5分鐘快速掌握scrapy爬蟲框架
1. scrapy簡介
scrapy是基于事件驅動的Twisted框架下用純python寫的爬蟲框架。很早之前就開始用scrapy來爬取網絡上的圖片和文本信息,一直沒有把細節記錄下來。這段時間,因為工作需要又重拾scrapy爬蟲,本文和大家分享下,包你一用就會, 歡迎交流。
1.1 scrapy框架
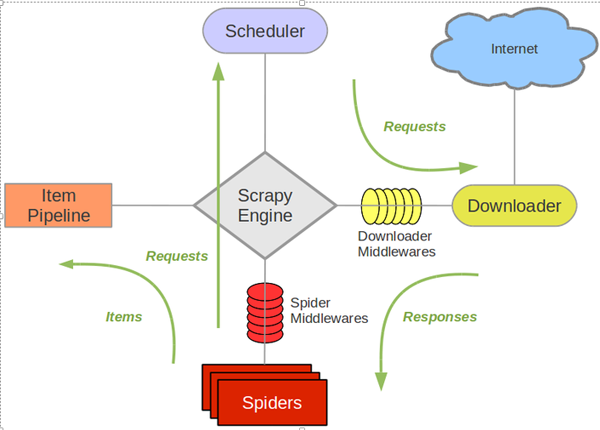
scrapy框架包括5個主要的組件和2個中間件Hook。
- ENGIINE:整個框架的控制中心, 控制整個爬蟲的流程。根據不同的條件添加不同的事件(就是用的Twisted)
- SCHEDULER:事件調度器
- DOWNLOADER:接收爬蟲請求,從網上下載數據
- SPIDERS:發起爬蟲請求,并解析DOWNLOADER返回的網頁內容,同時和數據持久化進行交互,需要開發者編寫
- ITEM PIPELINES:接收SPIDERS解析的結構化的字段,進行持久化等操作,需要開發者編寫
- MIDDLEWARES:ENGIINE和SPIDERS, ENGIINE和DOWNLOADER之間一些額外的操作,hook的方式提供給開發者
從上可知,我們只要實現SPIDERS(要爬什么網站,怎么解析)和ITEM PIPELINES(如何處理解析后的內容)就可以了。其他的都是有框架幫你完成了。(圖片來自網絡,如果侵權聯系必刪)
1.2 scrapy數據流
我們再詳細看下組件之間的數據流,會更清楚框架的內部運作。(圖片來自網絡,如果侵權聯系必刪)

- SPIDERS發爬蟲請求給ENGIINE, 告訴它任務來了
- ENGIINE將請求添加到SCHEDULER調度隊列里, 說任務就交給你了,給我安排好
- SCHEDULER看看手里的爬取請求很多,挑一個給ENGIINE, 說大哥幫忙轉發給下載DOWNLOADER
- ENGIINE:好的, DOWNLOADER你的任務來了
- DOWNLOADER:開始下載了,下載好了,任務結果 交給ENGIINE
- ENGIINE將結果給SPIDERS, 你的一個請求下載好了,快去解析吧
- SPIDERS:好的,解析產生了結果字段。又給SPIDERS轉發給ITEM PIPELINES
- ITEM PIPELINES: 接收到字段內容,保存起來。
第1步到第8步,一個請求終于完成了。是不是覺得很多余?ENGIINE夾在中間當傳話筒,能不能直接跳過?可以考慮跳過了會怎么樣。
這里分析一下
- SCHEDULER的作用:任務調度, 控制任務的并發,防止機器處理不過來
- ENGIINE:就是基于Twisted框架, 當事件來(比如轉發請求)的時候,通過回調的方式來執行對應的事件。我覺得ENGIINE讓所有操作變的統一,都是按照事件的方式來組織其他組件, 其他組件以低耦合的方式運作;對于一種框架來說,無疑是必備的。
2. 基礎:XPath
寫爬蟲最重要的是解析網頁的內容,這個部分就介紹下通過XPath來解析網頁,提取內容。
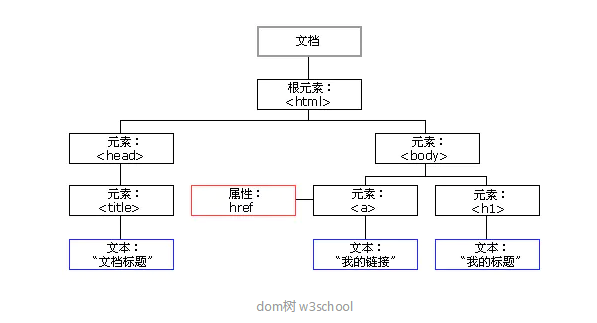
2.1 HTML節點和屬性
(圖片來自網絡,如果侵權聯系必刪)
2.2 解析語法
- a / b:‘/’在 xpath里表示層級關系,左邊的 a是父節點,右邊的 b是子節點
- a // b:表示a下所有b,直接或者間接的
- [@]:選擇具有某個屬性的節點
- //div[@classs], //a[@x]:選擇具有 class屬性的 div節點、選擇具有 x屬性的 a節點
- //div[@class="container"]:選擇具有 class屬性的值為 container的 div節點
- //a[contains(@id, "abc")]:選擇 id屬性里有 abc的 a標簽
一個例子
- response.xpath('//div[@class="taglist"]/ul//li//a//img/@data-original').get_all()
- # 獲取所有class屬性(css)為taglist的div, 下一個層ul下的所有li下所有a下所有img標簽下data-original屬性
- # data-original這里放的是圖片的url地址
更多詳見
http://zvon.org/comp/r/tut-XPath_1.html#Pages~List_of_XPaths
3. 安裝部署
Scrapy 是用純python編寫的,它依賴于幾個關鍵的python包(以及其他包):
- lxml 一個高效的XML和HTML解析器
- parsel ,一個寫在lxml上面的html/xml數據提取庫,
- w3lib ,用于處理URL和網頁編碼的多用途幫助程序
- twisted 異步網絡框架
- cryptography 和 pyOpenSSL ,處理各種網絡級安全需求
- # 安裝
- pip install scrapy
4. 創建爬蟲項目
- scrapy startproject sexy
- # 創建一個后的項目目錄
- # sexy
- # │ scrapy.cfg
- # │
- # └─sexy
- # │ items.py
- # │ middlewares.py
- # │ pipelines.py
- # │ settings.py
- # │ __init__.py
- # │
- # ├─spiders
- # │ │ __init__.py
- # │ │
- # │ └─__pycache__
- # └─__pycache__
- # 執行 需要到scrapy.cfg同級別的目錄執行
- scrapy crawl sexy
從上可知,我們要寫的是spiders里的具體的spider類和items.py和pipelines.py(對應的ITEM PIPELINES)
5. 開始scrapy爬蟲
5.1 簡單而強大的spider
這里實現的功能是從圖片網站中下載圖片,保存在本地, url做了脫敏。需要注意的點在注釋要標明
- 類要繼承 scrapy.Spider
- 取一個唯一的name
- 爬取的網站url加到start_urls列表里
- 重寫parse利用xpath解析reponse的內容
可以看到parse實現的時候沒有轉發給ITEM PIPELINES,直接處理了。這樣簡單的可以這么處理,如果業務很復雜,建議交給ITEM PIPELINES。后面會給例子
- # 目錄結果為:spiders/sexy_spider.py
- import scrapy
- import os
- import requests
- import time
- def download_from_url(url):
- response = requests.get(url, stream=True)
- if response.status_code == requests.codes.ok:
- return response.content
- else:
- print('%s-%s' % (url, response.status_code))
- return None
- class SexySpider(scrapy.Spider):
- # 如果有多個spider, name要唯一
- name = 'sexy'
- allowed_domains = ['uumdfdfnt.94demo.com']
- allowed_urls = ['http://uumdfdfnt.94demo.com/']
- # 需要爬取的網站url加到start_urls list里
- start_urls = ['http://uumdfdfnt.94demo.com/tag/dingziku/index.html']
- save_path = '/home/sexy/dingziku'
- def parse(self, response):
- # 解析網站,獲取圖片列表
- img_list = response.xpath('//div[@class="taglist"]/ul//li//a//img/@data-original').getall()
- time.sleep(1)
- # 處理圖片, 具體業務操作, 可交給items, 見5.2 items例子
- for img_url in img_list:
- file_name = img_url.split('/')[-1]
- content = download_from_url(img_url)
- if content is not None:
- with open(os.path.join(self.save_path, file_name), 'wb') as fw:
- fw.write(content)
- # 自動下一頁(見5.3 自動下一頁)
- next_page = response.xpath('//div[@class="page both"]/ul/a[text()="下一頁"]/@href').get()
- if next_page is not None:
- next_page = response.urljoin(next_page)
- yield scrapy.Request(next_page, callback=self.parse)
5.2 items和pipline例子
這里說明下兩個的作用
- items:提供一個字段存儲, spider會將數據存在這里
- pipline:會從items取數據,進行業務操作,比如5.1中的保存圖片;又比如存儲到數據庫中等
我們來改寫下上面的例子
- items.py其實就是定義字段scrapy.Field()
- import scrapy
- class SexyItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- img_url = scrapy.Field()
- spiders/sexy_spider.py
- import scrapy
- import os
- # 導入item
- from ..items import SexyItem
- class SexySpider(scrapy.Spider):
- # 如果有多個spider, name要唯一
- name = 'sexy'
- allowed_domains = ['uumdfdfnt.94demo.com']
- allowed_urls = ['http://uumdfdfnt.94demo.com/']
- # 需要爬取的網站url加到start_urls list里
- start_urls = ['http://uumdfdfnt.94demo.com/tag/dingziku/index.html']
- save_path = '/home/sexy/dingziku'
- def parse(self, response):
- # 解析網站,獲取圖片列表
- img_list = response.xpath('//div[@class="taglist"]/ul//li//a//img/@data-original').getall()
- time.sleep(1)
- # 處理圖片, 具體業務操作, 可交給yield items
- for img_url in img_list:
- items = SexyItem()
- items['img_url'] = img_url
- yield items
- pipelines.py
- import os
- import requests
- def download_from_url(url):
- response = requests.get(url, stream=True)
- if response.status_code == requests.codes.ok:
- return response.content
- else:
- print('%s-%s' % (url, response.status_code))
- return None
- class SexyPipeline(object):
- def __init__(self):
- self.save_path = '/tmp'
- def process_item(self, item, spider):
- if spider.name == 'sexy':
- # 取出item里內容
- img_url = item['img_url']
- # 業務處理
- file_name = img_url.split('/')[-1]
- content = download_from_url(img_url)
- if content is not None:
- with open(os.path.join(self.save_path, file_name), 'wb') as fw:
- fw.write(content)
- return item
- 重要的配置要開啟在settings.py中開啟piplines類,數值表示優先級
- ITEM_PIPELINES = {
- 'sexy.pipelines.SexyPipeline': 300,
- }
5.3 自動下一頁
有時候我們不僅要爬取請求頁面中的內容,還要遞歸式的爬取里面的超鏈接url,特別是下一頁這種,解析內容和當前頁面相同的情況下。一種笨方法是手動加到start_urls里。大家都是聰明人來試試這個。
- 先在頁面解析下下一頁的url
- scrapy.Request(next_page, callback=self.parse) 發起一個請求,并調用parse來解析,當然你可以用其他的解析
完美了,完整例子見5.1
- next_page = response.xpath('//div[@class="page both"]/ul/a[text()="下一頁"]/@href').get()
- if next_page is not None:
- next_page = response.urljoin(next_page)
- yield scrapy.Request(next_page, callback=self.parse)
5.4 中間件
- 下載中間件 中間件的作用是提供一些常用的鉤子Hook來增加額外的操作。中間件的操作是在middlewares.py。可以看到主要是處理請求process_request,響應process_response和異常process_exception三個鉤子函數。
- 處理請求process_request: 傳給DOWNLOADER之前做的操作
- 響應process_response:DOWNLOADER給ENGIINE響應之前的操作
這里舉一個添加模擬瀏覽器請求的方式,防止爬蟲被封鎖。重寫process_request
- from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
- import random
- agents = ['Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;',
- 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
- 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
- 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
- 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)']
- class RandomUserAgent(UserAgentMiddleware):
- def process_request(self, request, spider):
- ua = random.choice(agents)
- request.headers.setdefault('User-agent',ua,)
統一要在settings.py中開啟下載中間件,數值表示優先級
- DOWNLOADER_MIDDLEWARES = {
- 'sexy.middlewares.customUserAgent.RandomUserAgent': 20,
- }
5.5 可用配置settings.py
除了上面提供的pipline配置開啟和中間件配置外,下面介紹幾個常用的配置
- 爬蟲機器人規則:ROBOTSTXT_OBEY = False, 如果要爬取的網站有設置robots.txt,最好設置為False
- CONCURRENT_REQUESTS:并發請求
- DOWNLOAD_DELAY:下載延遲,可以適當配置,避免把網站也爬掛了。
所有的配置詳見 https://doc.scrapy.org/en/latest/topics/settings.html
6. 總結
相信從上面的介紹,你已經可以動手寫一個你自己的爬蟲了。我也完成了做筆記的任務了。scrapy還提供更加詳細的細節,可參見https://docs.scrapy.org/en/latest/。
最后總結如下:
- scrapy是基于事件驅動Twisted框架的爬蟲框架。ENGIINE是核心,負責串起其他組件
- 開發只要編寫spider和item pipline和中間件, download和schedule交給框架
- scrapy crawl 你的爬蟲name,name要唯一
- 爬取的url放在start_urls, spider會自動Request的,parse來解析
- pipline和中間件要記得在settings中開啟
- 關注下settings的常用配置,需要時看下文檔