













無人駕駛:如何使用立體視覺實現距離估計?
在自動化系統中,深度學習和計算機視覺已經瘋狂地流行起來,無處不在。計算機視覺領域在過去十年中發展迅速,尤其是是障礙物檢測方面。
障礙物檢測算法,如YOLO或RetinaNet,提供2D的標注框,該標注框指明了障礙物在圖像中的位置。
為了獲取每個障礙物的距離,工程師將相機與激光雷達(光探測和測距)傳感器融合,使用激光返回深度信息。利用傳感器融合技術將計算機視覺和激光雷達的輸出融合在一起。
使用激光雷達這種方式存在價格昂貴的問題。而對此,工程師使用的一個有用的技巧是:對齊兩個像機,并使用幾何原理來計算每個障礙物的距離。我們稱這種新設置為 偽激光雷達。

單目視覺和立體視覺
偽激光雷達利用幾何原理構造深度圖,并將其與物體探測相結合,以獲得三維的距離。
如何利用立體視覺實現距離估計?
以下5步偽代碼用于獲取距離:
- 校準2臺照相機(內部和外部校準)
- 創建極線方案
- 先建立視差圖,再建立深度圖
然后,深度圖將與障礙檢測算法結合在一起,我們將估算邊界框像素的深度。本文結尾處有更多內容。
開始吧!
1.內部和外部校準
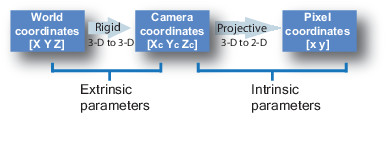
每個攝像機都需要校準。校準意味著將具有[X,Y,Z]坐標的3D點(世界上)轉換為具有[X,Y]坐標的2D像素。
相機型號
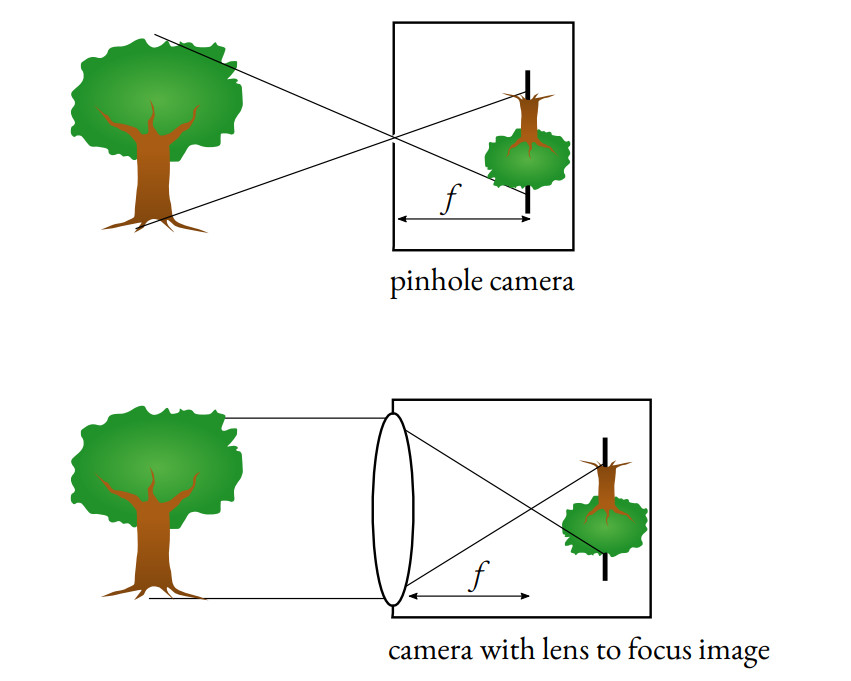
當今的相機使用針孔相機模型。
這個想法是使用針孔讓少量光線穿過相機,從而獲得清晰的圖像。
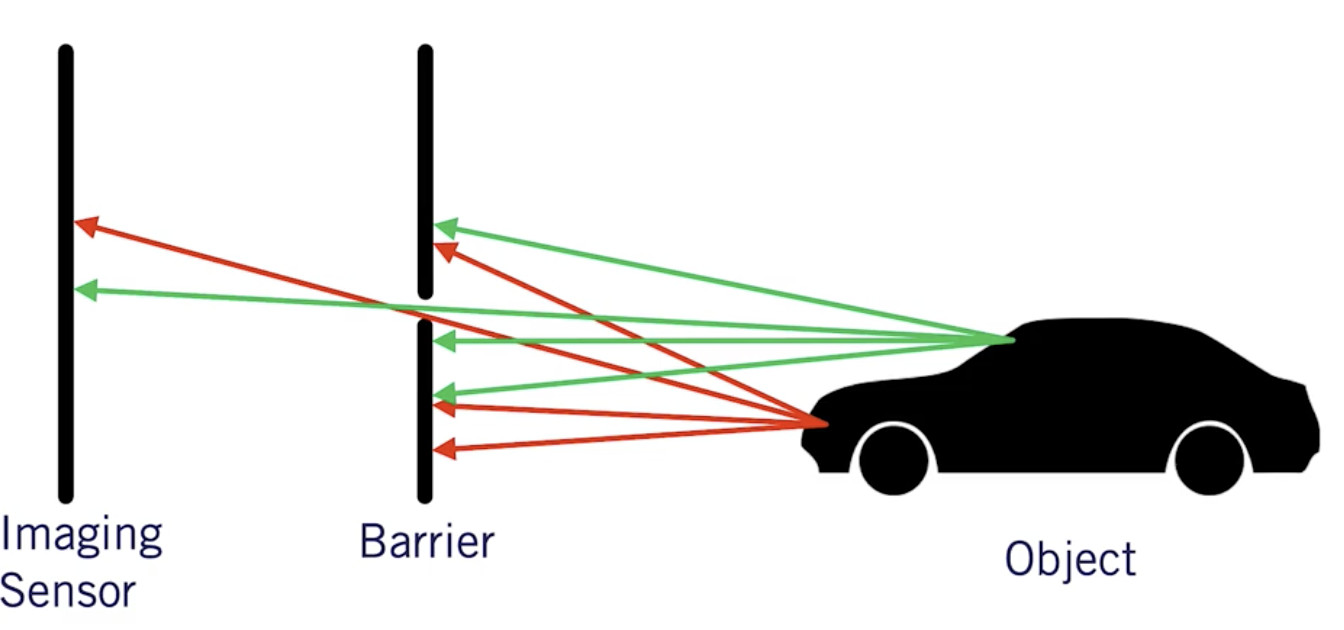
如果圖像中間沒有障礙物,那么每條光線都會通過,圖像會變得模糊。它還使我們能夠確定用于變焦和更好清晰度的焦距f。
要校準相機,我們需要將世界坐標轉換為通過相機坐標的像素坐標。
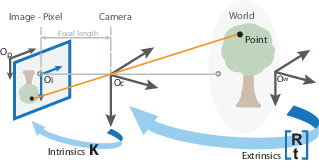
相機校準過程
從世界坐標到攝像機坐標的轉換稱為外部校準。外在參數稱為R(旋轉矩陣)和T(平移矩陣)。
從相機坐標到像素坐標的轉換稱為固有校準。它需要相機的內部值,例如焦距,光學中心等。
固有參數是我們稱為K的矩陣。
校準
過相機校準可以找到K矩陣。
通常,我們使用棋盤格和自動算法來執行它。 當我們這樣做時,我們告訴算法棋盤上的一個點(例如:0,0,0)對應于圖像中的一個像素(例如:545、343)。

校準示例
為此,我們必須使用相機拍攝棋盤格的圖像,并且在經過一些圖像和某些點之后,校準算法將通過最小化最小二乘方損失來確定相機的校準矩陣。
通常,必須進行校準才能消除圖像失真。 針孔攝像頭模型包括變形,即“ GoPro效果”。 為了獲得校正的圖像,必須進行校準。 變形可以是徑向的或切向的。 校準有助于使圖像不失真。

圖像校準
以下是相機校準返回的矩陣:
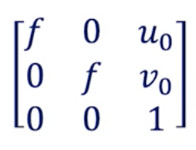
f是焦距-(u₀,v₀)是光學中心:這些是固有參數。
每一個計算機視覺工程師都必須了解和掌握攝像機的標定。這是最基本、最重要的要求。我們習慣于在線處理圖像,從不接觸硬件,這是個錯誤。
-嘗試運行OpenCV進行攝像機校準。
同類坐標
在相機校準過程中,我們有兩個公式可以將世界上的點O設為像素空間:
world到相機的轉換
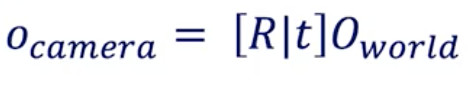
外在校準公式
相機到圖像的轉換
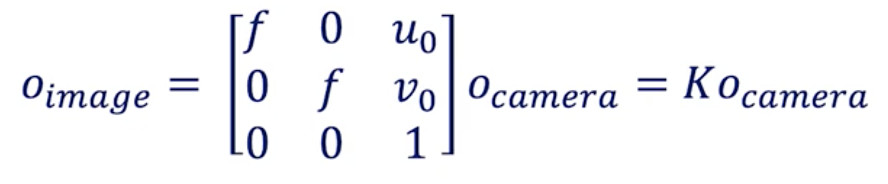
內部校準公式
當您進行數學運算時,您將得出以下等式:
world到圖像的轉換

如果您查看矩陣尺寸,則不匹配。
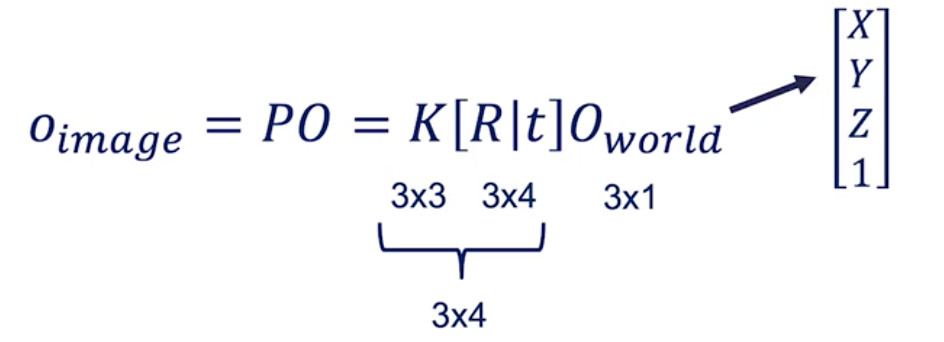
因此,我們需要將O_world從[X Y Z]修改為[X Y Z 1]。
該“ 1”稱為齊次坐標。
2.極線幾何--立體視覺
立體視覺是基于兩張圖像來尋找深度。
我們的眼睛就像兩個相機。因為它們從不同的角度看同一幅圖像,它們可以比對兩種視角之間的差異,并計算出距離估計。
下面是立體相機設置的示例。你會在大多數自動駕駛汽車上發現類似的東西。

立體相機如何估算深度
假設你有兩個相機,一左一右。這兩個相機在相同的Y軸和Z軸上對齊。基本上,唯一的區別就是它們X值不一樣。
現在,看看下面的描述。
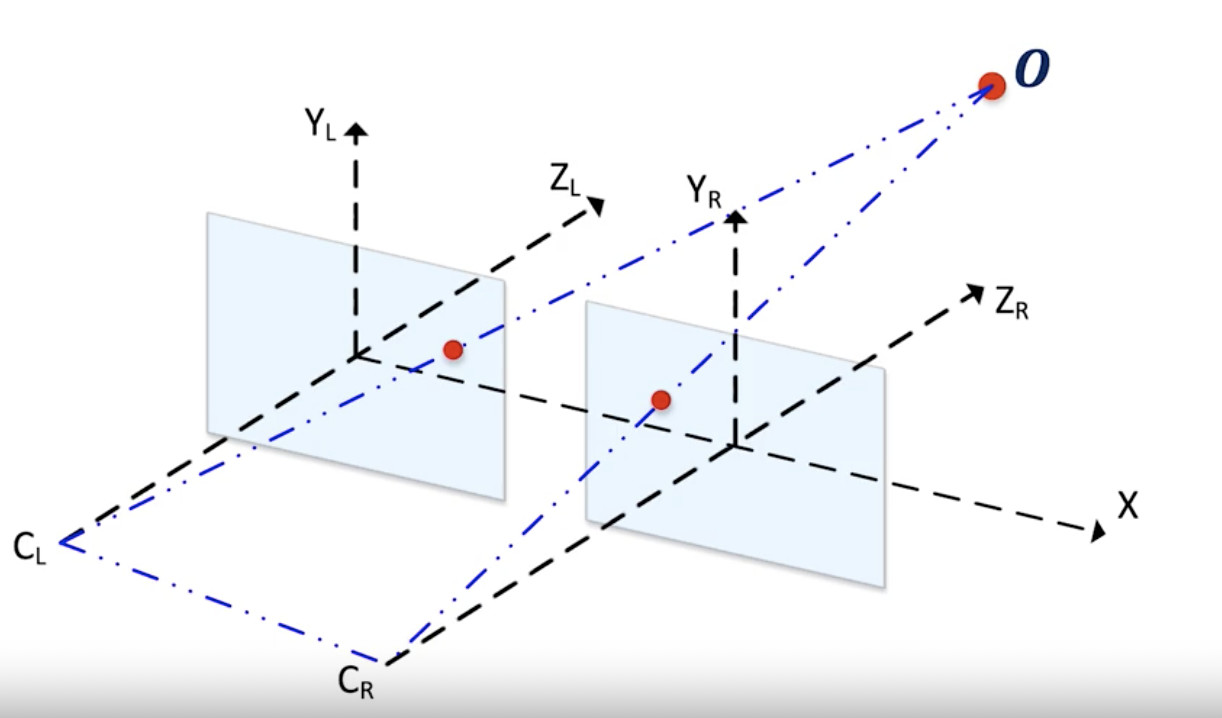
立體相機簡圖
我們的目標是估算出O點(代表圖像中的任何像素)的Z值,即深度距離。
- X 為對齊軸;
- Y 為高度;
- Z 為深度;
兩個藍色平面對應于來自兩個相機的圖像。
現在從鳥瞰的角度來考慮這個問題。
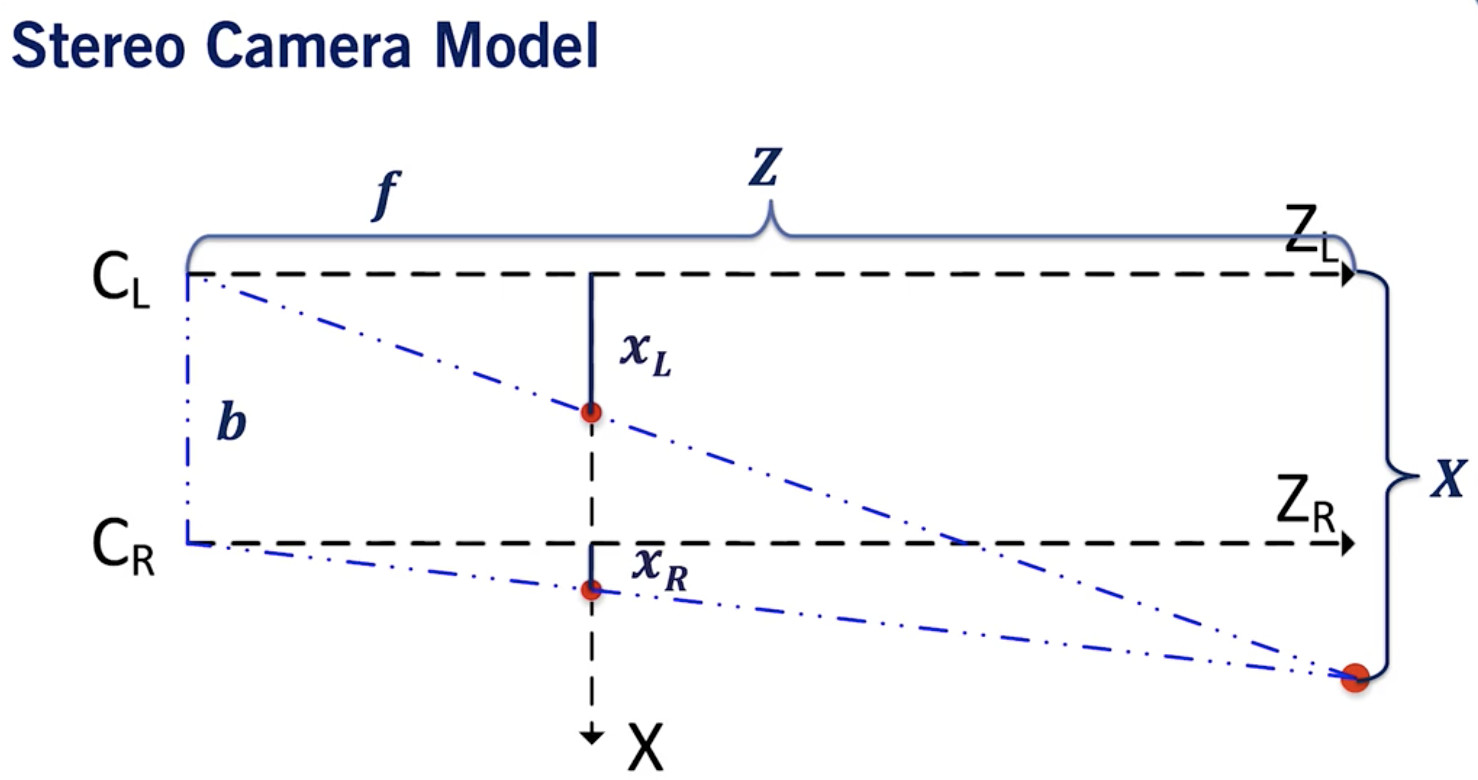
立體相機鳥瞰圖說明:
- xL 對應于左相機中的光心,xR對應于右相機中的光心。
- b 是基線,它是兩個相機之間的距離。
如果你運用泰勒斯定理,你會發現我們可以得到兩個方程
對于左邊相機:
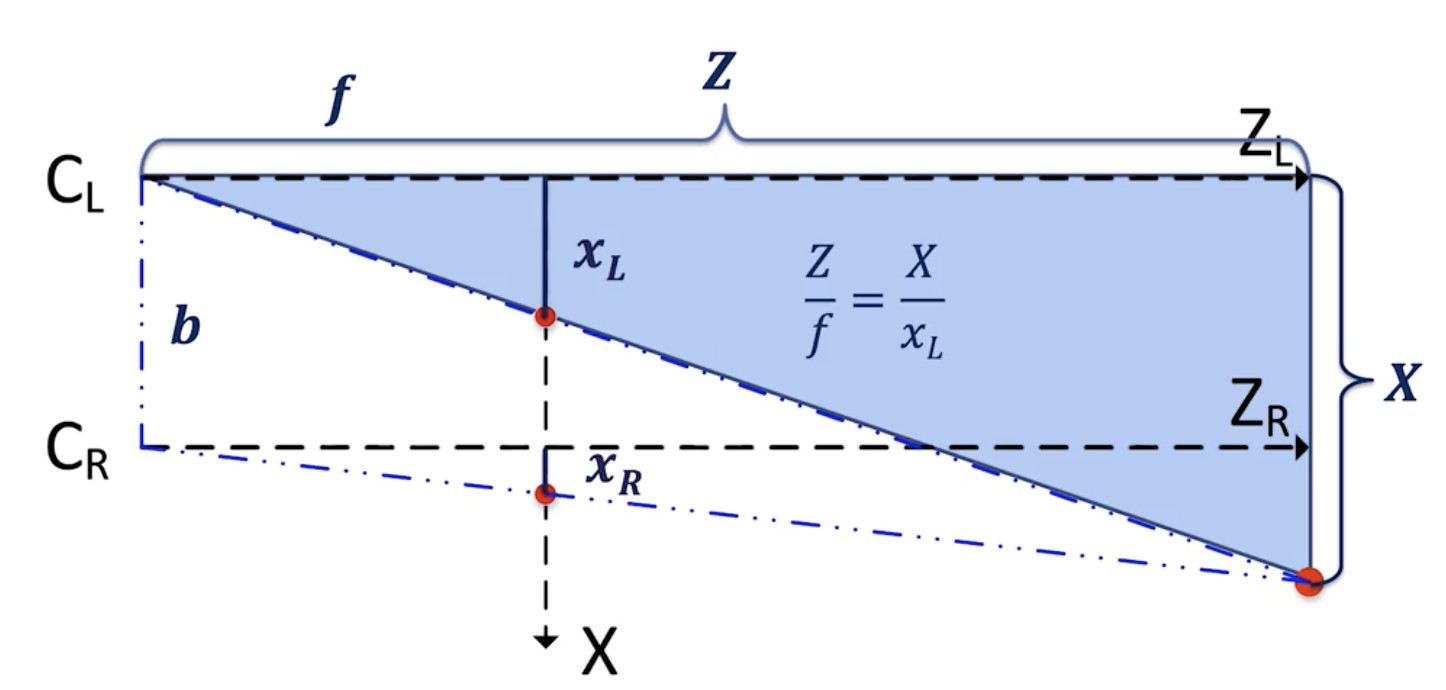
左相機方程
? 我們得到 Z = X*f / xL.
- 對于右邊相機:
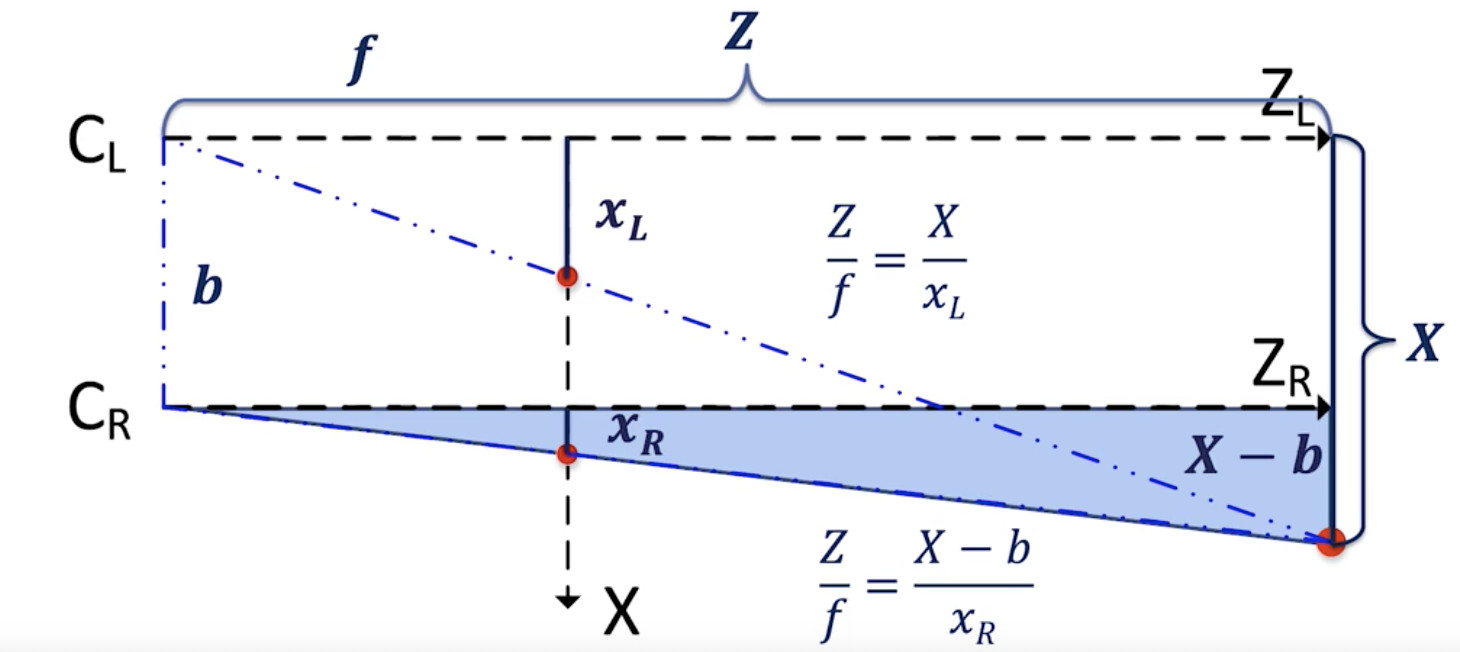
右相機方程:
- ? 我們獲得 Z = (X — b)*f/xR.
放在一起,我們可以找到正確的視差 d =xL -- xR和目標正確的 XYZ 坐標。
3. 視差與深度圖
視差是什么?視差是一個三維點從兩個不同的相機角度在圖像中位置的差異。
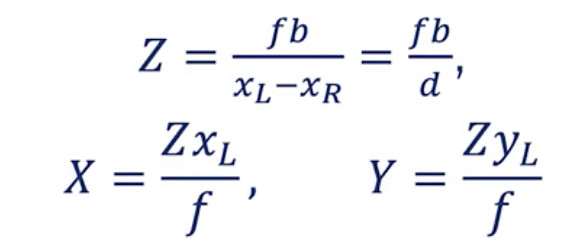
立體視覺公式
? 由立體視覺我們可以估計任何物體的深度。假設我們做了正確的矩陣校準。它甚至能夠計算一個深度映射或者視差映射。

視差圖
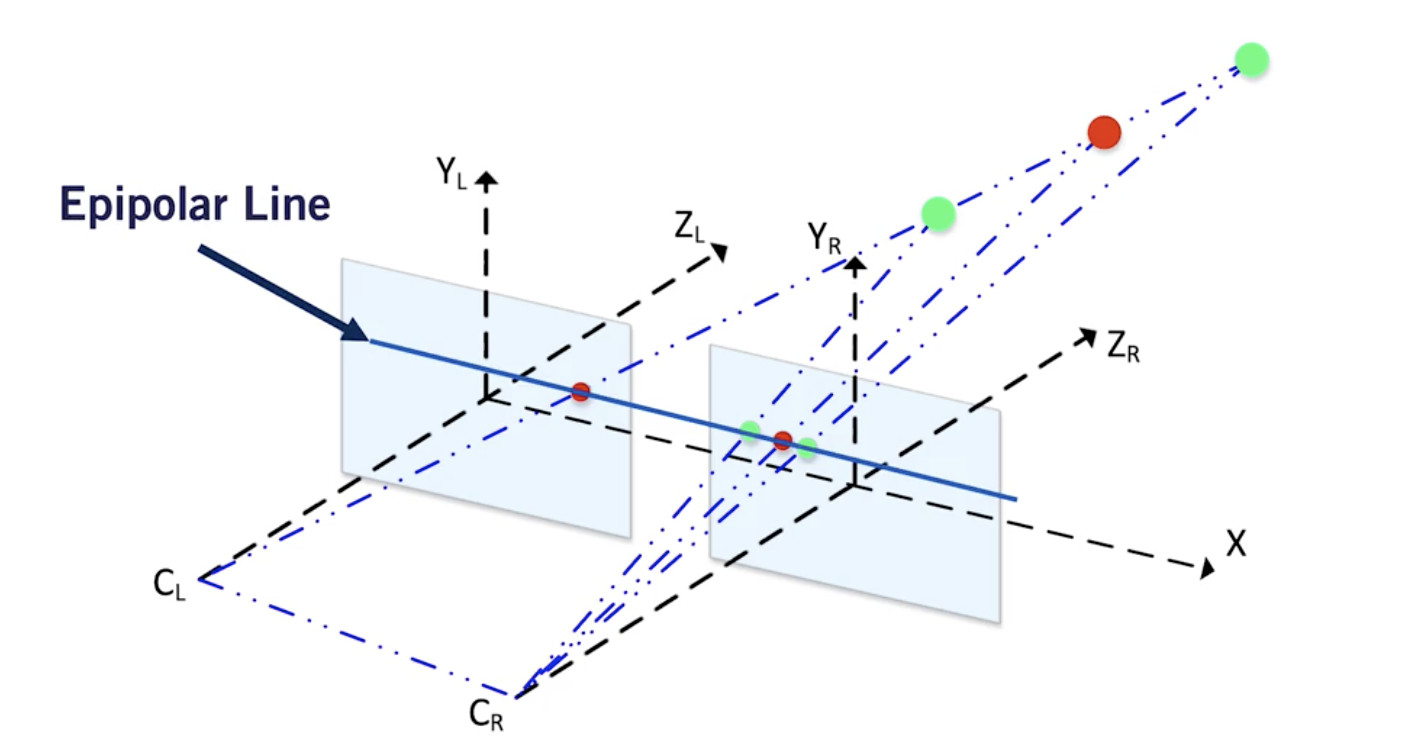
為什么是“基線幾何”?
要計算視差,我們必須從左圖像中找到每個像素,并將其與右圖像中的每個像素進行匹配。 這稱為立體對應問題。
為了解決這個問題--
- 現在在左邊的圖像中取一個像素
- 要在右邊的圖像中找到這個像素,只需在基線上搜索它。沒有必要進行2D搜索,點應該位于這條線上,搜索范圍縮小到 1D。
基線
這是因為兩個相機是沿著同一軸對齊的。
以下是基線搜索的工作原理:

應用:建立偽激光雷達
現在,是時候將這些應用到真實世界的場景中,看看我們如何用立體視覺來估計物體的深度。
考慮兩張圖片--
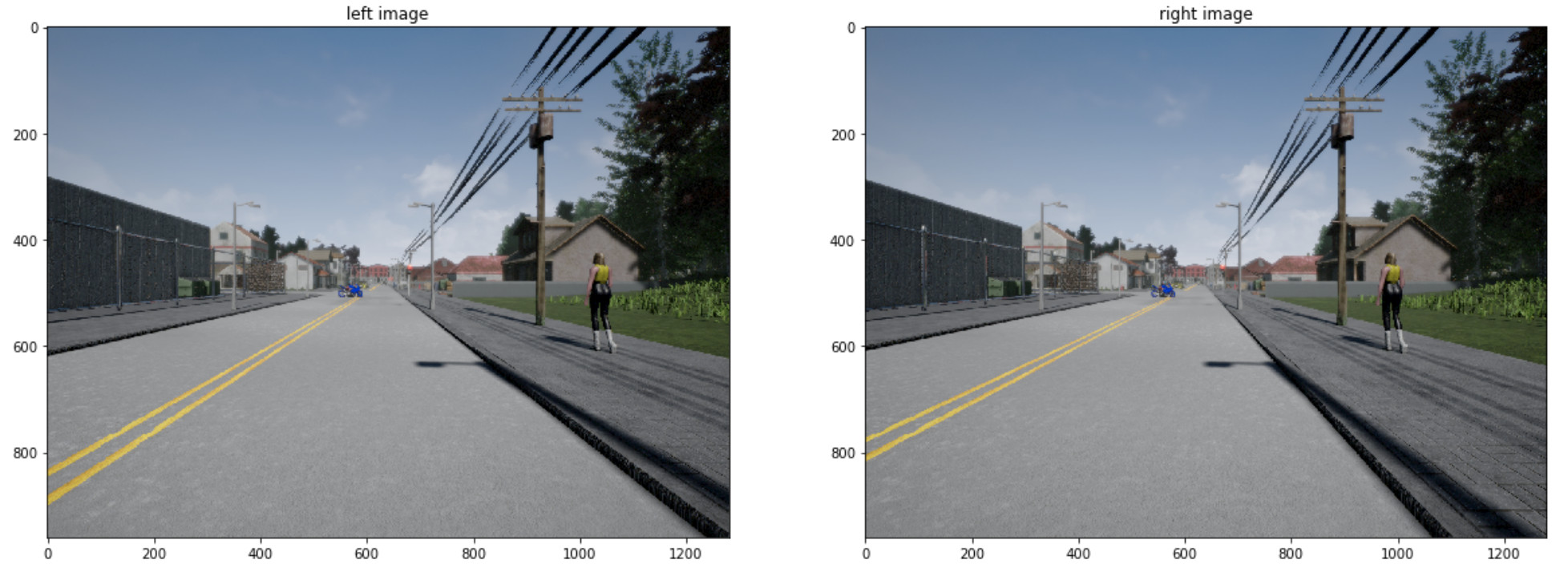
立體視覺
每一幅圖像都有外部參數 R 和 t,事先通過校準確定(步驟1)。
視差
對于每一幅圖像,我們可以計算相對于另一幅圖像的視差圖。我們將做如下操作:
- 確定兩幅圖像之間的視差。
- 投影矩陣分解成相機的內在矩陣 K和外在矩陣 R,t。
- 利用我們在前面兩個步驟中收集到的數據估算深度。
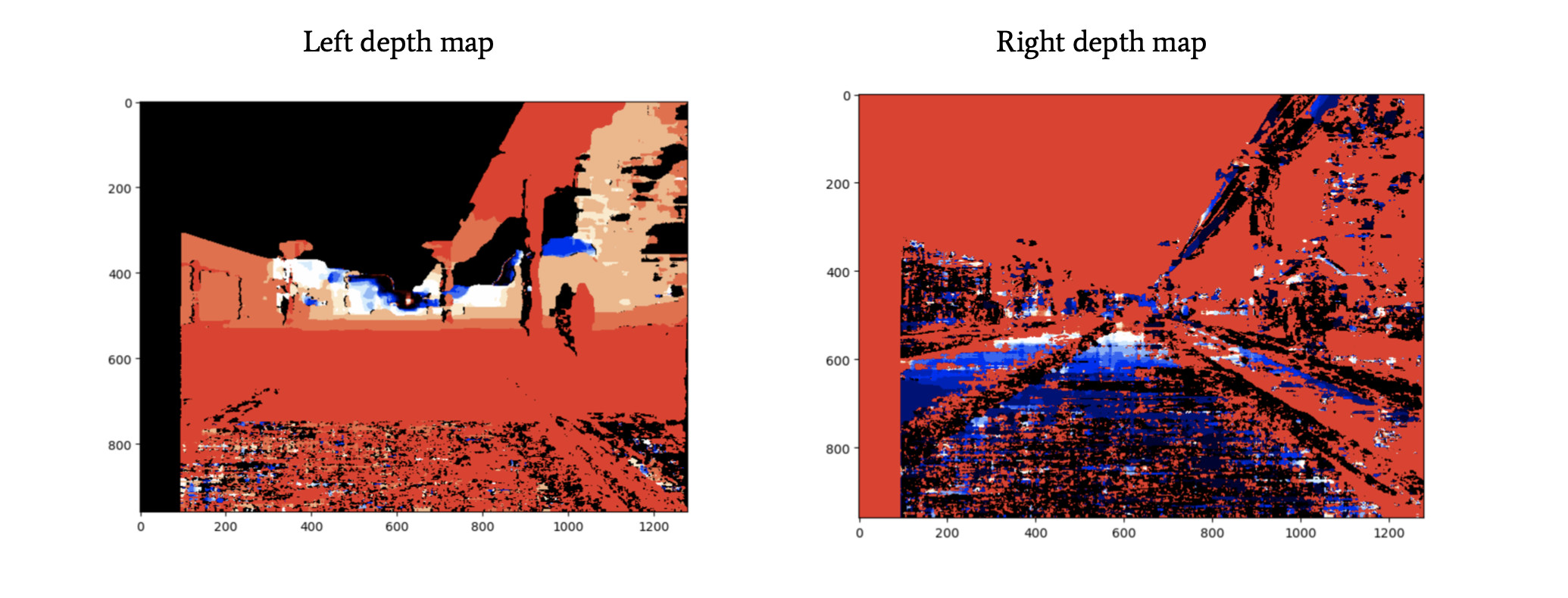
我們將獲得左右圖像的視差圖。
為了幫助您更好地理解差異的含義,我在 Stack Overflow 上找到了一個很棒的解釋。
視差圖是指一對立體圖像之間的明顯像素差或運動。
要體驗這一點,試著閉上你的一只眼睛,迅速閉上,同時睜開另一只。離你很近的物體看起來會跳躍一段很長的距離,而離你很遠的物體幾乎不會移動。這個運動就是視差。在一對來自立體攝像機的圖像中,你可以測量每個點的視運動像素,并根據測量結果制作出一個強度圖像。

從視差到深度圖
? 我們有兩個視差圖,這基本上告訴我們,兩幅圖像之間的像素位移是多少。
對于每個攝像機,都有一個投影矩陣 P_left 和 P_right。為了估計深度,我們需要估計K, R 和 t。

世界坐標系到相機坐標系的轉換一個名為
cv2.decomposeProjectionMatrix()的OpenCV函數可以做到這一點,并從 P 中得到 K、R 和 t;對于每個相機,現在是時候生成深度圖了。深度圖將使用其他圖像和視差圖告訴我們圖像中每個像素的距離。
這個過程如下:
- 從矩陣 K 獲得焦距 f;
- 使用轉換向量 t 中的相應值來計算基線 ?;
- 使用之前的公式和視差圖 d 計算圖像的深度圖;

立體視覺公式
我們對每個像素進行計算。
估計障礙物的深度
針對每個相機,我們都有一個深度圖! 現在,假設我們將其與障礙檢測算法(例如YOLO)結合在一起。 對于每個障礙,這種算法都會返回帶有4個數字的邊界框:[x1; y1; x2; y2]。 這些數字表示框的左上角和右下角的坐標。
例如,我們可以在左邊的圖像上運行這個算法,然后使用左邊的深度圖。
現在,在這個邊界框中,我們可以取最近的點。我們知道它,因為我們知道圖像中每個點的距離。邊界框中的第一個點是我們到障礙物的距離。

真不可思議!我們剛剛構建了偽激光雷達!
借助立體視覺,我們不僅知道圖像中的障礙物,而且知道它們與我們的距離! 這個障礙距離我們28.927米!
立體視覺是一種使用簡單的幾何圖形和一個額外的攝像機將2D障礙物檢測轉換為3D障礙物檢測的技術。如今,大多數新興的edge平臺都考慮了立體視覺,比如新的OpenCV AI Kit或對Raspberry和Nvidia Jetson卡的集成。
在成本方面,與使用LiDAR相比,它保持相對便宜,并且仍具有出色的性能。我們稱它為偽激光雷達,因為它可以取代激光雷達的功能。檢測障礙物,對障礙物進行分類,并在3D中進行定位。
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。












