就算戴上口罩,AI也知道你在說啥
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
吃飯的時候,想要和對面聊聊天,然而周遭嘈雜的聲音,讓你根本不知道ta在說什么?
又或者,想與聽障人士交流,然而對方聽不見你的聲音?
現在,檢測面部肌肉變化的AI來了,只要你動了嘴,哪怕沒出聲,它也能知道你在說什么。
這是EMNLP 2020的最佳論文,來自UC伯克利的兩位作者,用AI和電極做了個“沉默語音”的檢測模型,可以檢測到你想說、但沒說出聲的話。

其中的原理究竟是什么,我們來一探究竟。
用電極收集你小聲嗶嗶的證據
“無聲語音”的本質,是人在說話時面部、頸部肌肉的變化。
說白了,你在對口型時雖然沒有出聲,但你的臉和脖子“出賣”了你。
而能夠檢測“無聲語音”的AI,也正是這么被做出來的。
在收集數據時,研究者會先在實驗者的臉上等部位貼8個貼片,每個貼片都是一個“監視肌肉變化”的傳感器,像這樣:
在這之后,需要錄制一段實驗者的有聲語音,并與肌電圖進行對應,如下圖(會錄制兩種語音數據,一種每句話4個詞左右,另一種每句話16個詞左右):

這種方法能夠將肌肉的變化情況、和語音的類型對應起來。
在記錄數據的過程中,還要再錄制一段“對口型”的肌電圖,但不需要發聲,也就是“沉默語音”。
之所以要收集兩份肌電圖,是因為人在無聲說話時,肌肉的變化與發聲說話時的變化有些區別,例如部分發音部位的肌肉震顫幅度會變小,語速也有所變化。
但如果要在無聲環境下,根據肌肉變化識別出想說的語音,就只能用對口型時的無聲肌電圖。
顯然,這些原因使得AI的訓練變得非常困難。
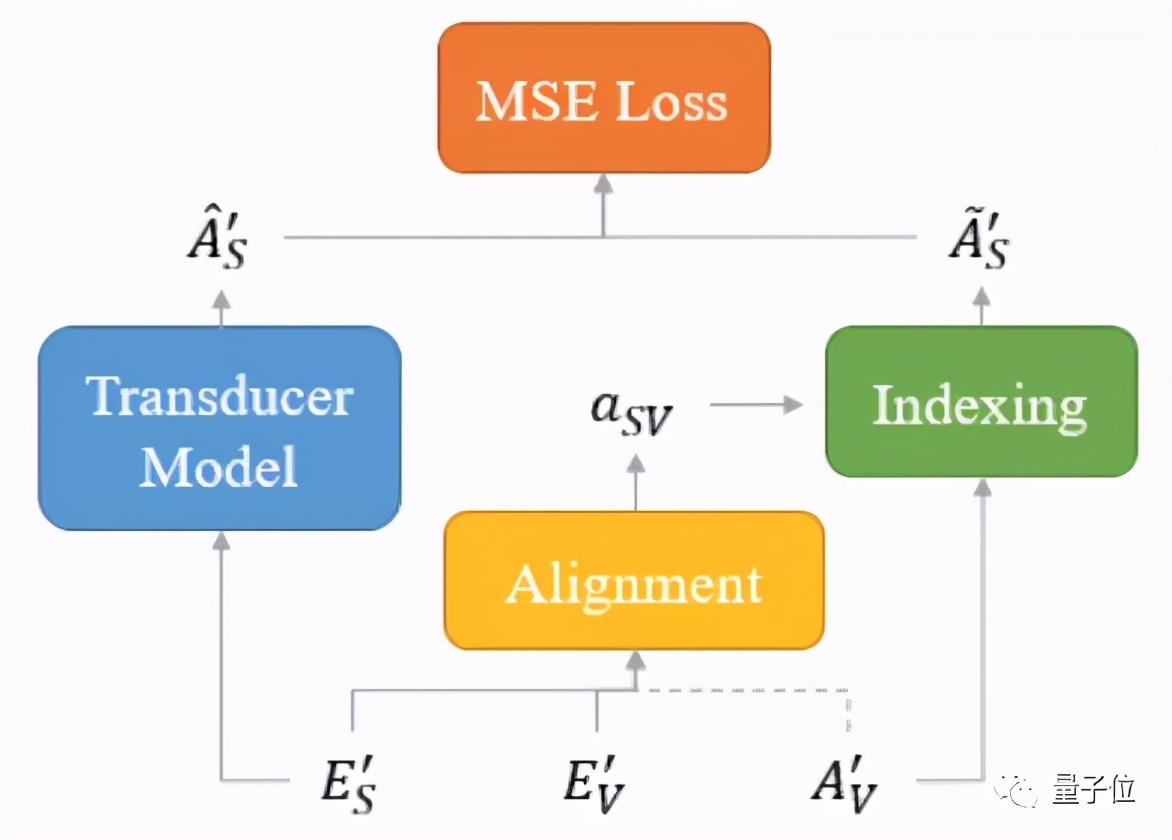
為了盡可能將識別準確率放大,研究人員額外采用了一種結構來降低模型損失。
不到20小時的語音集,效果還不錯
那么,經由這種方法訓練出來的模型,效果怎么樣?
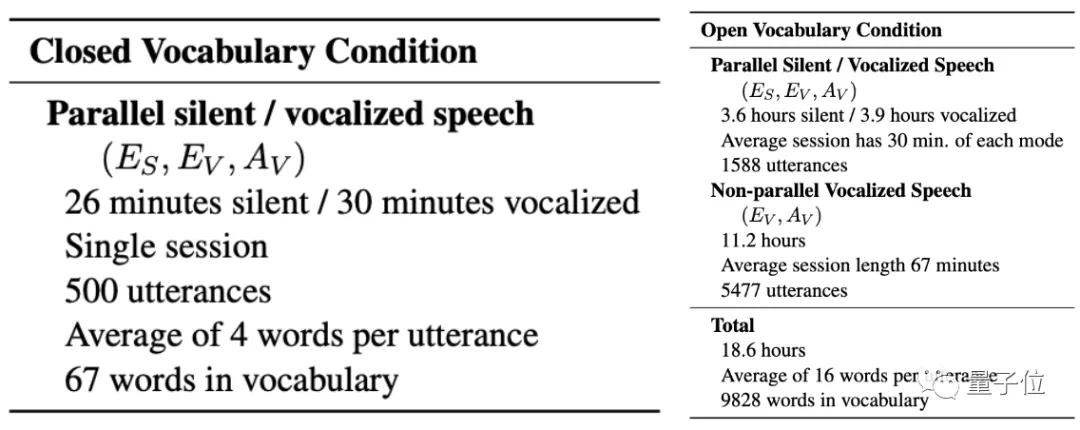
研究人員分別在封閉詞集 (Closed Vocabulary Condition)和開放詞集 (Open Vocabulary Condition)上,對這種模型進行了測試。
其中,封閉詞集主要指介詞、限定詞、連詞等詞匯(如of、and),這種詞匯集合少,容易訓練,AI也容易形成“肌肉記憶”。

而開放詞集的范圍,就要廣泛得多了,包含名詞、形容詞等等詞匯,目前的詞語可以說是不計其數,想要讓AI會認這些詞匯,難度就要高得多。
判定的方式,是WER,具體的計算方式是這樣的(原理類似于計算原句的出錯率):
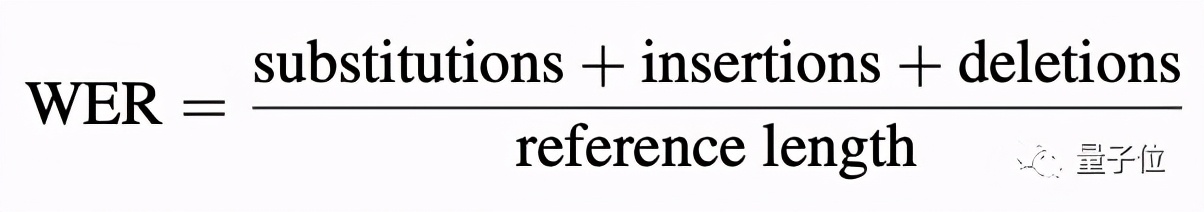
目前,這個AI在封閉詞集上的訓練水平已經達到了3.6%的WER(越小越好):

至于開放詞集的檢測,AI經過訓練后,WER也從高達88%的水平下降到了68%。

雖然在開放詞集上的檢測,看起來效果并不完美,但別忘了,這個模型所用的數據集并不大。
封閉檢測數據集,一共只有不到1小時的語音數據;開放檢測數據集,也只有18.6個小時的語音集。
而且,這些語音集還是無聲、有聲數據的合集。
不到20個小時的語音數據,訓練效果就已經達到了這種水平。
如果能獲得更大的數據樣本,模型的效果還會進一步提升。
作者介紹
一作David Gaddy,來自UC伯克利的NLP組。平時的研究方向是無監督學習、語法分析和無聲演講。
Daniel Klein,一作的導師,研究方向主要是無監督學習、語法分析、信息提取和機器翻譯。
One More Thing
這屆EMNLP的各種NLP研究,簡直不留活路:
來自北京中科院、北京信息工程學院的研究者,還發明了一種諷刺檢測模型。
這種AI模型會通過同時檢測文本和圖像,進行多模態語義理解,從而檢測出一個人在社交媒體上發出的動態,是否有諷刺的意思。
就像這句話:“這可真是場座無虛席的比賽,而且我們居然還搶到了位置。”
表面上,這是句再正常不過的話,然而在配上圖片后,畫風頓時變得詭異了起來:
又例如這句話:“看起來就好吃極了。”
然而當看到散落在盒子邊緣的芝士和餡料時,顯然這又是一句充滿諷刺意味的語句。
現在,這些語義信息都已經被拿來喂給了AI,并訓練出了一個“懂得聽諷刺話”的模型。

目前這個模型,已經在推特這樣的社交媒體上進行了驗證,取得了84.33%的好效果。
看了這個AI模型,你還敢偷偷說老板壞話嗎?
論文地址:
https://arxiv.org/abs/2010.02960