對遷移學(xué)習(xí)中域適應(yīng)的理解和3種技術(shù)的介紹
域適應(yīng)是計算機視覺的一個領(lǐng)域,我們的目標是在源數(shù)據(jù)集上訓(xùn)練一個神經(jīng)網(wǎng)絡(luò),并確保在顯著不同于源數(shù)據(jù)集的目標數(shù)據(jù)集上也有良好的準確性。為了更好地理解域適應(yīng)和它的應(yīng)用,讓我們先看看它的一些用例。
我們有很多不同用途的標準數(shù)據(jù)集,比如GTSRB用于交通標志識別,LISA和LARA dataset用于交通信號燈檢測,COCO用于目標檢測和分割等。然而,如果你想讓神經(jīng)網(wǎng)絡(luò)很好地完成你的任務(wù),比如識別印度道路上的交通標志,那么你必須首先收集印度道路的所有類型的圖像,然后為這些圖像做標注,這是一項費時費力的任務(wù)。在這里我們可以使用域適應(yīng),因為我們可以在GTSRB(源數(shù)據(jù)集)上訓(xùn)練模型,并在我們的印度交通標志圖像(目標數(shù)據(jù)集)上測試它。
在很多情況下,很難收集數(shù)據(jù)集,這些數(shù)據(jù)集具有訓(xùn)練魯棒神經(jīng)網(wǎng)絡(luò)所需的所有變化和多樣性。在這種情況下,在不同的計算機視覺算法的幫助下,我們可以生成具有我們需要的所有變化的大型合成數(shù)據(jù)集。然后在合成數(shù)據(jù)集(源數(shù)據(jù)集)上訓(xùn)練神經(jīng)網(wǎng)絡(luò),并在真實數(shù)據(jù)集(目標數(shù)據(jù)集)上測試它。
為了更好地理解,我假設(shè)我們對目標數(shù)據(jù)集沒有可用的標注,但這不是唯一的情況。
因此在域適應(yīng)方面,我們的目標是在一個標簽可用的數(shù)據(jù)集(源)上訓(xùn)練神經(jīng)網(wǎng)絡(luò),并在另一個標簽不可用的數(shù)據(jù)集(目標)上保證良好的性能。
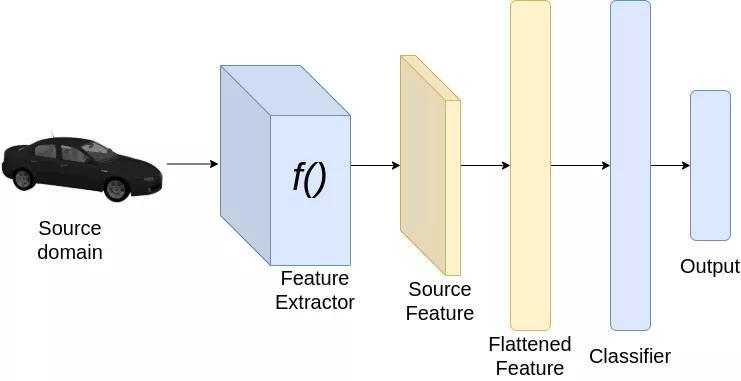
分類pipeline
現(xiàn)在讓我們看看如何實現(xiàn)我們的目標。考慮以上圖像分類的例子。為了從一個域適應(yīng)到另一個域,我們希望我們的分類器能夠很好地從源數(shù)據(jù)集和目標數(shù)據(jù)集中提取特征。由于我們已經(jīng)在源數(shù)據(jù)集上訓(xùn)練了神經(jīng)網(wǎng)絡(luò),分類器必須在源數(shù)據(jù)集上表現(xiàn)良好。然而,為了使分類器在目標數(shù)據(jù)集上表現(xiàn)良好,我們希望從源數(shù)據(jù)集和目標數(shù)據(jù)集提取的特征是相似的。因此,在訓(xùn)練時,我們加強特征提取,為源和目標域圖像提取相似的特征。
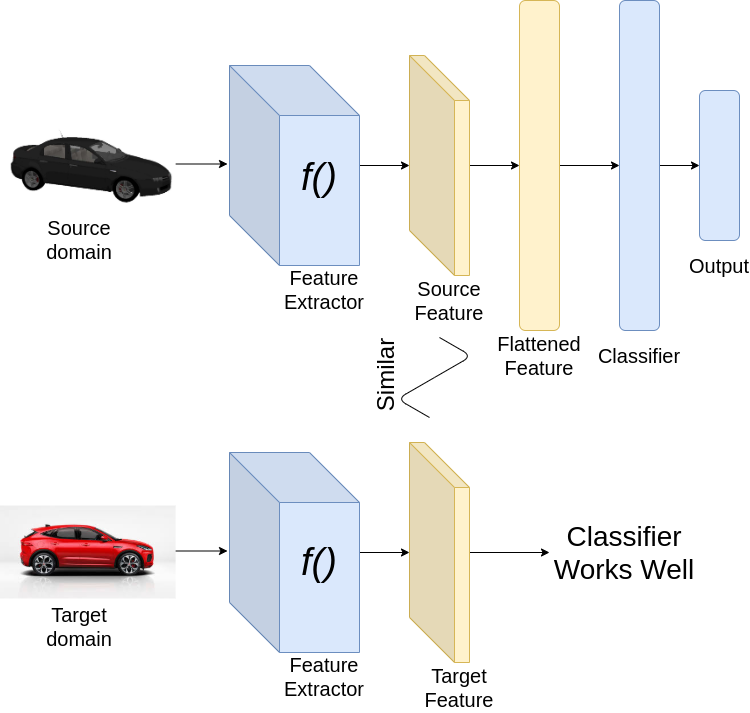
成功的域適應(yīng)
基于目標域的域自適應(yīng)類型
根據(jù)目標域提供的數(shù)據(jù)類型,域適應(yīng)可分為以下幾類:
- 監(jiān)督 — 你已經(jīng)標記了來自目標域的數(shù)據(jù),目標域數(shù)據(jù)集的大小比源數(shù)據(jù)集小得多。
- 半監(jiān)督 — 你既有目標域的標記數(shù)據(jù)也有未標記數(shù)據(jù)。
- 無監(jiān)督的 — 你有很多目標域的未標記樣本。
域適應(yīng)技術(shù)
主要采用三種技術(shù)實現(xiàn)任意域適應(yīng)算法。以下是域適應(yīng)的三種技術(shù):
- 基于分布的域適應(yīng)
- 基于對抗性的域適應(yīng)
- 基于重建的域適應(yīng)
現(xiàn)在讓我們逐個來看每種技術(shù)。
基于分布的域適應(yīng)
基于散度的域適應(yīng)原理是最小化源與目標分布之間的散度準則,從而得到域不變性特征。常用的分布準則有對比域描述、相關(guān)對齊、最大平均差異(MMD),Wasserstein等。為了更好地理解這個算法,讓我們先看看一些不同的分布。
在最大平均差異(MMD)中,我們試圖找出給定的兩個樣本是否屬于相同的分布。我們將兩個分布之間的距離定義為平均嵌入特征之間的距離。如果我們有兩個在集合X上的分布P和Q。MMD通過一個特征映射來定義,: X→H,這里H再生核希爾伯特空間。MMD的公式如下:
為了更好地了解MMD,請查看以下描述:如果兩個分布的矩相似,則它們是相似的。通過使用kernel,我可以對變量進行變換,從而計算出所有的矩(一階,二階,三階等)。在潛在空間中,我可以計算出矩之間的差值并求其平均值。
在相關(guān)對齊中,我們嘗試對源和目標域之間的相關(guān)(二階統(tǒng)計量)進行對齊,而不是使用MMD中的線性變換對均值進行對齊。
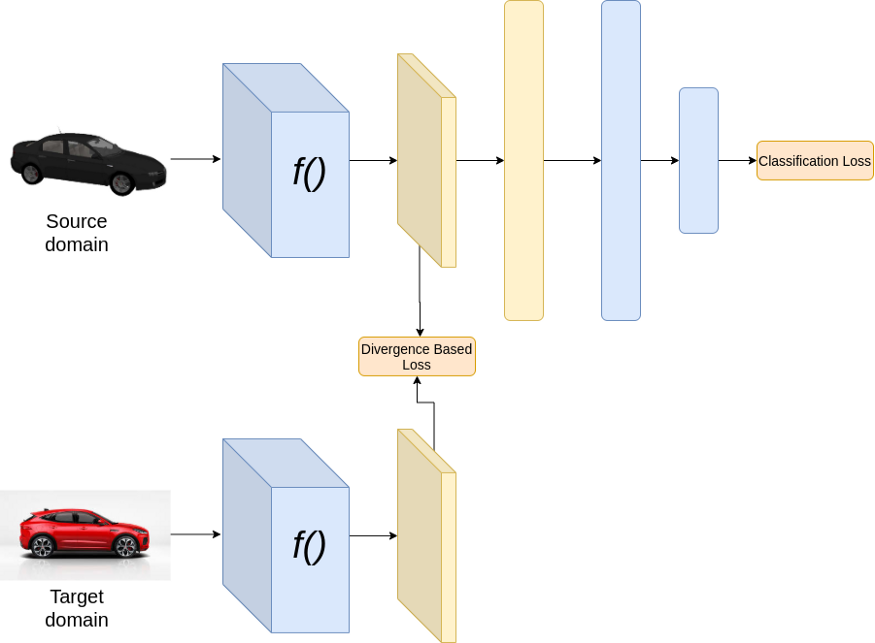
訓(xùn)練時
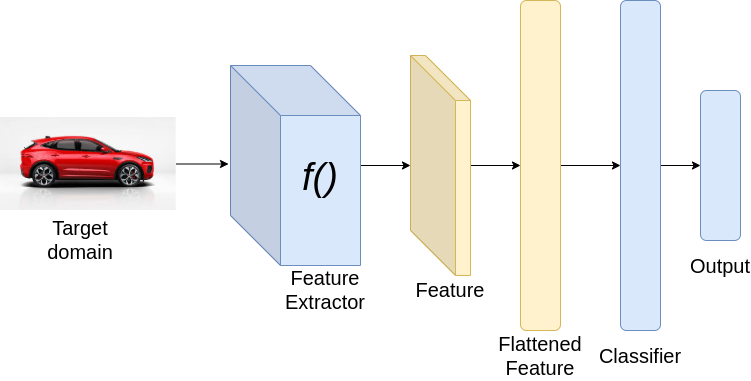
推理時
上面的結(jié)構(gòu)假設(shè)源域和目標域有相同的類別。在上述架構(gòu)中,在訓(xùn)練過程中,我們最小化了兩種損失,分類損失和基于散度的損失。分類損失通過對特征提取器和分類器的權(quán)值進行更新,確保獲得良好的分類性能。而散度損失則通過更新特征提取器的權(quán)值來保證源域和目標域的特征相似。在推理過程中,我們只需將目標域圖像通過神經(jīng)網(wǎng)絡(luò)。
所有的分布通常是非參數(shù)而且是人工的數(shù)學(xué)公式,不是專門針對數(shù)據(jù)集或我們的問題的,如分類,目標檢測,分割等。因此,這種基于分布的方法并不能很好地解決我們的問題。但是,如果分布可以通過數(shù)據(jù)集或問題來學(xué)習(xí),那么它將比傳統(tǒng)的預(yù)定義分布表現(xiàn)得更好。
基于對抗的域適應(yīng)
為了實現(xiàn)基于對抗性的域適應(yīng),我們使用GANs。這里我們的生成器是簡單的特征提取器,我們添加了新的判別器網(wǎng)絡(luò),學(xué)習(xí)區(qū)分源和目標域的特征。由于這是一個雙人游戲,判別器幫助生成器產(chǎn)生的特征對于源和目標領(lǐng)域是不可區(qū)分的。由于我們有一個可學(xué)習(xí)的判別器網(wǎng)絡(luò),我們學(xué)習(xí)特定于我們的問題和數(shù)據(jù)集的特征提取,這可以幫助區(qū)分源和目標域,從而幫助生成器產(chǎn)生更魯棒的特征,即,不能很容易區(qū)分的特征。
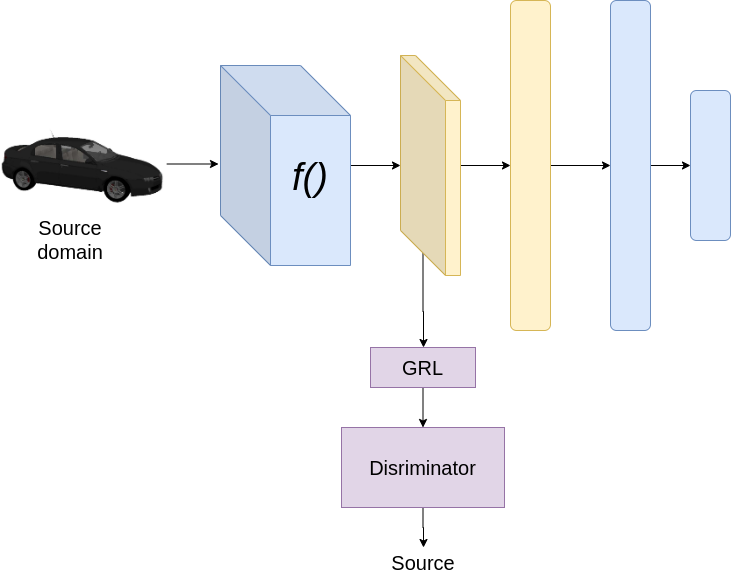
訓(xùn)練時,在源域上
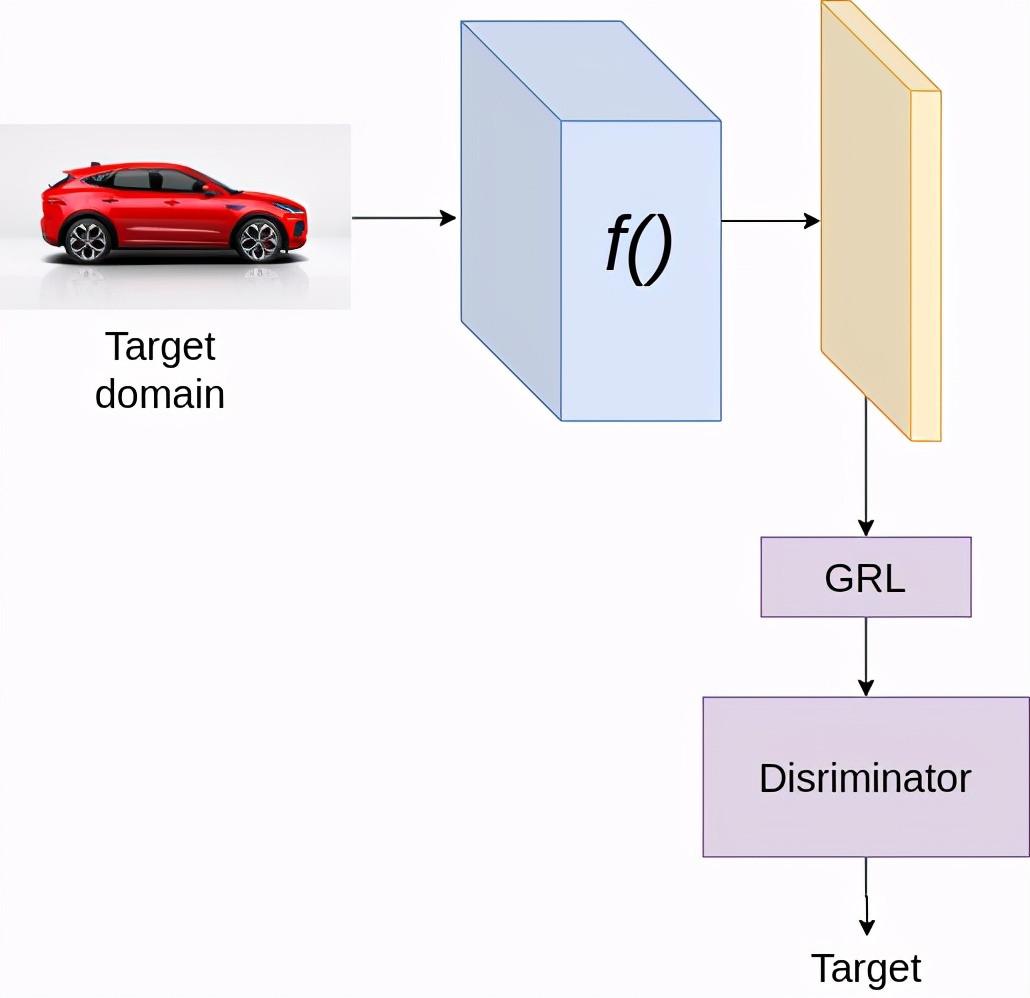
訓(xùn)練時,在目標域上
假設(shè)是分類問題,我們使用兩種損失,分類損失和判別器損失。分類損失的目的已在前面說明。判別器損失有助于判別器正確地區(qū)分源域和目標域的特征。這里我們使用梯度反向?qū)?GRL)來實現(xiàn)對抗性訓(xùn)練。GRL block是一個簡單的block,它在反向傳播時將梯度乘以-1或一個負值。在訓(xùn)練過程中,為了更新生成器,我們有來自兩個方向的梯度,首先來自分類器,其次來自判別器。由于GRL的存在,判別的梯度乘以一個負值,導(dǎo)致訓(xùn)練生成器的效果與判別器相反。例如,如果優(yōu)化判別器損失函數(shù)的計算梯度為2,那么我們使用-2(假設(shè)負值為-1)來更新生成器。通過這種方式,我們試圖訓(xùn)練生成器,使其生成即使是判別器也無法區(qū)分源域和目標域的特征。GRL層在許多域適應(yīng)的文獻中都有廣泛的應(yīng)用。
基于重建的域適應(yīng)
這是基于圖像到圖像的轉(zhuǎn)換。一個簡單的方法是學(xué)習(xí)從目標域圖像到源域圖像的轉(zhuǎn)換,然后在源域上訓(xùn)練一個分類器。我們可以用這個想法引入多種方法。圖像到圖像轉(zhuǎn)換的最簡單模型可以是基于編碼器-解碼器的網(wǎng)絡(luò),并使用判別器強制編碼器 — 解碼器網(wǎng)絡(luò)生成與源域相似的圖像。
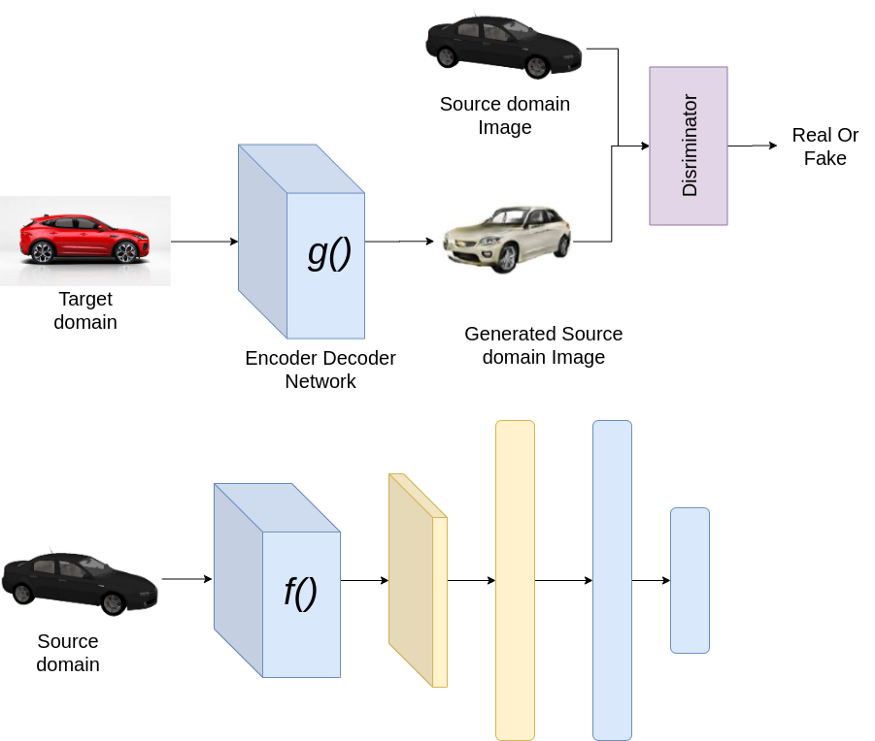
訓(xùn)練時
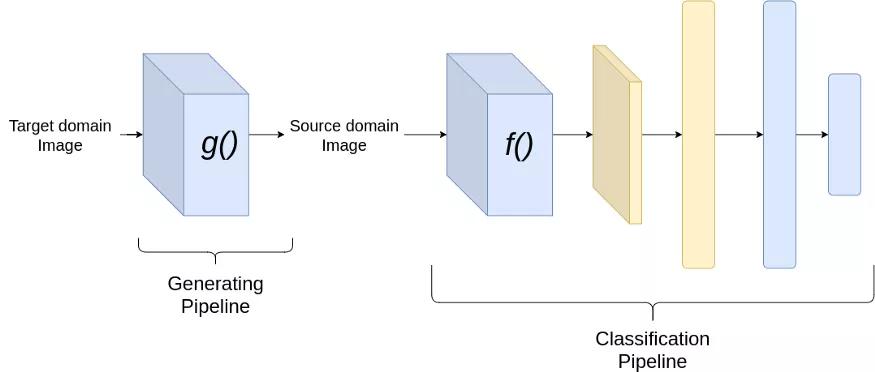
測試時
另一種方法是使用CycleGANs。在Cycle GAN中采用了基于兩種編解碼器的神經(jīng)網(wǎng)絡(luò)。一個用于將目標轉(zhuǎn)換為源域,另一個用于將源轉(zhuǎn)換為目標域。我們同時訓(xùn)練了生成兩個域(源域和目標域)圖像的GANs。為了保證一致性,引入了循環(huán)一致性損失。這可以確保從一個域轉(zhuǎn)換到另一個域,然后再轉(zhuǎn)換回來,得到與輸入大致相同的圖像。因此,兩個配對網(wǎng)絡(luò)的總損失和是判別器損失與循環(huán)一致性損失的和。
總結(jié)
我們已經(jīng)看到了三種不同的技術(shù),可以幫助我們實現(xiàn)或?qū)嵤┎煌挠蜻m應(yīng)方法。它在圖像分類、目標檢測、分割等不同任務(wù)中都有很大的應(yīng)用。在某些方面,我們可以說,這種方法類似于人類如何學(xué)習(xí)視覺識別不同的東西。我希望這個博客能讓你了解我們是如何思考不同的域適應(yīng)pipelines的。
英文原文:https://levelup.gitconnected.com/understanding-domain-adaptation-63b3bb89436f