們需要實現兩件事情。
其一是獲取某一頁面所有文章的URL并對其進行解析,獲取每一篇文章里的具體網頁內容,其二是獲取下一個網頁的URL并交給Scrapy進行下載,下載完成之后再交給parse()函數。
有了之前的Xpath和CSS選擇器基礎知識之后,獲取網頁鏈接URL就變得相對簡單了。
3、分析網頁結構,使用網頁交互工具,我們可以很快的發現每一個網頁有20篇文章,即20個URL,而且文章列表都存在于id="archive"這個標簽下面,之后像剝洋蔥一樣去獲取我們想要的URL鏈接。
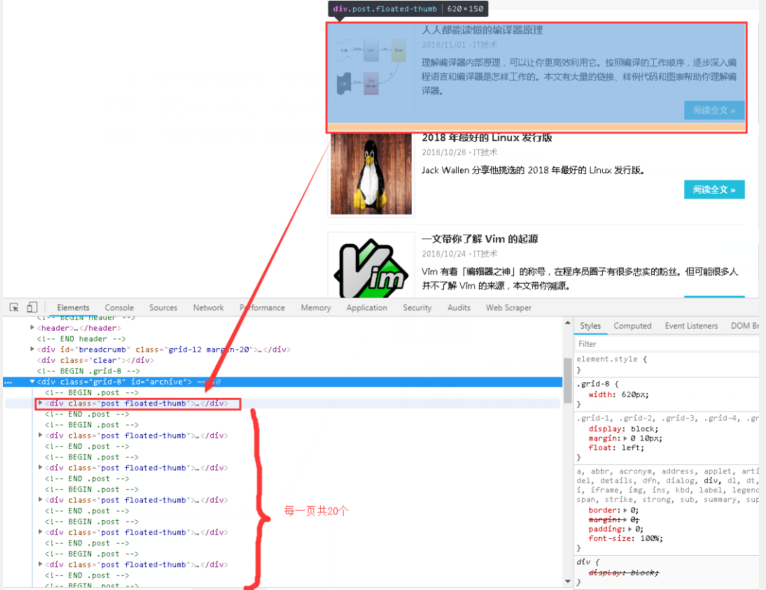
4、點開下拉三角,不難發現文章詳情頁的鏈接藏的不深,如下圖圈圈中所示。
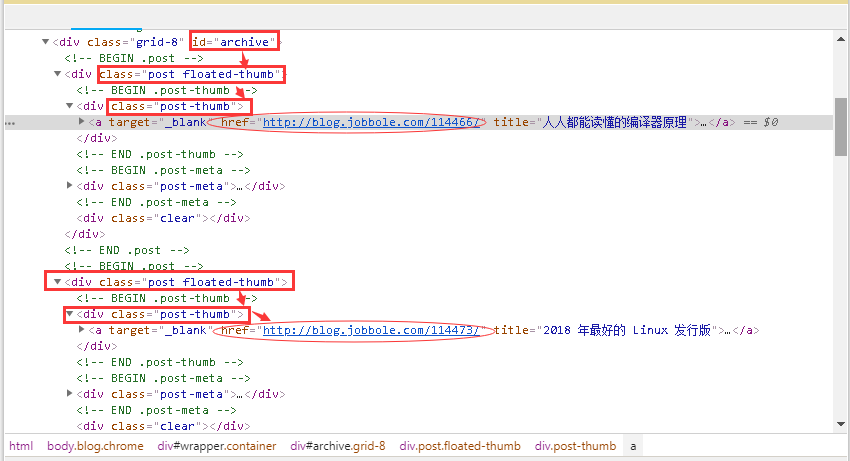
5、根據標簽我們按圖索驥,加上選擇器利器,獲取URL猶如探囊取物。在cmd中輸入下圖命令,以進入shell調試窗口,事半功倍。再次強調,這個URL是所有文章的網址,而不是某一篇文章的URL,不然后面你調試半天都不會有結果的。

6、根據第四步的網頁結構分析,我們在shell中寫入CSS表達式,并進行輸出,如下圖所示。其中a::attr(href)的用法很巧妙,也是個提取標簽信息的小技巧,建議小伙伴們在提取網頁信息的時候可以經常使用,十分方便。

至此,第一頁的所有文章列表的URL已經獲取到了。提取到URL之后,如何將其交給Scrapy去進行下載呢?下載完成之后又如何調用我們自己定義的解析函數呢?
欲知后事如何,且聽下一篇文章分解。
/小結/
本文主要介紹了Scrapy爬蟲框架抓取其中某個網頁數據的理論,為后面抓取全網數據埋下伏筆,更精彩的操作在下篇文章奉上,希望對大家的學習有幫助。
想學習更多關于Python的知識,可以參考學習網址:http://pdcfighting.com/,點擊閱讀原文,可以直達噢~