













看完這篇你還能不懂C語言/C++內存管理?
C 語言內存管理指對系統內存的分配、創建、使用這一系列操作。在內存管理中,由于是操作系統內存,使用不當會造成畢竟麻煩的結果。本文將從系統內存的分配、創建出發,并且使用例子來舉例說明內存管理不當會出現的情況及解決辦法。
一、內存
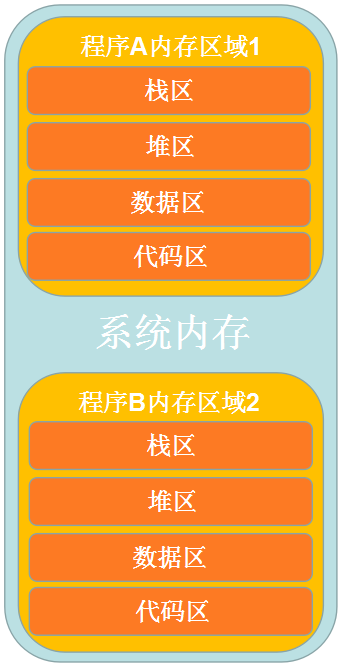
在計算機中,每個應用程序之間的內存是相互獨立的,通常情況下應用程序 A 并不能訪問應用程序 B,當然一些特殊技巧可以訪問,但此文并不詳細進行說明。例如在計算機中,一個視頻播放程序與一個瀏覽器程序,它們的內存并不能訪問,每個程序所擁有的內存是分區進行管理的。
在計算機系統中,運行程序 A 將會在內存中開辟程序 A 的內存區域 1,運行程序 B 將會在內存中開辟程序 B 的內存區域 2,內存區域 1 與內存區域 2 之間邏輯分隔。

1.1 內存四區
在程序 A 開辟的內存區域 1 會被分為幾個區域,這就是內存四區,內存四區分為棧區、堆區、數據區與代碼區。
棧區指的是存儲一些臨時變量的區域,臨時變量包括了局部變量、返回值、參數、返回地址等,當這些變量超出了當前作用域時將會自動彈出。該棧的最大存儲是有大小的,該值固定,超過該大小將會造成棧溢出。
堆區指的是一個比較大的內存空間,主要用于對動態內存的分配;在程序開發中一般是開發人員進行分配與釋放,若在程序結束時都未釋放,系統將會自動進行回收。
數據區指的是主要存放全局變量、常量和靜態變量的區域,數據區又可以進行劃分,分為全局區與靜態區。全局變量與靜態變量將會存放至該區域。
代碼區就比較好理解了,主要是存儲可執行代碼,該區域的屬性是只讀的。
1.2 使用代碼證實內存四區的底層結構
由于棧區與堆區的底層結構比較直觀的表現,在此使用代碼只演示這兩個概念。首先查看代碼觀察棧區的內存地址分配情況:
- #include<stdio.h>
- int main()
- {
- int a = 0;
- int b = 0;
- char c='0';
- printf("變量a的地址是:%d\n變量b的地址是:%d\n變量c的地址是:%d\n", &a, &b, &c);
- }
運行結果為:
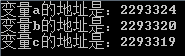
我們可以觀察到變量 a 的地址是 2293324 變量 b 的地址是 2293320,由于 int 的數據大小為 4 所以兩者之間間隔為 4;再查看變量 c,我們發現變量 c 的地址為 2293319,與變量 b 的地址 2293324 間隔 1,因為 c 的數據類型為 char,類型大小為 1。在此我們觀察發現,明明我創建變量的時候順序是 a 到 b 再到 c,為什么它們之間的地址不是增加而是減少呢?那是因為棧區的一種數據存儲結構為先進后出,如圖:
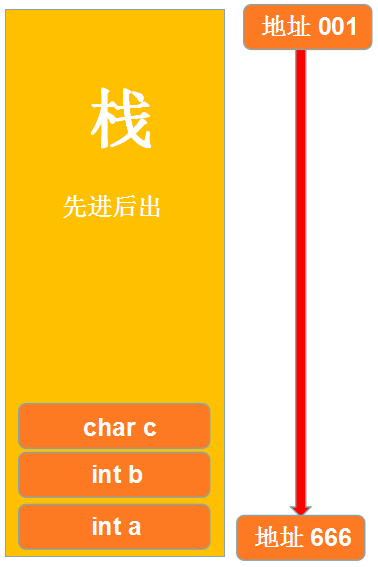
首先棧的頂部為地址的“最小”索引,隨后往下依次增大,但是由于堆棧的特殊存儲結構,我們將變量 a 先進行存儲,那么它的一個索引地址將會是最大的,隨后依次減少;第二次存儲的值是 b,該值的地址索引比 a 小,由于 int 的數據大小為 4,所以在 a 地址為 2293324 的基礎上往上減少 4 為 2293320,在存儲 c 的時候為 char,大小為 1,則地址為 2293319。由于 a、b、c 三個變量同屬于一個棧內,所以它們地址的索引是連續性的,那如果我創建一個靜態變量將會如何?在以上內容中說明了靜態變量存儲在靜態區內,我們現在就來證實一下:
- #include<stdio.h>
- int main()
- {
- int a = 0;
- int b = 0;
- char c='0';
- static int d = 0;
- printf("變量a的地址是:%d\n變量b的地址是:%d\n變量c的地址是:%d\n", &a, &b, &c);
- printf("靜態變量d的地址是:%d\n", &d);
- }
運行結果如下:
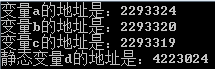
以上代碼中創建了一個變量 d,變量 d 為靜態變量,運行代碼后從結果上得知,靜態變量 d 的地址與一般變量 a、b、c 的地址并不存在連續,他們兩個的內存地址是分開的。那接下來在此建一個全局變量,通過上述內容得知,全局變量與靜態變量都應該存儲在靜態區,代碼如下:
- #include<stdio.h>
- int e = 0;
- int main()
- {
- int a = 0;
- int b = 0;
- char c='0';
- static int d = 0;
- printf("變量a的地址是:%d\n變量b的地址是:%d\n變量c的地址是:%d\n", &a, &b, &c);
- printf("靜態變量d的地址是:%d\n", &d);
- printf("全局變量e的地址是:%d\n", &e);
- }
運行結果如下:
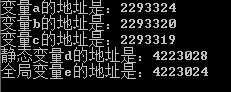
從以上運行結果中證實了上述內容的真實性,并且也得到了一個知識點,棧區、數據區都是使用棧結構對數據進行存儲。
在以上內容中還說明了一點棧的特性,就是容量具有固定大小,超過最大容量將會造成棧溢出。查看如下代碼:
- #include<stdio.h>
- int main()
- {
- char arr_char[1024*1000000];
- arr_char[0] = '0';
- }
以上代碼定義了一個字符數組 arr_char,并且設置了大小為 1024*1000000,設置該數據是方便查看大小;隨后在數組頭部進行賦值。運行結果如下:
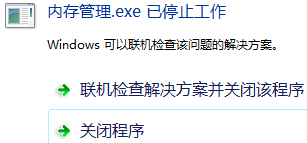
這是程序運行出錯,原因是造成了棧的溢出。在平常開發中若需要大容量的內存,需要使用堆。
堆并沒有棧一樣的結構,也沒有棧一樣的先進后出。需要人為的對內存進行分配使用。代碼如下:
- #include<stdio.h>
- #include<string.h>
- #include <malloc.h>
- int main()
- {
- char *p1 = (char *)malloc(1024*1000000);
- strcpy(p1, "這里是堆區");
- printf("%s\n", p1);
- }
以上代碼中使用了strcpy 往手動開辟的內存空間 p1 中傳數據“這里是堆區”,手動開辟空間使用 malloc,傳入申請開辟的空間大小 1024*1000000,在棧中那么大的空間必定會造成棧溢出,而堆本身就是大容量,則不會出現該情況。隨后輸出開辟的內存中內容,運行結果如下:
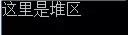
在此要注意p1是表示開辟的內存空間地址。
二、malloc 和 free
在 C 語言(不是 C++)中,malloc 和 free 是系統提供的函數,成對使用,用于從堆中分配和釋放內存。malloc 的全稱是 memory allocation 譯為“動態內存分配”。
2.1 malloc 和 free 的使用
在開辟堆空間時我們使用的函數為 malloc,malloc 在 C 語言中是用于申請內存空間,malloc 函數的原型如下:
- void *malloc(size_t size);
在 malloc 函數中,size 是表示需要申請的內存空間大小,申請成功將會返回該內存空間的地址;申請失敗則會返回 NULL,并且申請成功也不會自動進行初始化。
細心的同學可能會發現,該函數的返回值說明為 void *,在這里 void * 并不指代某一種特定的類型,而是說明該類型不確定,通過接收的指針變量從而進行類型的轉換。在分配內存時需要注意,即時在程序關閉時系統會自動回收該手動申請的內存 ,但也要進行手動的釋放,保證內存能夠在不需要時返回至堆空間,使內存能夠合理的分配使用。
釋放空間使用 free 函數,函數原型如下:
- void free(void *ptr);
free 函數的返回值為 void,沒有返回值,接收的參數為使用 malloc 分配的內存空間指針。一個完整的堆內存申請與釋放的例子如下:
- #include<stdio.h>
- #include<string.h>
- #include <malloc.h>
- int main() {
- int n, *p, i;
- printf("請輸入一個任意長度的數字來分配空間:");
- scanf("%d", &n);
- p = (int *)malloc(n * sizeof(int));
- if(p==NULL){
- printf("申請失敗\n");
- return 0;
- }else{
- printf("申請成功\n");
- }
- memset(p, 0, n * sizeof(int));//填充0
- //查看
- for (i = 0; i < n; i++)
- printf("%d ", p[i]);
- printf("\n");
- free(p);
- p = NULL;
- return 0;
- }
以上代碼中使用了 malloc 創建了一個由用戶輸入創建指定大小的內存,判斷了內存地址是否創建成功,且使用了 memset 函數對該內存空間進行了填充值,隨后使用 for 循環進行了查看。最后使用了 free 釋放了內存,并且將 p 賦值 NULL,這點需要主要,不能使指針指向未知的地址,要置于 NULL;否則在之后的開發者會誤以為是個正常的指針,就有可能再通過指針去訪問一些操作,但是在這時該指針已經無用,指向的內存也不知此時被如何使用,這時若出現意外將會造成無法預估的后果,甚至導致系統崩潰,在 malloc 的使用中更需要需要。
2.2 內存泄漏與安全使用實例與講解
內存泄漏是指在動態分配的內存中,并沒有釋放內存或者一些原因造成了內存無法釋放,輕度則造成系統的內存資源浪費,嚴重的導致整個系統崩潰等情況的發生。
內存泄漏通常比較隱蔽,且少量的內存泄漏發生不一定會發生無法承受的后果,但由于該錯誤的積累將會造成整體系統的性能下降或系統崩潰。特別是在較為大型的系統中,如何有效的防止內存泄漏等問題的出現變得尤為重要。例如一些長時間的程序,若在運行之初有少量的內存泄漏的問題產生可能并未呈現,但隨著運行時間的增長、系統業務處理的增加將會累積出現內存泄漏這種情況;這時極大的會造成不可預知的后果,如整個系統的崩潰,造成的損失將會難以承受。由此防止內存泄漏對于底層開發人員來說尤為重要。
C 程序員在開發過程中,不可避免的面對內存操作的問題,特別是頻繁的申請動態內存時會及其容易造成內存泄漏事故的發生。如申請了一塊內存空間后,未初始化便讀其中的內容、間接申請動態內存但并沒有進行釋放、釋放完一塊動態申請的內存后繼續引用該內存內容;如上所述這種問題都是出現內存泄漏的原因,往往這些原因由于過于隱蔽在測試時不一定會完全清楚,將會導致在項目上線后的長時間運行下,導致災難性的后果發生。
如下是一個在子函數中進行了內存空間的申請,但是并未對其進行釋放:
- #include<stdio.h>
- #include<string.h>
- #include <malloc.h>
- void m() {
- char *p1;
- p1 = malloc(100);
- printf("開始對內存進行泄漏...");
- }
- int main() {
- m();
- return 0;
- }
如上代碼中,使用 malloc 申請了 100 個單位的內存空間后,并沒有進行釋放。假設該 m 函數在當前系統中調用頻繁,那將會每次使用都將會造成 100 個單位的內存空間不會釋放,久而久之就會造成嚴重的后果。理應在 p1 使用完畢后添加 free 進行釋放:
- free(p1);
以下示范一個讀取文件時不規范的操作:
- #include<stdio.h>
- #include<string.h>
- #include <malloc.h>
- int m(char *filename) {
- FILE* f;
- int key;
- f = fopen(filename, "r");
- fscanf(f, "%d", &key);
- return key;
- }
- int main() {
- m("number.txt");
- return 0;
- }
以上文件在讀取時并沒有進行 fclose,這時將會產生多余的內存,可能一次還好,多次會增加成倍的內存,可以使用循環進行調用,之后在任務管理器中可查看該程序運行時所占的內存大小,代碼為:
- #include<stdio.h>
- #include<string.h>
- #include <malloc.h>
- int m(char *filename) {
- FILE* f;
- int key;
- f = fopen(filename, "r");
- fscanf(f, "%d", &key);
- return key;
- }
- int main() {
- int i;
- for(i=0;i<500;i++) {
- m("number.txt");
- }
- return 0;
- }
可查看添加循環后的程序與添加循環前的程序做內存占用的對比,就可以發現兩者之間添加了循環的代碼將會成本增加占用容量。
未被初始化的指針也會有可能造成內存泄漏的情況,因為指針未初始化所指向不可控,如:
- int *p;
- *p = val;
包括錯誤的釋放內存空間:
- pp=p;
- free(p);
- free(pp);
釋放后使用,產生懸空指針。在申請了動態內存后,使用指針指向了該內存,使用完畢后我們通過 free 函數釋放了申請的內存,該內存將會允許其它程序進行申請;但是我們使用過后的動態內存指針依舊指向著該地址,假設其它程序下一秒申請了該區域內的內存地址,并且進行了操作。當我依舊使用已 free 釋放后的指針進行下一步的操作時,或者所進行了一個計算,那么將會造成的結果天差地別,或者是其它災難性后果。所以對于這些指針在生存期結束之后也要置為 null。查看一個示例,由于 free 釋放后依舊使用該指針,造成的計算結果天差地別:
- #include<stdio.h>
- #include<string.h>
- #include <malloc.h>
- int m(char *freep) {
- int val=freep[0];
- printf("2*freep=:%d\n",val*2);
- free(freep);
- val=freep[0];
- printf("2*freep=:%d\n",val*2);
- }
- int main() {
- int *freep = (int *) malloc(sizeof (int));
- freep[0]=1;
- m(freep);
- return 0;
- }
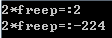
以上代碼使用 malloc 申請了一個內存后,傳值為 1;在函數中首先使用 val 值接收 freep 的值,將 val 乘 2,之后釋放 free,重新賦值給 val,最后使用 val 再次乘 2,此時造成的結果出現了極大的改變,而且最恐怖的是該錯誤很難發現,隱蔽性很強,但是造成的后顧難以承受。運行結果如下:
三、 new 和 delete
C++ 中使用 new 和 delete 從堆中分配和釋放內存,new 和 delete 是運算符,不是函數,兩者成對使用(后面說明為什么成對使用)。
new/delete 除了分配內存和釋放內存(與 malloc/free),還做更多的事情,所有在 C++ 中不再使用 malloc/free 而使用 new/delete。
3.1 new 和 delete 使用
new 一般使用格式如下:
- 指針變量名 = new 類型標識符;
- 指針變量名 = new 類型標識符(初始值);
- 指針變量名 = new 類型標識符[內存單元個數];
在C++中new的三種用法包括:plain new, nothrow new 和 placement new。
plain new 就是我們最常使用的 new 的方式,在 C++ 中的定義如下:
- void* operator new(std::size_t) throw(std::bad_alloc);
- void operator delete( void *) throw();
plain new 在分配失敗的情況下,拋出異常 std::bad_alloc 而不是返回 NULL,因此通過判斷返回值是否為 NULL 是徒勞的。
- char *getMemory(unsigned long size)
- {
- char * p = new char[size];
- return p;
- }
- void main(void)
- {
- try{
- char * p = getMemory(1000000); // 可能發生異常
- // ...
- delete [] p;
- }
- catch(const std::bad_alloc & ex)
- {
- cout << ex.what();
- }
- }
nothrow new 是不拋出異常的運算符new的形式。nothrow new在失敗時,返回NULL。定義如下:
- void * operator new(std::size_t, const std::nothrow_t&) throw();
- void operator delete(void*) throw();
- void func(unsinged long length)
- {
- unsinged char * p = new(nothrow) unsinged char[length];
- // 在使用這種new時要加(nothrow) ,表示不使用異常處理 。
- if (p == NULL) // 不拋異常,一定要檢查
- cout << "allocte failed !";
- // ...
- delete [] p;
- }
placement new 意即“放置”,這種new允許在一塊已經分配成功的內存上重新構造對象或對象數組。placement new不用擔心內存分配失敗,因為它根本不分配內存,它做的唯一一件事情就是調用對象的構造函數。定義如下:
- void* operator new(size_t, void*);
- void operator delete(void*, void*);
palcement new 的主要用途就是反復使用一塊較大的動態分配的內存來構造不同類型的對象或者他們的數組。placement new構造起來的對象或其數組,要顯示的調用他們的析構函數來銷毀,千萬不要使用delete。
- void main()
- {
- using namespace std;
- char * p = new(nothrow) char [4];
- if (p == NULL)
- {
- cout << "allocte failed" << endl;
- exit( -1 );
- }
- // ...
- long * q = new (p) long(1000);
- delete []p; // 只釋放 p,不要用q釋放。
- }
p 和 q 僅僅是首址相同,所構建的對象可以類型不同。所“放置”的空間應小于原空間,以防不測。當”放置new”超過了申請的范圍,Debug 版下會崩潰,但 Release 能運行而不會出現崩潰!
該運算符的作用是:只要第一次分配成功,不再擔心分配失敗。
- void main()
- {
- using namespace std;
- char * p = new(nothrow) char [100];
- if (p == NULL)
- {
- cout << "allocte failed" << endl;
- exit(-1);
- }
- long * q1 = new (p) long(100);
- // 使用q1 ...
- int * q2 = new (p) int[100/sizeof(int)];
- // 使用q2 ...
- ADT * q3 = new (p) ADT[100/sizeof(ADT)];
- // 使用q3 然后釋放對象 ...
- delete [] p; // 只釋放空間,不再析構對象。
- }
注意:使用該運算符構造的對象或數組,一定要顯式調用析構函數,不可用 delete 代替析構,因為 placement new 的對象的大小不再與原空間相同。
- void main()
- {
- using namespace std;
- char * p = new(nothrow) char [sizeof(ADT)+2];
- if (p == NULL)
- {
- cout << "allocte failed" << endl;
- exit(-1);
- }
- // ...
- ADT * q = new (p) ADT;
- // ...
- // delete q; // 錯誤
- q->ADT::~ADT(); // 顯式調用析構函數,僅釋放對象
- delete [] p; // 最后,再用原指針來釋放內存
- }
placement new 的主要用途就是可以反復使用一塊已申請成功的內存空間。這樣可以避免申請失敗的徒勞,又可以避免使用后的釋放。
特別要注意的是對于 placement new 絕不可以調用的 delete, 因為該 new 只是使用別人替它申請的地方。釋放內存是 nothrow new 的事,即要使用原來的指針釋放內存。free/delete 不要重復調用,被系統立即回收后再利用,再一次 free/delete 很可能把不是自己的內存釋放掉,導致異常甚至崩潰。
上面提到 new/delete 比 malloc/free 多做了一些事情,new 相對于 malloc 會額外的做一些初始化工作,delete 相對于 free 多做一些清理工作。
- class A
- {
- public:
- A()
- {
- cont<<"A()構造函數被調用"<<endl;
- }
- ~A()
- {
- cont<<"~A()構造函數被調用"<<endl;
- }
- }
在 main 主函數中,加入如下代碼:
- A* pa = new A(); //類 A 的構造函數被調用
- delete pa; //類 A 的析構函數被調用
可以看出:使用 new 生成一個類對象時系統會調用該類的構造函數,使用 delete 刪除一個類對象時,系統會調用該類的析構函數。可以調用構造函數/析構函數就意味著 new 和 delete 具備針對堆所分配的內存進行初始化和釋放的能力,而 malloc 和 free 不具備。
2.2 delete 與 delete[] 的區別
c++ 中對 new 申請的內存的釋放方式有 delete 和 delete[] 兩種方式,到底這兩者有什么區別呢?
我們通常從教科書上看到這樣的說明:
- delete 釋放 new 分配的單個對象指針指向的內存
- delete[] 釋放 new 分配的對象數組指針指向的內存 那么,按照教科書的理解,我們看下下面的代碼:
- int *a = new int[10];
- delete a; //方式1
- delete[] a; //方式2
針對簡單類型 使用 new 分配后的不管是數組還是非數組形式內存空間用兩種方式均可 如:
- int *a = new int[10];
- delete a;
- delete[] a;
此種情況中的釋放效果相同,原因在于:分配簡單類型內存時,內存大小已經確定,系統可以記憶并且進行管理,在析構時,系統并不會調用析構函數。
它直接通過指針可以獲取實際分配的內存空間,哪怕是一個數組內存空間(在分配過程中 系統會記錄分配內存的大小等信息,此信息保存在結構體 _CrtMemBlockHeader 中,具體情況可參看 VC 安裝目錄下 CRTSRCDBGDEL.cpp)。
針對類 Class,兩種方式體現出具體差異
當你通過下列方式分配一個類對象數組:
- class A
- {
- private:
- char *m_cBuffer;
- int m_nLen;
- `` public:
- A(){ m_cBuffer = new char[m_nLen]; }
- ~A() { delete [] m_cBuffer; }
- };
- A *a = new A[10];
- delete a; //僅釋放了a指針指向的全部內存空間 但是只調用了a[0]對象的析構函數 剩下的從a[1]到a[9]這9個用戶自行分配的m_cBuffer對應內存空間將不能釋放 從而造成內存泄漏
- delete[] a; //調用使用類對象的析構函數釋放用戶自己分配內存空間并且 釋放了a指針指向的全部內存空間
所以總結下就是,如果 ptr 代表一個用new申請的內存返回的內存空間地址,即所謂的指針,那么:
delete ptr 代表用來釋放內存,且只用來釋放 ptr 指向的內存。delete[] rg 用來釋放rg指向的內存,!!還逐一調用數組中每個對象的destructor!!
對于像 int/char/long/int*/struct 等等簡單數據類型,由于對象沒有 destructor ,所以用 delete 和 delete []是一樣的!但是如果是 C++ 對象數組就不同了!
關于 new[] 和 delete[],其中又分為兩種情況:
(1) 為基本數據類型分配和回收空間;
(2) 為自定義類型分配和回收空間;
對于 (1),上面提供的程序已經證明了 delete[] 和 delete 是等同的。但是對于 (2),情況就發生了變化。
我們來看下面的例子,通過例子的學習了解 C++ 中的 delete 和 delete[] 的使用方法
- #include <iostream>
- using namespace std;
- class Babe
- {
- public:
- Babe()
- {
- cout << \"Create a Babe to talk with me\" << endl;
- }
- ~Babe()
- {
- cout << \"Babe don\'t Go away,listen to me\" << endl;
- }
- };
- int main()
- {
- Babe* pbabe = new Babe[3];
- delete pbabe;
- pbabe = new Babe[3];
- delete[] pbabe;
- return 0;
- }
結果是:
- Create a babe to talk with me
- Create a babe to talk with me
- Create a babe to talk with me
- Babe don\'t go away,listen to me
- Create a babe to talk with me
- Create a babe to talk with me
- Create a babe to talk with me
- Babe don\'t go away,listen to me
- Babe don\'t go away,listen to me
- Babe don\'t go away,listen to me
大家都看到了,只使用 delete 的時候只出現一個 Babe don’t go away,listen to me,而使用 delete[] 的時候出現 3 個 Babe don’t go away,listen to me。不過不管使用 delete 還是 delete[] 那三個對象的在內存中都被刪除,既存儲位置都標記為可寫,但是使用 delete 的時候只調用了 pbabe[0] 的析構函數,而使用了 delete[] 則調用了 3 個 Babe 對象的析構函數。
你一定會問,反正不管怎樣都是把存儲空間釋放了,有什么區別。
答:關鍵在于調用析構函數上。此程序的類沒有使用操作系統的系統資源(比如:Socket、File、Thread等),所以不會造成明顯惡果。如果你的類使用了操作系統資源,單純把類的對象從內存中刪除是不妥當的,因為沒有調用對象的析構函數會導致系統資源不被釋放,這些資源的釋放必須依靠這些類的析構函數。所以,在用這些類生成對象數組的時候,用 delete[] 來釋放它們才是王道。而用 delete 來釋放也許不會出問題,也許后果很嚴重,具體要看類的代碼了。
本文轉載自微信公眾號「C語言與CPP編程」,可以通過以下二維碼關注。轉載本文請聯系C語言與CPP編程公眾號。


















