













Linux高性能網絡編程之TCP連接的內存使用
當服務器的并發TCP連接數以十萬計時,我們就會對一個TCP連接在操作系統內核上消耗的內存多少感興趣。socket編程方法提供了SO_SNDBUF、SO_RCVBUF這樣的接口來設置連接的讀寫緩存,linux上還提供了以下系統級的配置來整體設置服務器上的TCP內存使用,但這些配置看名字卻有些互相沖突、概念模糊的感覺,如下(sysctl -a命令可以查看這些配置):
- net.ipv4.tcp_rmem = 8192 87380 16777216
- net.ipv4.tcp_wmem = 8192 65536 16777216
- net.ipv4.tcp_mem = 8388608 12582912 16777216
- net.core.rmem_default = 262144
- net.core.wmem_default = 262144
- net.core.rmem_max = 16777216
- net.core.wmem_max = 16777216
還有一些較少被提及的、也跟TCP內存相關的配置:
- net.ipv4.tcp_moderate_rcvbuf = 1net.ipv4.tcp_adv_win_scale = 2
(注:為方便下文講述,介紹以上系統配置時前綴省略掉,配置值以空格分隔的多個數字以數組來稱呼,例如tcp_rmem[2]表示上面第一行最后一列16777216。)
網上可以找到很多這些系統配置項的說明,然而往往還是讓人費解,例如,tcp_rmem[2]和rmem_max似乎都跟接收緩存最大值有關,但它們卻可以不一致,究竟有什么區別?或者tcp_wmem[1]和wmem_default似乎都表示發送緩存的默認值,沖突了怎么辦?在用抓包軟件抓到的syn握手包里,為什么TCP接收窗口大小似乎與這些配置完全沒關系?
TCP連接在進程中使用的內存大小千變萬化,通常程序較復雜時可能不是直接基于socket編程,這時平臺級的組件可能就封裝了TCP連接使用到的用戶態內存。不同的平臺、組件、中間件、網絡庫都大不相同。而內核態為TCP連接分配內存的算法則是基本不變的,這篇文章將試圖說明TCP連接在內核態中會使用多少內存,操作系統使用怎樣的策略來平衡宏觀的吞吐量與微觀的某個連接傳輸速度。這篇文章也將一如既往的面向應用程序開發者,而不是系統級的內核開發者,所以,不會詳細的介紹為了一個TCP連接、一個TCP報文操作系統分配了多少字節的內存,內核級的數據結構也不是本文的關注點,這些也不是應用級程序員的關注點。這篇文章主要描述linux內核為了TCP連接上傳輸的數據是怎樣管理讀寫緩存的。
一、緩存上限是什么?
(1)先從應用程序編程時可以設置的SO_SNDBUF、SO_RCVBUF說起。
無論何種語言,都對TCP連接提供基于setsockopt方法實現的SO_SNDBUF、SO_RCVBUF,怎么理解這兩個屬性的意義呢?
SO_SNDBUF、SO_RCVBUF都是個體化的設置,即,只會影響到設置過的連接,而不會對其他連接生效。SO_SNDBUF表示這個連接上的內核寫緩存上限。實際上,進程設置的SO_SNDBUF也并不是真的上限,在內核中會把這個值翻一倍再作為寫緩存上限使用,我們不需要糾結這種細節,只需要知道,當設置了SO_SNDBUF時,就相當于劃定了所操作的TCP連接上的寫緩存能夠使用的最大內存。然而,這個值也不是可以由著進程隨意設置的,它會受制于系統級的上下限,當它大于上面的系統配置wmem_max(net.core.wmem_max)時,將會被wmem_max替代(同樣翻一倍);而當它特別小時,例如在2.6.18內核中設計的寫緩存最小值為2K字節,此時也會被直接替代為2K。
SO_RCVBUF表示連接上的讀緩存上限,與SO_SNDBUF類似,它也受制于rmem_max配置項,實際在內核中也是2倍大小作為讀緩存的使用上限。SO_RCVBUF設置時也有下限,同樣在2.6.18內核中若這個值小于256字節就會被256所替代。
(2)那么,可以設置的SO_SNDBUF、SO_RCVBUF緩存使用上限與實際內存到底有怎樣的關系呢?
TCP連接所用內存主要由讀寫緩存決定,而讀寫緩存的大小只與實際使用場景有關,在實際使用未達到上限時,SO_SNDBUF、SO_RCVBUF是不起任何作用的。對讀緩存來說,接收到一個來自連接對端的TCP報文時,會導致讀緩存增加,當然,如果加上報文大小后讀緩存已經超過了讀緩存上限,那么這個報文會被丟棄從而讀緩存大小維持不變。什么時候讀緩存使用的內存會減少呢?當進程調用read、recv這樣的方法讀取TCP流時,讀緩存就會減少。因此,讀緩存是一個動態變化的、實際用到多少才分配多少的緩沖內存,當這個連接非常空閑時,且用戶進程已經把連接上接收到的數據都消費了,那么讀緩存使用內存就是0。
寫緩存也是同樣道理。當用戶進程調用send或者write這樣的方法發送TCP流時,就會造成寫緩存增大。當然,如果寫緩存已經到達上限,那么寫緩存維持不變,向用戶進程返回失敗。而每當接收到TCP連接對端發來的ACK確認了報文的成功發送時,寫緩存就會減少,這是因為TCP的可靠性決定的,發出去報文后由于擔心報文丟失而不會銷毀它,可能會由重發定時器來重發報文。因此,寫緩存也是動態變化的,空閑的正常連接上,寫緩存所用內存通常也為0。
因此,只有當接收網絡報文的速度大于應用程序讀取報文的速度時,可能使讀緩存達到了上限,這時這個緩存使用上限才會起作用。所起作用為:丟棄掉新收到的報文,防止這個TCP連接消耗太多的服務器資源。同樣,當應用程序發送報文的速度大于接收對方確認ACK報文的速度時,寫緩存可能達到上限,從而使send這樣的方法失敗,內核不為其分配內存。
二、緩存的大小與TCP的滑動窗口到底有什么關系?
(1)滑動窗口的大小與緩存大小肯定是有關的,但卻不是一一對應的關系,更不會與緩存上限具有一一對應的關系。因此,網上很多資料介紹rmem_max等配置設置了滑動窗口的最大值,與我們tcpdump抓包時看到的win窗口值完全不一致,是講得通的。下面我們來細探其分別在哪里。
讀緩存的作用有2個:1、將無序的、落在接收滑動窗口內的TCP報文緩存起來;2、當有序的、可以供應用程序讀取的報文出現時,由于應用程序的讀取是延時的,所以會把待應用程序讀取的報文也保存在讀緩存中。所以,讀緩存一分為二,一部分緩存無序報文,一部分緩存待延時讀取的有序報文。這兩部分緩存大小之和由于受制于同一個上限值,所以它們是會互相影響的,當應用程序讀取速率過慢時,這塊過大的應用緩存將會影響到套接字緩存,使接收滑動窗口縮小,從而通知連接的對端降低發送速度,避免無謂的網絡傳輸。當應用程序長時間不讀取數據,造成應用緩存將套接字緩存擠壓到沒空間,那么連接對端會收到接收窗口為0的通知,告訴對方:我現在消化不了更多的報文了。
反之,接收滑動窗口也是一直在變化的,我們用tcpdump抓三次握手的報文:
- 14:49:52.421674 IP houyi-vm02.dev.sd.aliyun.com.6400 > r14a02001.dg.tbsite.net.54073: S 2736789705:2736789705(0) ack 1609024383 win 5792 <mss 1460,sackOK,timestamp 2925954240 2940689794,nop,wscale 9>
可以看到初始的接收窗口是5792,當然也遠小于最大接收緩存(稍后介紹的tcp_rmem[1])。
這當然是有原因的,TCP協議需要考慮復雜的網絡環境,所以使用了慢啟動、擁塞窗口(參見 高性能網絡編程2----TCP消息的發送 ),建立連接時的初始窗口并不會按照接收緩存的最大值來初始化。這是因為,過大的初始窗口從宏觀角度,對整個網絡可能造成過載引發惡性循環,也就是考慮到鏈路上各環節的諸多路由器、交換機可能扛不住壓力不斷的丟包(特別是廣域網),而微觀的TCP連接的雙方卻只按照自己的讀緩存上限作為接收窗口,這樣雙方的發送窗口(對方的接收窗口)越大就對網絡產生越壞的影響。慢啟動就是使初始窗口盡量的小,隨著接收到對方的有效報文,確認了網絡的有效傳輸能力后,才開始增大接收窗口。
不同的linux內核有著不同的初始窗口,我們以廣為使用的linux2.6.18內核為例,在以太網里,MSS大小為1460,此時初始窗口大小為4倍的MSS,簡單列下代碼(*rcv_wnd即初始接收窗口):
- int init_cwnd = 4;
- if (mss > 1460*3)
- init_cwnd = 2;
- else if (mss > 1460)
- init_cwnd = 3;
- if (*rcv_wnd > init_cwnd*mss)
- *rcv_wnd = init_cwnd*mss;
大家可能要問,為何上面的抓包上顯示窗口其實是5792,并不是1460*4為5840呢?這是因為1460想表達的意義是:將1500字節的MTU去除了20字節的IP頭、20字節的TCP頭以后,一個最大報文能夠承載的有效數據長度。但有些網絡中,會在TCP的可選頭部里,使用12字節作為時間戳使用,這樣,有效數據就是MSS再減去12,初始窗口就是(1460-12)*4=5792,這與窗口想表達的含義是一致的,即:我能夠處理的有效數據長度。
在linux3以后的版本中,初始窗口調整到了10個MSS大小,這主要來自于GOOGLE的建議。原因是這樣的,接收窗口雖然常以指數方式來快速增加窗口大小(擁塞閥值以下是指數增長的,閥值以上進入擁塞避免階段則為線性增長,而且,擁塞閥值自身在收到128以上數據報文時也有機會快速增加),若是傳輸視頻這樣的大數據,那么隨著窗口增加到(接近)最大讀緩存后,就會“開足馬力”傳輸數據,但若是通常都是幾十KB的網頁,那么過小的初始窗口還沒有增加到合適的窗口時,連接就結束了。這樣相比較大的初始窗口,就使得用戶需要更多的時間(RTT)才能傳輸完數據,體驗不好。
那么這時大家可能有疑問,當窗口從初始窗口一路擴張到最大接收窗口時,最大接收窗口就是最大讀緩存嗎?
不是,因為必須分一部分緩存用于應用程序的延時報文讀取。到底會分多少出來呢?這是可配的系統選項,如下:
- net.ipv4.tcp_adv_win_scale = 2
這里的 tcp_adv_win_scale意味著,將要拿出1/(2^ tcp_adv_win_scale )緩存出來做應用緩存。即,默認 tcp_adv_win_scale配置為2時,就是拿出至少1/4的內存用于應用讀緩存,那么,最大的接收滑動窗口的大小只能到達讀緩存的3/4。
(2)最大讀緩存到底應該設置到多少為合適呢?
當應用緩存所占的份額通過tcp_adv_win_scale配置確定后,讀緩存的上限應當由最大的TCP接收窗口決定。初始窗口可能只有4個或者10個MSS,但在無丟包情形下隨著報文的交互窗口就會增大,當窗口過大時,“過大”是什么意思呢?即,對于通訊的兩臺機器的內存而言不算大,但是對于整個網絡負載來說過大了,就會對網絡設備引發惡性循環,不斷的因為繁忙的網絡設備造成丟包。而窗口過小時,就無法充分的利用網絡資源。所以,一般會以BDP來設置最大接收窗口(可計算出最大讀緩存)。BDP叫做帶寬時延積,也就是帶寬與網絡時延的乘積,例如若我們的帶寬為2Gbps,時延為10ms,那么帶寬時延積BDP則為2G/8*0.01=2.5MB,所以這樣的網絡中可以設最大接收窗口為2.5MB,這樣最大讀緩存可以設為4/3*2.5MB=3.3MB。
為什么呢?因為BDP就表示了網絡承載能力,最大接收窗口就表示了網絡承載能力內可以不經確認發出的報文。如下圖所示:
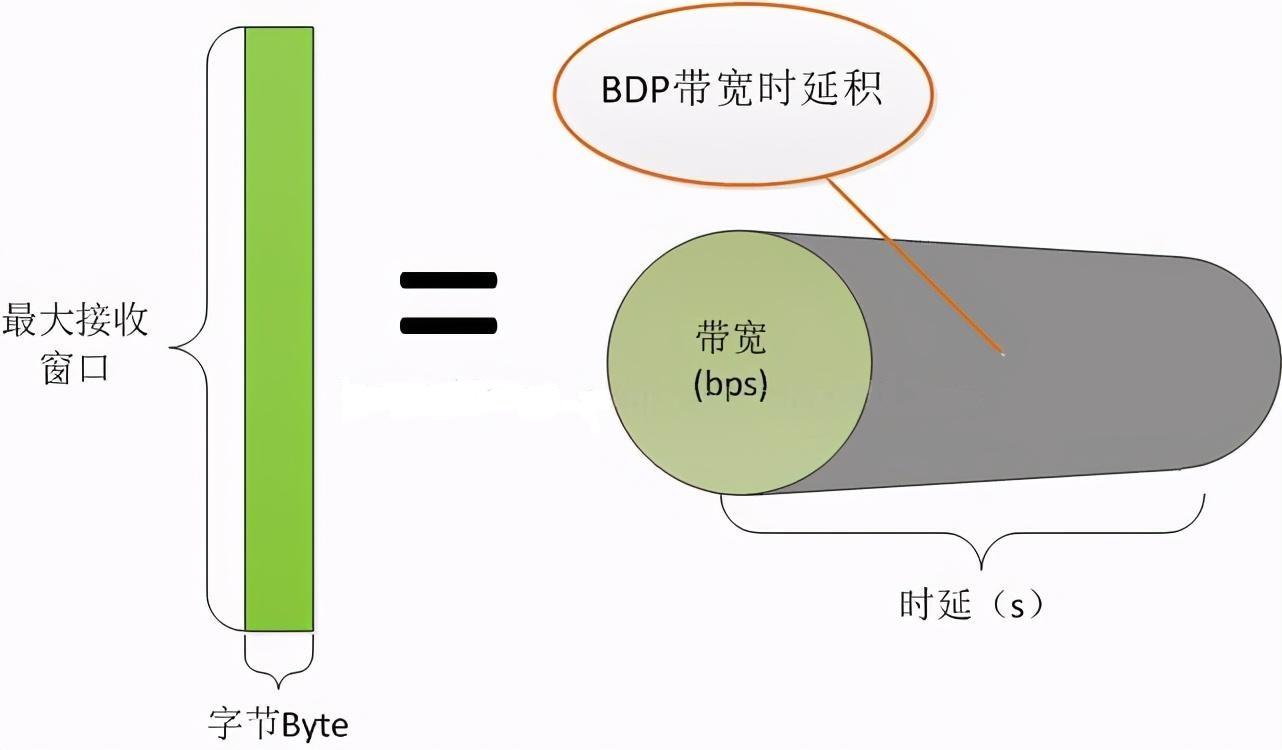
經常提及的所謂長肥網絡,“長”就是是時延長,“肥”就是帶寬大,這兩者任何一個大時,BDP就大,都應導致最大窗口增大,進而導致讀緩存上限增大。所以在長肥網絡中的服務器,緩存上限都是比較大的。(當然,TCP原始的16位長度的數字表示窗口雖然有上限,但在RFC1323中定義的彈性滑動窗口使得滑動窗口可以擴展到足夠大。)
發送窗口實際上就是TCP連接對方的接收窗口,所以大家可以按接收窗口來推斷,這里不再啰嗦。
三、linux的TCP緩存上限自動調整策略
那么,設置好最大緩存限制后就高枕無憂了嗎?對于一個TCP連接來說,可能已經充分利用網絡資源,使用大窗口、大緩存來保持高速傳輸了。比如在長肥網絡中,緩存上限可能會被設置為幾十兆字節,但系統的總內存卻是有限的,當每一個連接都全速飛奔使用到最大窗口時,1萬個連接就會占用內存到幾百G了,這就限制了高并發場景的使用,公平性也得不到保證。我們希望的場景是,在并發連接比較少時,把緩存限制放大一些,讓每一個TCP連接開足馬力工作;當并發連接很多時,此時系統內存資源不足,那么就把緩存限制縮小一些,使每一個TCP連接的緩存盡量的小一些,以容納更多的連接。
linux為了實現這種場景,引入了自動調整內存分配的功能,由tcp_moderate_rcvbuf配置決定,如下:
- net.ipv4.tcp_moderate_rcvbuf = 1
默認tcp_moderate_rcvbuf配置為1,表示打開了TCP內存自動調整功能。若配置為0,這個功能將不會生效(慎用)。
另外請注意:當我們在編程中對連接設置了SO_SNDBUF、SO_RCVBUF,將會使linux內核不再對這樣的連接執行自動調整功能!
那么,這個功能到底是怎樣起作用的呢?看以下配置:
- net.ipv4.tcp_rmem = 8192 87380 16777216
- net.ipv4.tcp_wmem = 8192 65536 16777216
- net.ipv4.tcp_mem = 8388608 12582912 16777216
tcp_rmem[3]數組表示任何一個TCP連接上的讀緩存上限,其中 tcp_rmem[0]表示最小上限, tcp_rmem[1]表示初始上限(注意,它會覆蓋適用于所有協議的rmem_default配置), tcp_rmem[2]表示最大上限。
tcp_wmem[3]數組表示寫緩存,與tcp_rmem[3]類似,不再贅述。
tcp_mem[3]數組就用來設定TCP內存的整體使用狀況,所以它的值很大(它的單位也不是字節,而是頁--4K或者8K等這樣的單位!)。這3個值定義了TCP整體內存的無壓力值、壓力模式開啟閥值、最大使用值。以這3個值為標記點則內存共有4種情況:
1、當TCP整體內存小于tcp_mem[0]時,表示系統內存總體無壓力。若之前內存曾經超過了tcp_mem[1]使系統進入內存壓力模式,那么此時也會把壓力模式關閉。
這種情況下,只要TCP連接使用的緩存沒有達到上限(注意,雖然初始上限是tcp_rmem[1],但這個值是可變的,下文會詳述),那么新內存的分配一定是成功的。
2、當TCP內存在tcp_mem[0]與tcp_mem[1]之間時,系統可能處于內存壓力模式,例如總內存剛從tcp_mem[1]之上下來;也可能是在非壓力模式下,例如總內存剛從tcp_mem[0]以下上來。
此時,無論是否在壓力模式下,只要TCP連接所用緩存未超過tcp_rmem[0]或者tcp_wmem[0],那么都一定都能成功分配新內存。否則,基本上就會面臨分配失敗的狀況。(注意:還有一些例外場景允許分配內存成功,由于對于我們理解這幾個配置項意義不大,故略過。)
3、當TCP內存在tcp_mem[1]與tcp_mem[2]之間時,系統一定處于系統壓力模式下。其他行為與上同。
4、當TCP內存在tcp_mem[2]之上時,毫無疑問,系統一定在壓力模式下,而且此時所有的新TCP緩存分配都會失敗。
下圖為需要新緩存時內核的簡化邏輯:
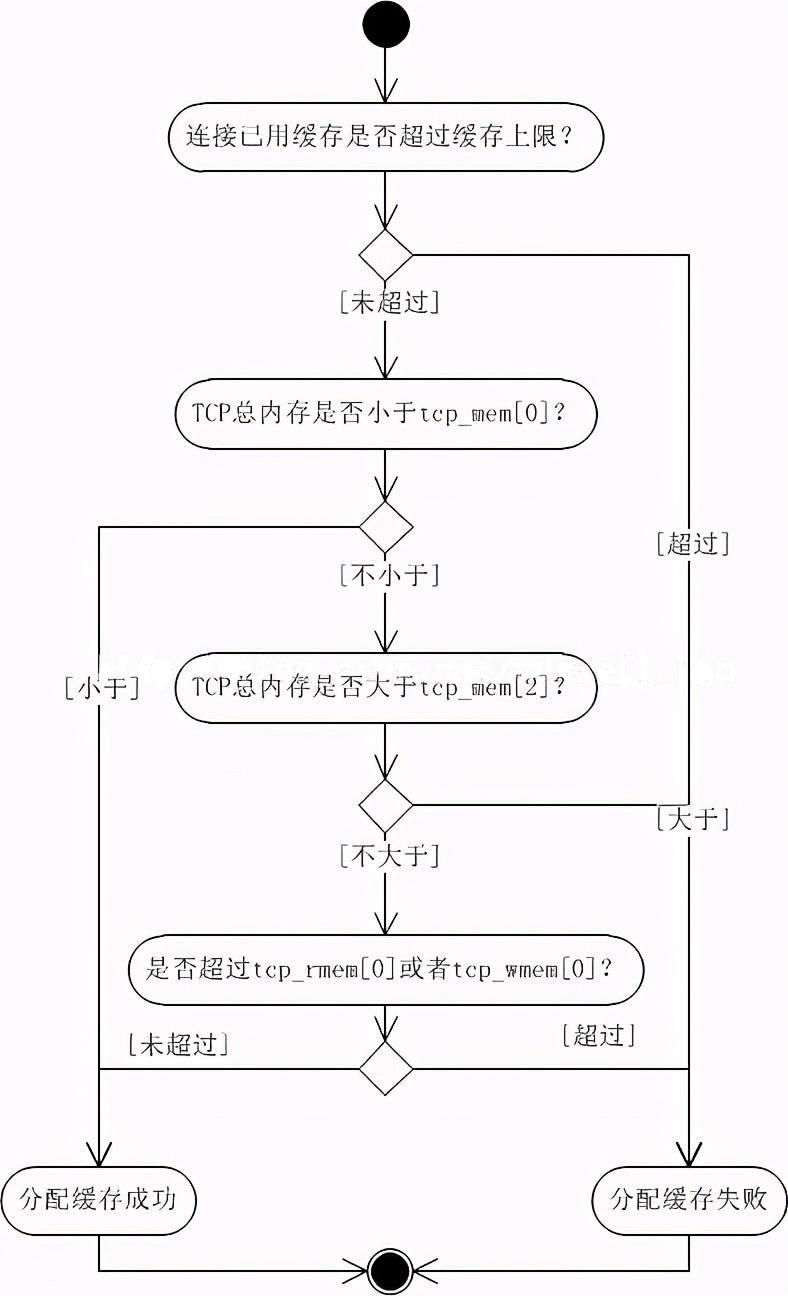
當系統在非壓力模式下,上面我所說的每個連接的讀寫緩存上限,才有可能增加,當然最大也不會超過tcp_rmem[2]或者tcp_wmem[2]。相反,在壓力模式下,讀寫緩存上限則有可能減少,雖然上限可能會小于tcp_rmem[0]或者tcp_wmem[0]。
所以,粗略的總結下,對這3個數組可以這么看:
- 只要系統TCP的總體內存超了 tcp_mem[2] ,新內存分配都會失敗。
- tcp_rmem[0]或者tcp_wmem[0]優先級也很高,只要條件1不超限,那么只要連接內存小于這兩個值,就保證新內存分配一定成功。
- 只要總體內存不超過tcp_mem[0],那么新內存在不超過連接緩存的上限時也能保證分配成功。
- tcp_mem[1]與tcp_mem[0]構成了開啟、關閉內存壓力模式的開關。在壓力模式下,連接緩存上限可能會減少。在非壓力模式下,連接緩存上限可能會增加,最多增加到tcp_rmem[2]或者tcp_wmem[2]。


























