面試官:詳細說說你對序列化的理解
本文主要內容
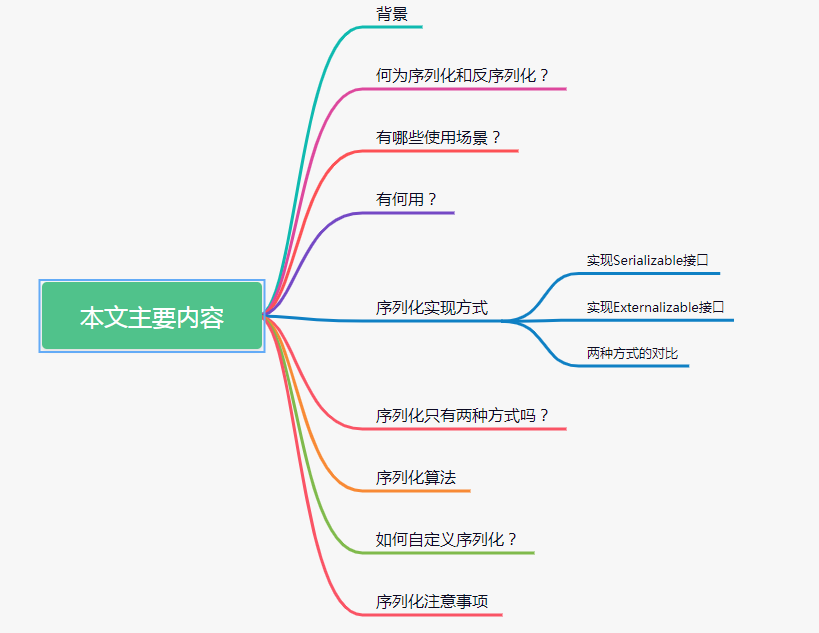
背景
在Java語言中,程序運行的時候,會產生很多對象,而對象信息也只是在程序運行的時候才在內存中保持其狀態,一旦程序停止,內存釋放,對象也就不存在了。
怎么能讓對象永久的保存下來呢?--------對象序列化 。
何為序列化和反序列化?
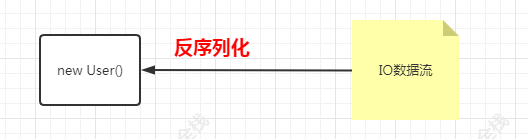
- 序列化:對象到IO數據流

- 反序列化:IO數據流到對象
有哪些使用場景?
Java平臺允許我們在內存中創建可復用的Java對象,但一般情況下,只有當JVM處于運行時,這些對象才可能存在,即,這些對象的生命周期不會比JVM的生命周期更長。但在現實應用中,就可能要求在JVM停止運行之后能夠保存(持久化)指定的對象,并在將來重新讀取被保存的對象。Java對象序列化就能夠幫助我們實現該功能。
使用Java對象序列化,在保存對象時,會把其狀態保存為一組字節,在未來,再將這些字節組裝成對象。必須注意地是,對象序列化保存的是對象的"狀態",即它的成員變量。由此可知,對象序列化不會關注類中的靜態變量。
除了在持久化對象時會用到對象序列化之外,當使用RMI(遠程方法調用),或在網絡中傳遞對象時,都會用到對象序列化。
Java序列化API為處理對象序列化提供了一個標準機制,該API簡單易用。
很多框架中都有用到,比如典型的dubbo框架中使用了序列化。
序列化有什么作用?
序列化機制允許將實現序列化的Java對象轉換位字節序列,這些字節序列可以保存在磁盤上,或通過網絡傳輸,以達到以后恢復成原來的對象。序列化機制使得對象可以脫離程序的運行而獨立存在。
序列化實現方式
Java語言中,常見實現序列化的方式有兩種:
- 實現Serializable接口
- 實現Externalizable接口
下面我們就來詳細的說說這兩種實現方式。
- 實現Serializable接口
創建一個User類實現Serializable接口 ,實現序列化,大致步驟為:
- 對象實體類實現Serializable 標記接口。
- 創建序列化輸出流對象ObjectOutputStream,該對象的創建依賴于其它輸出流對象,通常我們將對象序列化為文件存儲,所以這里用文件相關的輸出流對象 FileOutputStream。
- 通過ObjectOutputStream 的 writeObject()方法將對象序列化為文件。
- 關閉流。
以下就是code:
- package com.tian.my_code.test.clone;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.ObjectOutputStream;
- import java.io.Serializable;
- public class User implements Serializable {
- private int age;
- private String name;
- public User() {
- }
- public User(int age, String name) {
- this.age = age;
- this.name = name;
- }
- //set get省略
- public static void main(String[] args) {
- try {
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt"));
- User user=new User(22,"老田");
- objectOutputStream.writeObject(user);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
創建一個User對象,然后把User對象保存的user.txt中了。
反序列化
大致有以下三個步驟:
- 創建輸入流對象ObjectOutputStream。同樣依賴于其它輸入流對象,這里是文件輸入流 FileInputStream。
- 通過 ObjectInputStream 的 readObject()方法,將文件中的對象讀取到內存。
- 關閉流。
下面我們再進行反序列化code:
- package com.tian.my_code.test.clone;
- import java.io.*;
- public class SeriTest {
- public static void main(String[] args) {
- try {
- ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.txt"));
- User user=(User) ois.readObject();
- System.out.println(user.getName());
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
運行這段代碼,輸出結果:

使用IDEA打開user.tst文件:

使用編輯器16機制查看

關于文件內容咱們就不用太關心了,繼續說我們的重點。
序列化是把User對象存放到文件里了,然后反序列化就是讀取文件內容并創建對象。
A端把對象User保存到文件user.txt中,B端就可以通過網絡或者其他方式讀取到這個文件,再進行反序列化,獲得A端創建的User對象。
拓展
如果B端拿到的User屬性如果有變化呢?比如說:增加一個字段
- private String address;
再次進行反序列化就會報錯

添加serialVersionUID
- package com.tian.my_code.test.clone;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.ObjectOutputStream;
- import java.io.Serializable;
- public class User implements Serializable{
- private static final long serialVersionUID = 2012965743695714769L;
- private int age;
- private String name;
- public User() {
- }
- public User(int age, String name) {
- this.age = age;
- this.name = name;
- }
- // set get 省略
- public static void main(String[] args) {
- try {
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt"));
- User user=new User(22,"老田");
- objectOutputStream.writeObject(user);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
再次執行反序列化,運行結果正常

然后我們再次加上字段和對應的get/set方法
- private String address;
再次執行反序列化

反序列化成功。
如果可序列化類未顯式聲明 serialVersionUID,則序列化運行時將基于該類的各個方面計算該類的默認 serialVersionUID 值,如“Java(TM) 對象序列化規范”中所述。
不過,強烈建議 所有可序列化類都顯式聲明 serialVersionUID 值,原因是計算默認的 serialVersionUID對類的詳細信息具有較高的敏感性,根據編譯器實現的不同可能千差萬別,這樣在反序列化過程中可能會導致意外的 InvalidClassException。
因此,為保證 serialVersionUID值跨不同 Java 編譯器實現的一致性,序列化類必須聲明一個明確的 serialVersionUID值。
強烈建議使用 private 修飾符顯示聲明 serialVersionUID(如果可能),原因是這種聲明僅應用于直接聲明類 -- serialVersionUID字段作為繼承成員沒有用處。數組類不能聲明一個明確的 serialVersionUID,因此它們總是具有默認的計算值,但是數組類沒有匹配 serialVersionUID值的要求。
所以,盡量顯示的聲明,這樣序列化的類即使有字段的修改,因為 serialVersionUID的存在,也能保證反序列化成功。保證了更好的兼容性。
IDEA中如何快捷添加serialVersionUID?
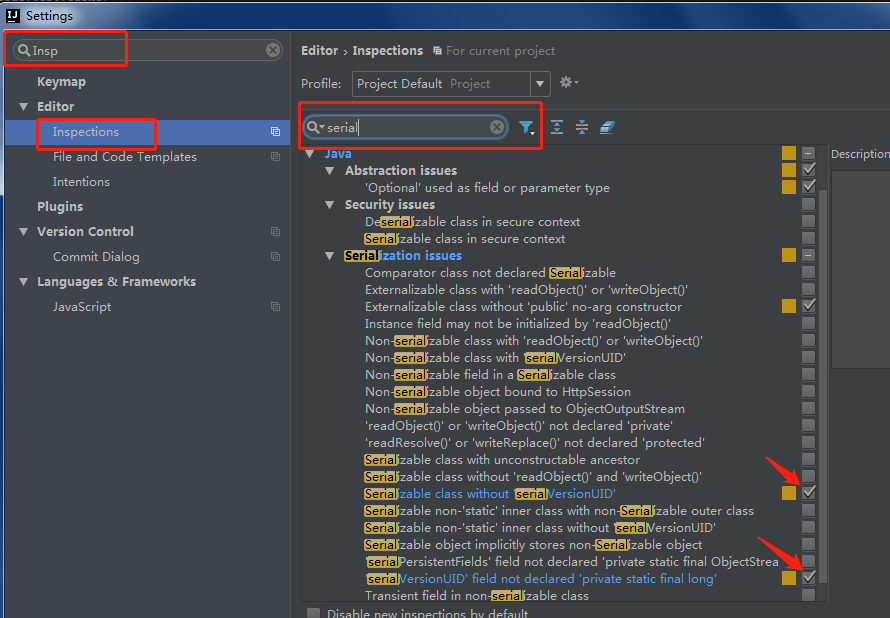
我們的類實現Serializable接口,鼠標放在類上,Alt+Enter鍵就可以添加了。
實現Externalizable接口
通過實現Externalizable接口,必須實現writeExternal、readExternal方法。

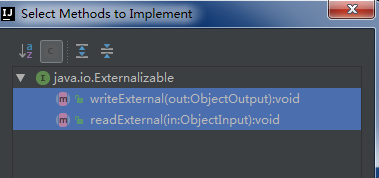
- @Override
- public void writeExternal(ObjectOutput out) throws IOException {
- }
- @Override
- public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
- }
Externalizable是Serializable的子接口。
public interface Externalizable extends java.io.Serializable {
繼續使用前面的User,代碼進行改造:
- package com.tian.my_code.test.clone;
- import java.io.*;
- public class User implements Externalizable {
- private int age;
- private String name;
- public User() {
- }
- public User(int age, String name) {
- this.age = age;
- this.name = name;
- }
- //set get
- public static void main(String[] args) {
- try {
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt"));
- User user = new User(22, "老田");
- objectOutputStream.writeObject(user);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- @Override
- public void writeExternal(ObjectOutput out) throws IOException {
- //將name反轉后寫入二進制流
- StringBuffer reverse = new StringBuffer(name).reverse();
- out.writeObject(reverse);
- out.writeInt(age);
- }
- @Override
- public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
- //將讀取的字符串反轉后賦值給name實例變量
- this.name = ((StringBuffer) in.readObject()).reverse().toString();
- //將讀取到的int類型值付給age
- this.age = in.readInt();
- }
- }
執行序列化,然后再次執行反序列化,輸出:

注意
Externalizable接口不同于Serializable接口,實現此接口必須實現接口中的兩個方法實現自定義序列化,這是強制性的;特別之處是必須提供public的無參構造器,因為在反序列化的時候需要反射創建對象。
兩種方式對比
下圖為兩種實現方式的對比:

序列化只有兩種方式嗎?
當然不是。根據序列化的定義,不管通過什么方式,只要你能把內存中的對象轉換成能存儲或傳輸的方式,又能反過來恢復它,其實都可以稱為序列化。因此,我們常用的Fastjson、Jackson等第三方類庫將對象轉成Json格式文件,也可以算是一種序列化,用JAXB實現XML格式文件輸出,也可以算是序列化。所以,千萬不要被思維局限,其實現實當中我們進行了很多序列化和反序列化的操作,涉及不同的形態、數據格式等。
序列化算法
- 所有保存到磁盤的對象都有一個序列化編碼號。
- 當程序試圖序列化一個對象時,會先檢查此對象是否已經序列化過,只有此對象從未(在此虛擬機)被序列化過,才會將此對象序列化為字節序列輸出。
- 如果此對象已經序列化過,則直接輸出編號即可。
自定義序列化
有些時候,我們有這樣的需求,某些屬性不需要序列化。使用transient關鍵字選擇不需要序列化的字段。
繼續使用前面的代碼進行改造,在age字段上添加transient修飾:
- package com.tian.my_code.test.clone;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.ObjectOutputStream;
- import java.io.Serializable;
- public class User implements Serializable{
- private transient int age;
- private String name;
- public User() {
- }
- public User(int age, String name) {
- this.age = age;
- this.name = name;
- }
- public int getAge() {
- return age;
- }
- public void setAge(int age) {
- this.age = age;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public static void main(String[] args) {
- try {
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt"));
- User user=new User(22,"老田");
- objectOutputStream.writeObject(user);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- ```
- 序列化,然后進行反序列化:
- ```java
- package com.tian.my_code.test.clone;
- import java.io.*;
- public class SeriTest {
- public static void main(String[] args) {
- try {
- ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.txt"));
- User user=(User) ois.readObject();
- System.out.println(user.getName());
- System.out.println(user.getAge());
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
運行輸出:

從輸出我們看到,使用transient修飾的屬性,Java序列化時,會忽略掉此字段,所以反序列化出的對象,被transient修飾的屬性是默認值。
對于引用類型,值是null;基本類型,值是0;boolean類型,值是false。
探索
到此序列化內容算講完了,但是,如果只停留在這個層面,是無法應對實際工作中的問題的。
比如模型對象持有其它對象的引用怎么處理,引用類型如果是復雜些的集合類型怎么處理?
上面的User中持有String引用類型的,照樣序列化沒問題,那么如果是我們自定義的引用類呢?
比如下面的場景:
- package com.tian.my_code.test.clone;
- public class UserAddress {
- private int provinceCode;
- private int cityCode;
- public UserAddress() {
- }
- public UserAddress(int provinceCode, int cityCode) {
- this.provinceCode = provinceCode;
- this.cityCode = cityCode;
- }
- public int getProvinceCode() {
- return provinceCode;
- }
- public void setProvinceCode(int provinceCode) {
- this.provinceCode = provinceCode;
- }
- public int getCityCode() {
- return cityCode;
- }
- public void setCityCode(int cityCode) {
- this.cityCode = cityCode;
- }
- }
然后在User中添加一個UserAddress的屬性:
- package com.tian.my_code.test.clone;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.ObjectOutputStream;
- import java.io.Serializable;
- public class User implements Serializable{
- private static final long serialVersionUID = -2445226500651941044L;
- private int age;
- private String name;
- private UserAddress userAddress;
- public User() {
- }
- public User(int age, String name) {
- this.age = age;
- this.name = name;
- }
- //get set
- public static void main(String[] args) {
- try {
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt"));
- User user=new User(22,"老田");
- UserAddress userAddress=new UserAddress(10001,10001001);
- user.setUserAddress(userAddress);
- objectOutputStream.writeObject(user);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
運行上面代碼:
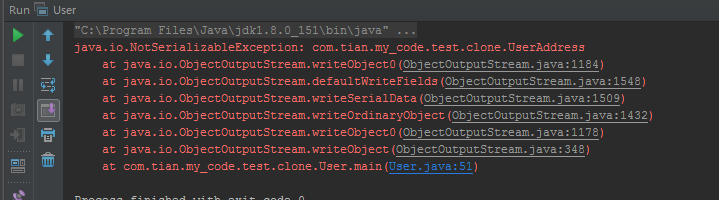
拋出了 java.io.NotSerializableException 異常。很明顯在告訴我們,UserAddress沒有實現序列化接口。待UserAddress類實現序列化接口后:
- package com.tian.my_code.test.clone;
- import java.io.Serializable;
- public class UserAddress implements Serializable {
- private static final long serialVersionUID = 5128703296815173156L;
- private int provinceCode;
- private int cityCode;
- public UserAddress() {
- }
- public UserAddress(int provinceCode, int cityCode) {
- this.provinceCode = provinceCode;
- this.cityCode = cityCode;
- }
- //get set
- }
再次運行,正常不報錯了。
反序列化代碼:
- package com.tian.my_code.test.clone;
- import java.io.*;
- public class SeriTest {
- public static void main(String[] args) {
- try {
- ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.txt"));
- User user=(User) ois.readObject();
- System.out.println(user.getName());
- System.out.println(user.getAge());
- System.out.println(user.getUserAddress().getProvinceCode());
- System.out.println(user.getUserAddress().getCityCode());
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
運行結果:
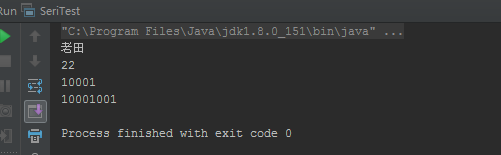
典型運用場景
- public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
- private static final long serialVersionUID = -6849794470754667710L;
- }
- public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
- private static final long serialVersionUID = 362498820763181265L;
- }
- public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
- private static final long serialVersionUID = 8683452581122892189L;
- }
- .....
很多常用類都實現了序列化接口。
再次拓展
上面說的transient 反序列化的時候是默認值,但是你會發現,幾種常用集合類ArrayList、HashMap、LinkedList等數據存儲字段,竟然都被 transient 修飾了,然而在實際操作中我們用集合類型存儲的數據卻可以被正常的序列化和反序列化?
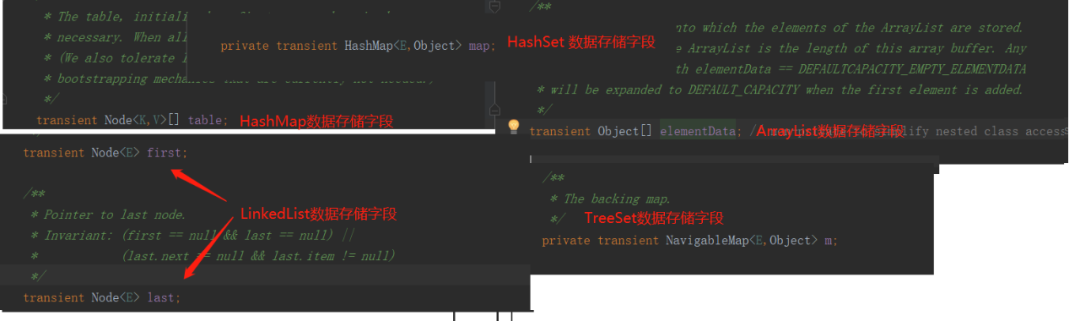
真相當然還是在源碼里。實際上,各個集合類型對于序列化和反序列化是有單獨的實現的,并沒有采用虛擬機默認的方式。這里以 ArrayList中的序列化和反序列化源碼部分為例分析:
- private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{
- int expectedModCount = modCount;
- //序列化當前ArrayList中非transient以及非靜態字段
- s.defaultWriteObject();
- //序列化數組實際個數
- s.writeInt(size);
- // 逐個取出數組中的值進行序列化
- for (int i=0; i<size; i++) {
- s.writeObject(elementData[i]);
- }
- //防止在并發的情況下對元素的修改
- if (modCount != expectedModCount) {
- throw new ConcurrentModificationException();
- }
- }
- private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
- elementData = EMPTY_ELEMENTDATA;
- // 反序列化非transient以及非靜態修飾的字段,其中包含序列化時的數組大小 size
- s.defaultReadObject();
- // 忽略的操作
- s.readInt(); // ignored
- if (size > 0) {
- // 容量計算
- int capacity = calculateCapacity(elementData, size);
- SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
- //檢測是否需要對數組擴容操作
- ensureCapacityInternal(size);
- Object[] a = elementData;
- // 按順序反序列化數組中的值
- for (int i=0; i<size; i++) {
- a[i] = s.readObject();
- }
- }
- }
讀源碼可以知道,ArrayList的序列化和反序列化主要思路就是根據集合中實際存儲的元素個數來進行操作,這樣做估計是為了避免不必要的空間浪費(因為ArrayList的擴容機制決定了,集合中實際存儲的元素個數肯定比集合的可容量要小)。為了驗證,我們可以在單元測試序列化和返序列化的時候,在ArrayLIst的兩個方法中打上斷點,以確認這兩個方法在序列化和返序列化的執行流程中(截圖為反序列化過程):
原來,我們之前自以為集合能成功序列化也只是簡單的實現了標記接口都只是表象,表象背后有各個集合類有不同的深意。所以,同樣的思路,讀者朋友可以自己去分析下 HashMap以及其它集合類中自行控制序列化和反序列化的個中門道了,感興趣的小伙伴可以自行去查看一番。
序列化注意事項
1、序列化時,只對對象的狀態進行保存,而不管對象的方法;
2、當一個父類實現序列化,子類自動實現序列化,不需要顯式實現Serializable接口;
3、當一個對象的實例變量引用其他對象,序列化該對象時也把引用對象進行序列化;
4、并非所有的對象都可以序列化,至于為什么不可以,有很多原因了,比如:
安全方面的原因,比如一個對象擁有private,public等field,對于一個要傳輸的對象,比如寫到文件,或者進行RMI傳輸等等,在序列化進行傳輸的過程中,這個對象的private等域是不受保護的;
資源分配方面的原因,比如socket,thread類,如果可以序列化,進行傳輸或者保存,也無法對他們進行重新的資源分配,而且,也是沒有必要這樣實現;
5、聲明為static和transient類型的成員數據不能被序列化。因為static代表類的狀態,transient代表對象的臨時數據。
6、序列化運行時使用一個稱為 serialVersionUID 的版本號與每個可序列化類相關聯,該序列號在反序列化過程中用于驗證序列化對象的發送者和接收者是否為該對象加載了與序列化兼容的類。為它賦予明確的值。顯式地定義serialVersionUID有兩種用途:
- 在某些場合,希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有相同的serialVersionUID;
- 在某些場合,不希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有不同的serialVersionUID。
7、Java有很多基礎類已經實現了serializable接口,比如String,Vector等。但是也有一些沒有實現serializable接口的;
8、如果一個對象的成員變量是一個對象,那么這個對象的數據成員也會被保存!這是能用序列化解決深拷貝的重要原因;
總結
什么是序列化?序列化Java中常用實現方式有哪些?兩種實現序列化方式的對比,序列化算法?如何自定義序列化?Java集合框架中序列化是如何實現的?
這幾個點如果沒有get到,麻煩請再次閱讀,或者加我微信進群里大家一起聊。
參考:
- cnblogs.com/9dragon/p/10901448.html oschina.net/translate/serialization-in-java
本文轉載自微信公眾號「 Java后端技術全棧」,可以通過以下二維碼關注。轉載本文請聯系 Java后端技術全棧公眾號。