桃李春風一杯酒,江湖夜雨十年燈 - 老兵夜話DPDK
20年彈指一揮間。技術在飛速的發展,從最初接觸ixp1200 的耳目一新,到如今DPDK, smart NIC的 如火如荼。我也已經從昔日的青蔥少年,變成了兩鬢微霜的打工人。午夜夢回, 在感慨人生有如逆旅之余,心中也有很多想法不吐不快。
前傳
2000年是網絡處理器的黃金時代,Intel在那個時候也有一個Network Processor產品,名為IXP1200,主要是通過可編程的專用引擎來加速網絡報文處理。IXP1200/2400/2800本身帶有N個微引擎,可供編程。但是編程的難度很大,尤其是在高并發的情況下并不容易調試。
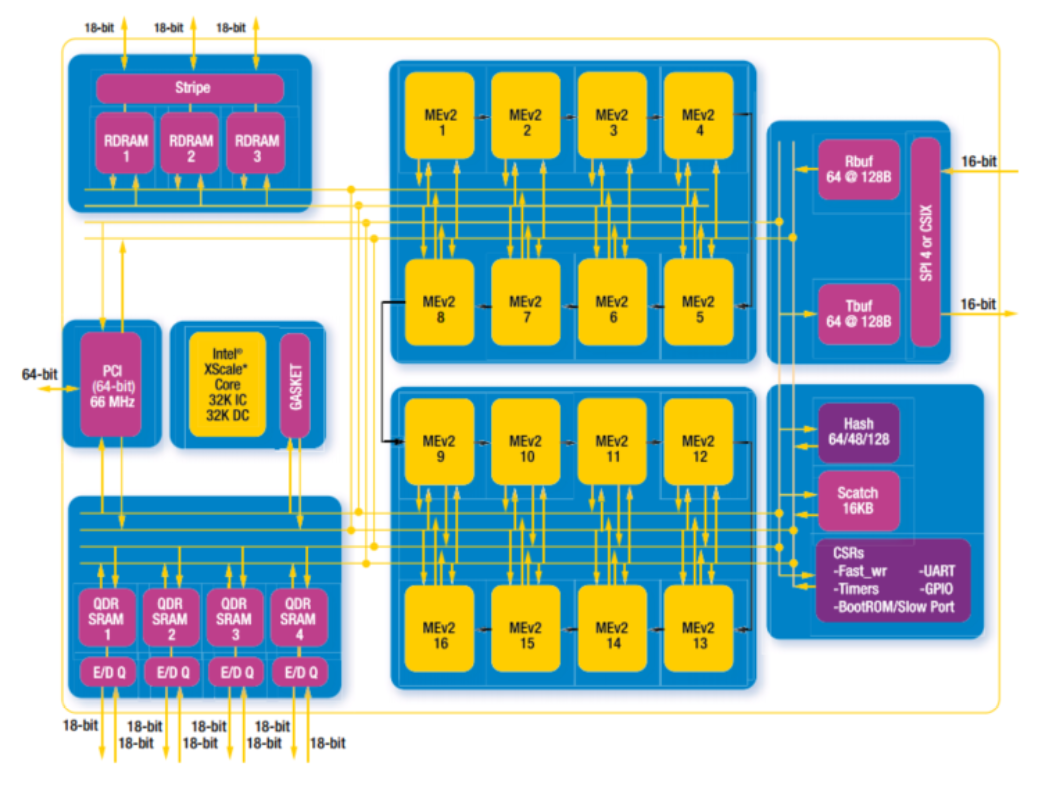
我們來看看IXP1200 和2800的架構圖:
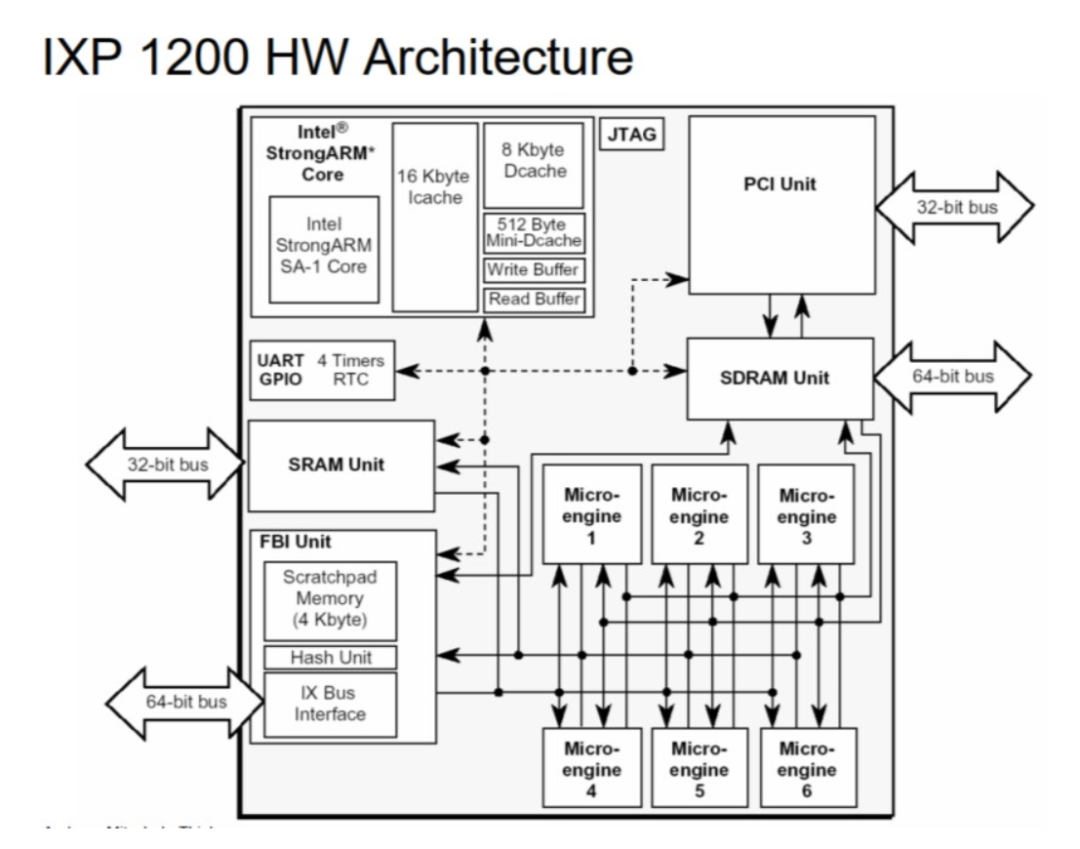
IXP 1200 是初代試水產品, 只有6個微引擎。其整體頻率也較低,約為233Mhz,所以只支持千兆網絡線速。
IXP 2800 就進化到了16個微引擎. 微引擎頻率提高到1.2Ghz. 可以支持萬兆網絡線速。同時支持各類加密算法加速引擎。
這個產品線于2007年被出售給了Netronome公司,現在依然存在,而且已經擴充至60個甚至更多的微引擎。
https://www.netronome.com/products/agilio-fx/
每個微引擎又內置了4-8個硬件線程,每個線程可以發起收包操作然后進入等待模式調度器調度其它硬件線程運行,直到I/O 操作完成 對應的signal重新設置為可以調度(注意這一切都是硬件邏輯)下面是微引擎的內部架構
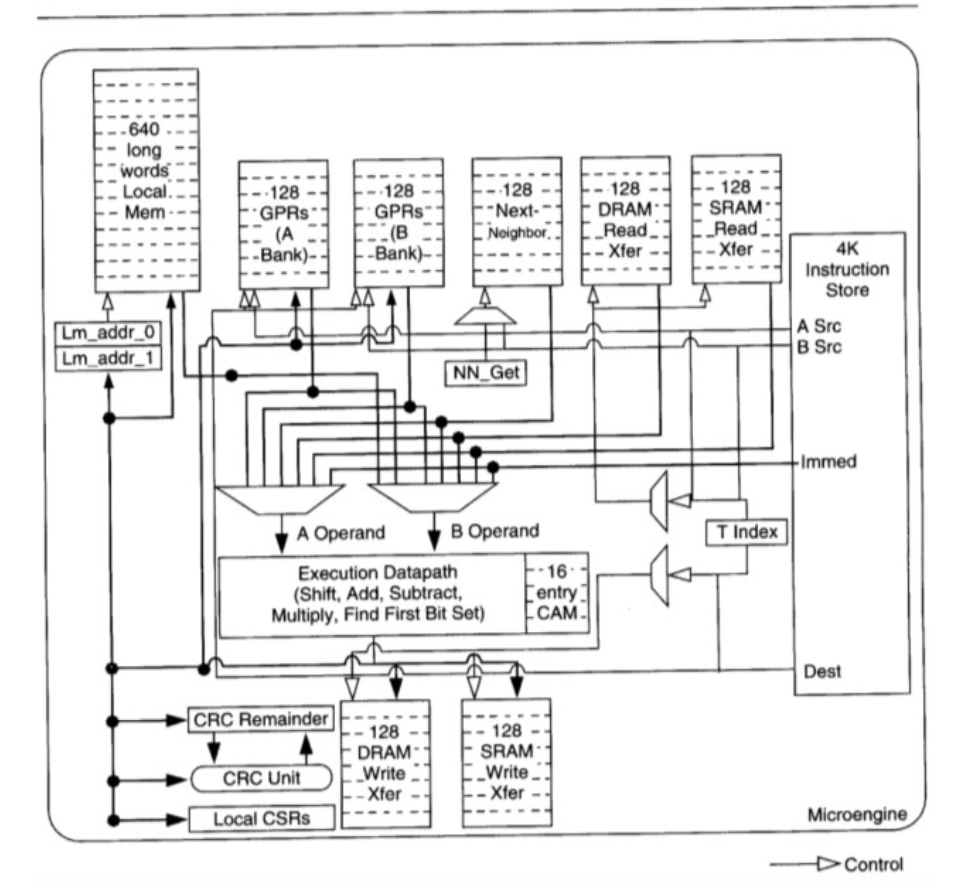
大家可以看到這個微引擎麻雀雖小五臟俱全,甚至帶有CAM (Content-addressable memory) 。
寄存器分為幾類:計算用的 通用GPR 以及IO用的xfer寄存器。有4k的空間存放代碼。有一定大小的本地緩存Local Mem。也有類似于中斷但又不完全一樣的signal機制。在這個螺螄殼里也可以寫出很多非常精巧的代碼,包括復雜的有限狀態機。下面是一段代碼示例。

估計大多數人都不太能看明白這段代碼。這其實就是微引擎編程的一個瓶頸-可讀性差與學習曲線陡峭。微引擎中的資源(各類寄存器,signal) 都是非常有限的,基本上都需要進行手動的優化,開發人員編碼時如履薄冰。寄存器耗盡是我那時的噩夢。絞盡腦汁也要騰挪出一些資源。學習的曲線之高直接導致的就是開發生態非常之小。同時開發工具,調試工具都必須是專有的。直接導致開發效率不高。這些其實也是專用的ASIC和網絡處理器普遍存在的問題。
挑戰到來
X86 CPU 在控制面處于統治地位,數據面則長期受制于FSB,PCI/PCIE 帶寬限制。2010年以后,隨著新一代X86 CPU性能的不斷增強(FSB被替代,DMI帶寬不斷增大)以及PCIE 2.0 推出。那么人們不禁要問。使用X86是否有可能達萬兆線速處理?這在當時是一個巨大的疑問。普遍認為是很難做到的。
首先來看看FSB的移除
FSB 全稱是 Front-side bus。如下圖所示, 主要是負責連接CPU 與北橋內存控制器的總線技術。
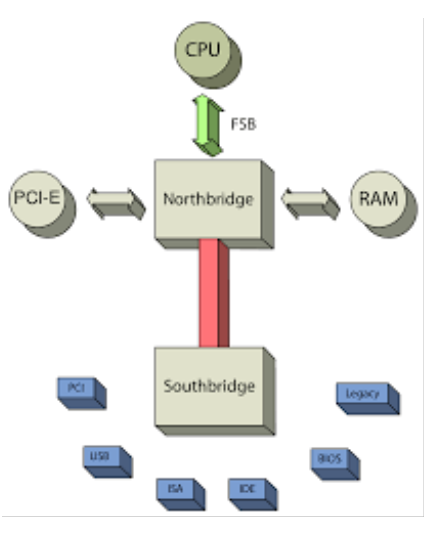
FSB 橫亙在北橋(一般是內存控制器Hub)與CPU之間。FSB不但掌管了對內存的訪問同時也是PCIE通信的必經之路。性能不具備水平擴展性。作為控制平面是沒問題的。但是如果作為數據平面 就成了首要瓶頸。
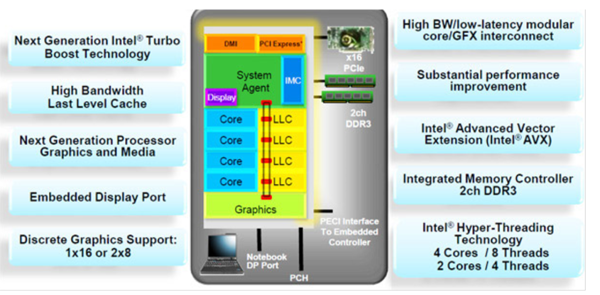
再來看看之后的Sandy bridge 微架構的樣子。FSB被移除, 內存控制器直接整合到CPU之中, PCIE也升級到了2.0(這就意味著每個lane的帶寬升級到了 4Gbps)
揭開大幕
使用X86作為數據平面方案有很多福利:
- X86 芯片通常有18個月換代的,可以使得性能搭車18個月就獲得更新。一個最好的例子就是aes-ni,每一代aes-ni指令性能都有所增強。同理適用于sse/avx/avx2/avx512。(aes-ni 屬于X86的aes加密算法指令擴展)
- 虛擬化技術也是可以毫無障礙的搭順風車來利用,從而節省單獨研發的費用問題。
- 同時因為是X86,整個技術生態是完備的。開發環境/調試環境都無需再使用專有的。大大增強了普適性同時也大大提高了效率以及升級換代的時間。例如 可以使用最先進最好的編譯器技術。C語言的普及程度也是非常之高,學習曲線平緩。
隨著Sandy bridge 這代的X86 處理器發布, 之前的各種技術瓶頸貌似都有了松動的跡象。Venky Venkatesan(已故的DPDK之父) 腦海中的新一代的技術方案也逐漸成型。在經過一段內部的醞釀之后,2010-2012年 Intel完成架構分析與設計。2013 年dpdk社區正式上線,從而在業內成為了一個現象級的產品。
那么我們可以復盤一下 當時 Venky 先生所面臨的挑戰(X86 萬兆線速)
- 萬兆線速基本上約等于15 MPPS(也就是1500萬個報文每秒)。那么CPU大約有67.2 ns的預算來轉發一個報文
- Sandybridge 主頻達到2.2Ghz是毫無困難的。困難應該主要還是來自IO。FSB這個瓶頸已經被替代。PCIE2.0 已經開始支持。2M/1G的巨頁也開始支持!
- 但是如果回頭看軟件, 問題就很多了。如果通過傳統的內核協議棧, 這一目標完全是無法實現的。當然內核協議棧的設計哲學也并非是單純為了性能。通用性也是其重要考量。但是在這個特定的場景下就成為了最后一個瓶頸。
應對挑戰
DPDK是一個典型的由量變到質變的設計過程。它本質上是眾多優化方法的集合。單一的優化方法,其實以前也已經存在。比如 by pass kernel 的 net map。但是單一的優化方法都不足以把性能提升到一個質變的程度。DPDK則是集所有可以使用到的優化方法之大成,把X86處理器的網絡處理能力推上了一個新的境界。
我們可以列出DPDK的優化方法有(包含但不限于):
- By pass 內核協議棧。通過uio/vfio將網絡設備暴露給用戶層, 拋開通用的內核路徑, 一身輕。(uio/vfio 是Linux內核支持用戶層驅動的編程框架)
- 使用巨頁從而大大降低TLB miss帶來的性能損失。細節請參考(https://lwn.net/Articles/374424/)
- 廣泛的應用批處理從而攤薄單個報文的開銷 (例如 使用simd優化網卡驅動). 批處理的優化思想在DPDK之中是一個極其常見的范式。
- 放棄中斷模式而轉而直接使用輪詢模式。這個對于降低時延非常重要。因為在PCIE總線上,中斷也是一個TLP報文過多的中斷也會影響真正數據的時延(尤其是小包),中斷處理導致的上下文切換也會引起系統抖動。但是輪詢非常考驗內存控制器和PCIE Root Complex的魯棒性。魯棒性差的平臺容易出問題。
- 魔改DDIO,網卡直接DMA數據到LLC(Last-Level Cache)中. DDIO對于小包的性能非常重要. 這個在今天依然是xeon的獨有功能(新一代的CLX協議中實現了DDIO的超集),細節請參考“Linux閱碼場”公眾號前期文章《Linux 系統性能評測基準系統配置及其原理》。
- 對齊對齊再對齊。預取預取再預取。極度重視cache的優化。對齊主要是針對CacheLine 長度以及 PCIE的DMA地址。預取Prefetch 則較為難以把握精確的時間點, 需要反復的實驗找到最佳位置。細節請參考Intel 軟件優化手冊(https://software.intel.com/content/www/us/en/develop/download/intel-64-and-ia-32-architectures-optimization-reference-manual.html)
- 隔離Core 不讓Core參與操作系統的調度。減少抖動。禁止進程切換,盡量減少系統調用,這些都會引起嚴重的抖動。細節請參考之前的公號文章(https://mp.weixin.qq.com/s/nkiE4CEo_zSN35I_qITAvQ)
- 針對X86微架構。無所不用其極地進行優化。例如 write forwarding. 細節請參考Intel 軟件優化手冊
- 廣泛使用二階遞進的分區設計模式。盡量避免核間通信(例如mem pool/local pool etc) 細節請參考DPDK 官方文檔
- 廣泛使用無鎖隊列以及相關精巧的數據結構設計。例如著名的rte_ring。細節請參考DPDK 官方文檔
經過這樣層層遞進聯合的優化, DPDK終于站上了性能的巔峰。
但是故事并沒有結束。X86有一個比較突出的問題,就是關于價格。那么每一個X86 Xeon核心的價格并不便宜。所以當一些業務流程逐漸沉淀下來比較固化以后,又可以重新的轉化為ASIC來處理。這樣就催生了各類的Smart NIC,繞了個圈又回到了IXP 。只是如今微引擎(或者類似的可編程組件)都集成進了網卡。這些恰恰印證了技術的發展是一個螺旋上升的過程,永遠是圍繞著性能/價格進行動態平衡調整。
DPDK與內核的關系
這個話題通常是一個DPDK廣泛被誤解的地方。我覺得既有競爭關系,但是又有非常密切的合作關系。
首先我們來談競爭。DPDK和Linux 內核進行競爭的僅僅是Linux內核協議棧中關于包轉發處理的一小部分。那么這一部分由于Linux內核協議棧性能常年非常的低下。當然,這也是Linux 內核的一些設計哲學導致的.其實并不算是設計失誤而是追求的目標不同。那么這一部分確實是存在競爭關系,但是值得一提的是 DPDK同時也催生了Linux 內核中的新的包處理框架XDP 以及AF_XDP這些新興的技術。也算是既競爭又促進。關于某些內核協議棧maintainer一些過于戲劇化的行為,竊以為看看就好, 畢竟想想DPDK的編碼風格,開發管理流程, 大多還是跟隨內核社區。
那么合作的這一部分呢?其實就非常之多了。
首先DPDK所用到的所有基礎架構:
- UIO/VFIO/IOMMU這些框架無一不是由內核來提供的。
- Hugepage 以及Systemmap 地址查找都是依賴內核
- 所有的sysfs,不用說都要依賴。
- 電源管理的框架完全根植于cpufreq/idle 這兩個內核的子系統
- 每次新一代的處理器的支持
- 周邊的生態linker loader debuger compiler perf etc
- 虛擬化的支持也要依賴kvm/qemu
- 你可以想到的更多。
展望未來
在通信技術高速發展的今天,DPDK 面臨很多新的挑戰:
- 使用如此高配得core來polling,浮點單元、極致的亂序引擎沒有充分發揮效用,同時價格上還是不便宜的,那么在性價比上就會面臨DPU的挑戰。最終應該是多種方案并存的狀態。
- 100%的cpu占用使得真正的cpu使用比例很難被監測到,同時能耗也是一個問題,當然這個方面已經有很多改進的方案在社區進行討論。
- 擴展生態,開源的魯棒性高的協議棧仍然是稀缺的
- 同樣是生態問題,與控制平面的接口如何優化也是一大方向。
- 在Cloud Native 的大趨勢下, 如何進化、適應。
這些問題都有待通過整個DPDK社區的繼續努力來解決。
參考
https://www.dpdk.org/wp-content/uploads/sites/35/2014/09/DPDK-SFSummit2014-HighPerformanceNetworkingLeveragingCommunity.pdf
http://dpdk.org
https://www.intel.com/content/www/us/en/io/data-direct-i-o-technology-brief.html
https://software.intel.com/content/www/us/en/develop/download/intel-64-and-ia-32-architectures-optimization-reference-manual.html
https://lwn.net/Articles/374424/
作者簡介
作者Liam,海外老碼農,對應用密碼學、CPU微架構、高速網絡通信等領域都有所涉獵。
本文轉載自微信公眾號「Linux閱碼場」,可以通過以下二維碼關注。轉載本文請聯系Linux閱碼場公眾號。