AI領(lǐng)域 | 改變游戲規(guī)則的十個(gè)突破性觀(guān)點(diǎn)
從我的AI之旅開(kāi)始,我發(fā)現(xiàn)了一些具有無(wú)窮潛力的想法和概念,它們?cè)谳x煌的歷史上留下了自己的印記。
今天,我決定整理一些最有趣的想法和概念的清單(根據(jù)我自己的經(jīng)驗(yàn)),這些想法和概念讓我這些年來(lái)都堅(jiān)持不懈。希望他們也能像激勵(lì)我一樣激勵(lì)你。
因此,讓我們從AI愛(ài)好者的“初戀”開(kāi)始。
1.神經(jīng)網(wǎng)絡(luò)-“來(lái)自仿生學(xué)的靈感”
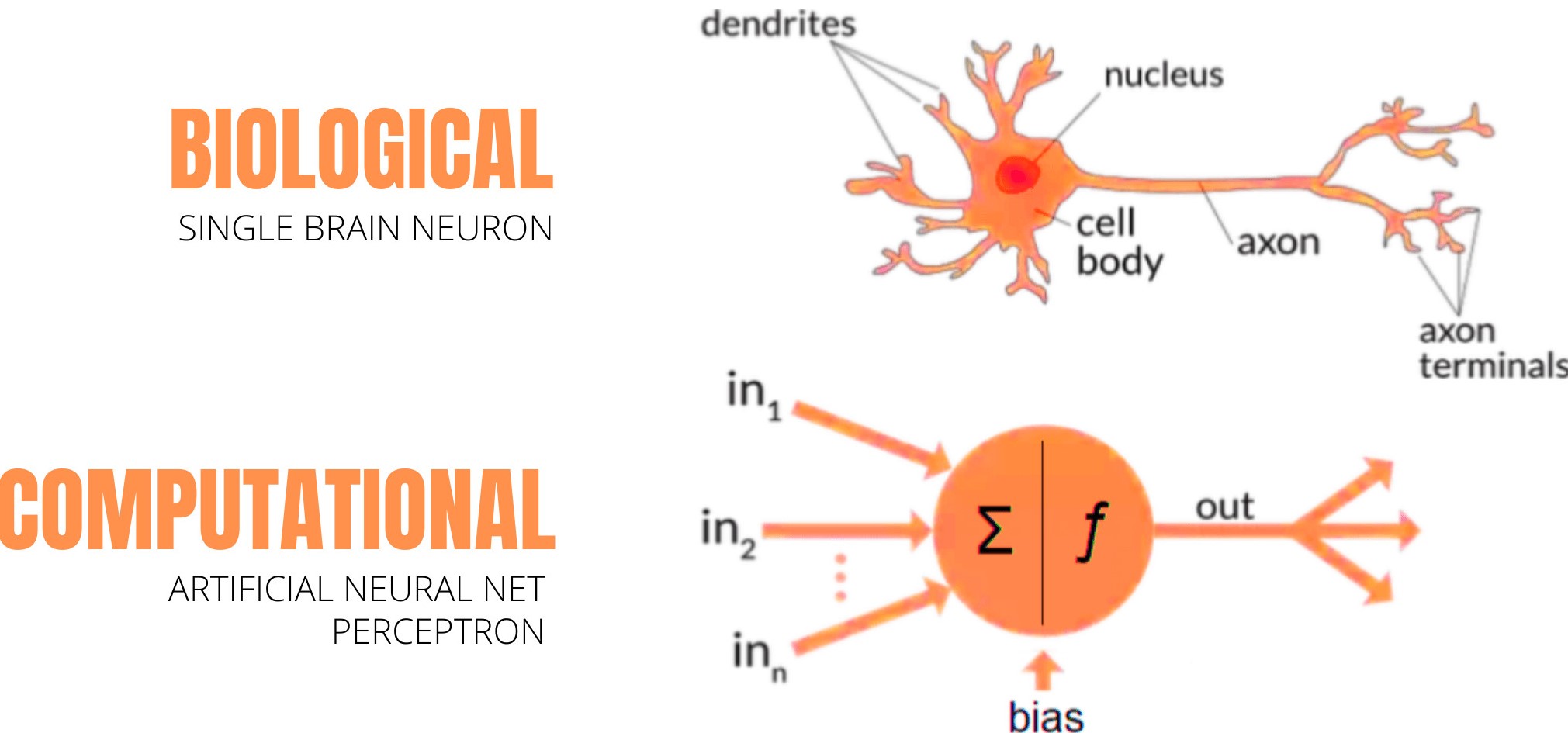
每個(gè)使用統(tǒng)計(jì)模型(例如回歸模型和所有模型)的新機(jī)器學(xué)習(xí)(Machin Learning,ML)開(kāi)發(fā)人員,在首次學(xué)習(xí)人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Networks,ANN)時(shí)都經(jīng)歷了腎上腺素激增的過(guò)程;這是處在深度學(xué)習(xí)的門(mén)口。
這里,基本思想是通過(guò)編程來(lái)模仿生物神經(jīng)元的工作,實(shí)現(xiàn)通用函數(shù)逼近。
神經(jīng)科學(xué)和計(jì)算機(jī)科學(xué)這兩個(gè)領(lǐng)域的融合本身就是一個(gè)令人興奮的想法。 我們將在以后進(jìn)行詳細(xì)探討。
數(shù)學(xué)上,突觸和連接如何濃縮為大規(guī)模的矩陣乘法; 神經(jīng)元的放電與激活函數(shù)如何類(lèi)似,如S函數(shù)(sigmoid); 大腦中的高級(jí)認(rèn)知抽象和人工神經(jīng)網(wǎng)絡(luò)的黑匣子聽(tīng)起來(lái)如何既神秘又酷。 所有的這些給新的ML開(kāi)發(fā)人員帶來(lái)了希望,這是不可思議的。
圖源:作者提供(Canva制作)
在這一點(diǎn)上,新手認(rèn)為:“從根本上說(shuō),這種受生物啟發(fā)的技術(shù)可以實(shí)現(xiàn)一切。 畢竟,大自然選擇了執(zhí)行流程的最佳、最有效的方式,難道不是嗎?”
只有在以后的課程中,他們才會(huì)學(xué)習(xí)ANN的部分啟發(fā)方式,因此仍會(huì)有很大的局限性。
從理論上講,一切聽(tīng)起來(lái)都不錯(cuò),但他們不切實(shí)際的雄心勃勃的夢(mèng)想就消失了,就像在錯(cuò)誤配置的神經(jīng)網(wǎng)絡(luò)訓(xùn)練課程中的梯度一樣(get到這個(gè)點(diǎn)了嗎?哈哈)。
2.基因算法-“向達(dá)爾文問(wèn)好”
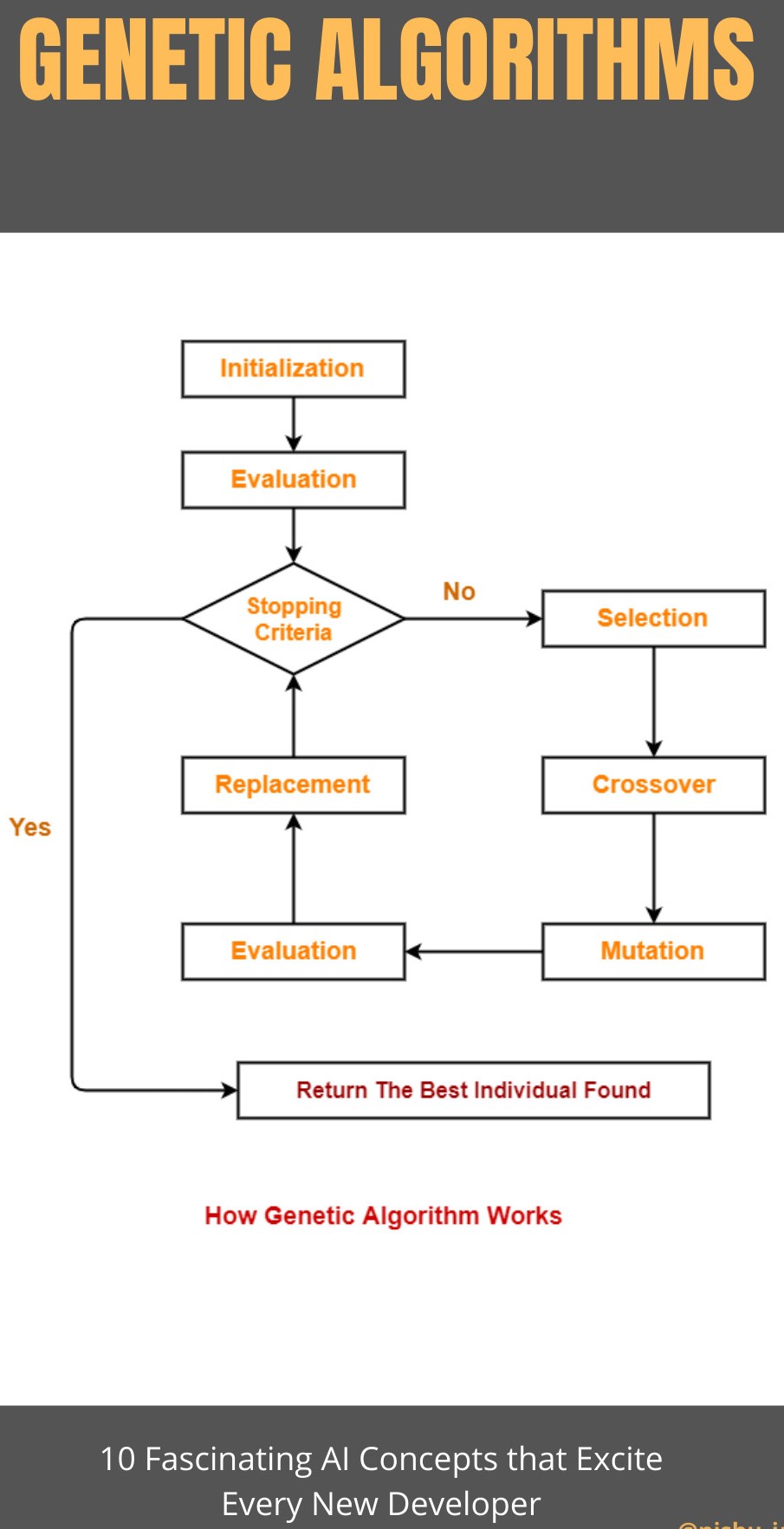
基因算法是另外一類(lèi)可以應(yīng)用于計(jì)算機(jī)科學(xué)領(lǐng)域的受自然啟發(fā)得到的算法。在這里你會(huì)找到與達(dá)爾文進(jìn)化論有關(guān)所有的術(shù)語(yǔ),有如-突變,繁衍,人口,交叉,適者生存等等。
這些進(jìn)化算法背后的思想是遵循自然選擇,只有最適應(yīng)環(huán)境的個(gè)體才有機(jī)會(huì)繁衍后代。而為了在人口中增加一些多樣性,最適應(yīng)環(huán)境的個(gè)體所擁有的染色體每過(guò)一段時(shí)間就會(huì)隨機(jī)地突變一次。
在這里,“個(gè)體”指的是給定問(wèn)題的一個(gè)可能的答案
來(lái)看一下它的工作流
圖源:來(lái)自于作者(使用Canva設(shè)計(jì)出來(lái)的)
簡(jiǎn)潔明了,不是嗎?
這個(gè)看起來(lái)簡(jiǎn)單的算法在現(xiàn)實(shí)世界中可以應(yīng)用在很多場(chǎng)景,例如-優(yōu)化,遞歸神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過(guò)程,某些問(wèn)題解決任務(wù)的平行化,圖像處理之類(lèi)的。
盡管有這么多的可行方向,基因算法目前還沒(méi)有任何實(shí)際成果。
3.自我編輯程序 -“需要小心的程序員”
作為基因算法應(yīng)用的延續(xù),這一個(gè)當(dāng)然是最令人興奮的,而它也值得擁有一個(gè)獨(dú)立的小節(jié)。
想象存在一個(gè)AI程序可以修改它自身的源代碼。它一次又一次地改進(jìn)著自己,循環(huán)多次,直到它最終實(shí)現(xiàn)了自己的目標(biāo)。
很多人相信,
自我改進(jìn)/編輯代碼+AGI=AI超級(jí)智慧
顯然,要實(shí)現(xiàn)這個(gè)方法還存在有很多困難,但想一下2013年的這個(gè)實(shí)驗(yàn):一個(gè)基因算法可以用Brainfuck(一種編程語(yǔ)言)來(lái)構(gòu)造一個(gè)可以打印出“hello”的程序。
那個(gè)基因算法的源代碼中沒(méi)有寫(xiě)入任何的編程原則,只是一個(gè)樸素,古老的自然選擇算法。在29分鐘之內(nèi),它生成了這個(gè)-
+++><>.]]]]
當(dāng)你在Brainfuck編譯器中運(yùn)行這段代碼時(shí),它會(huì)打印“hello”。這個(gè)實(shí)驗(yàn)成功了!
這證實(shí)了基因算法的威力,也展現(xiàn)出了在給予足夠的時(shí)間和計(jì)算資源下它的能力。
4.神經(jīng)常微分方程 -“螺旋層”
回到幾年前,在4854份遞交到NeurIPS的研究論文中,這篇名為“神經(jīng)常微分方程”的論文脫穎而出,成為了最好的4篇論文之一。
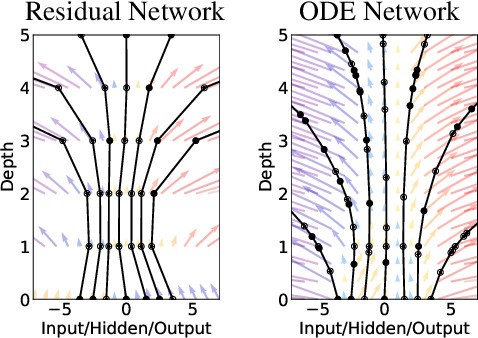
它有什么了不起的呢?因?yàn)樗_切地改變了我們對(duì)神經(jīng)網(wǎng)絡(luò)的看法。
傳統(tǒng)意義上的神經(jīng)網(wǎng)絡(luò)擁有的層數(shù)是離散的,同時(shí)依賴(lài)于梯度下降和反向傳播來(lái)進(jìn)行優(yōu)化(尋找全局最小值)。當(dāng)我們?cè)黾訉訑?shù)時(shí),我們的內(nèi)存消耗也在增加,但我們不再需要那么做,理論上說(shuō)。
我們可以從離散層模型轉(zhuǎn)換成連續(xù)層模型-從而擁有無(wú)限層。
源:上面提到的研究論文
我們不需要事先確定層數(shù)。而是輸入你想要的精確度然后看著以常數(shù)內(nèi)存為代價(jià)的魔術(shù)發(fā)生。
根據(jù)這篇論文,這個(gè)方法在時(shí)間序列數(shù)據(jù)中(特別是不規(guī)則的時(shí)間序列數(shù)據(jù))比傳統(tǒng)的遞歸神經(jīng)網(wǎng)絡(luò)和殘差網(wǎng)絡(luò)的表現(xiàn)都要更好。
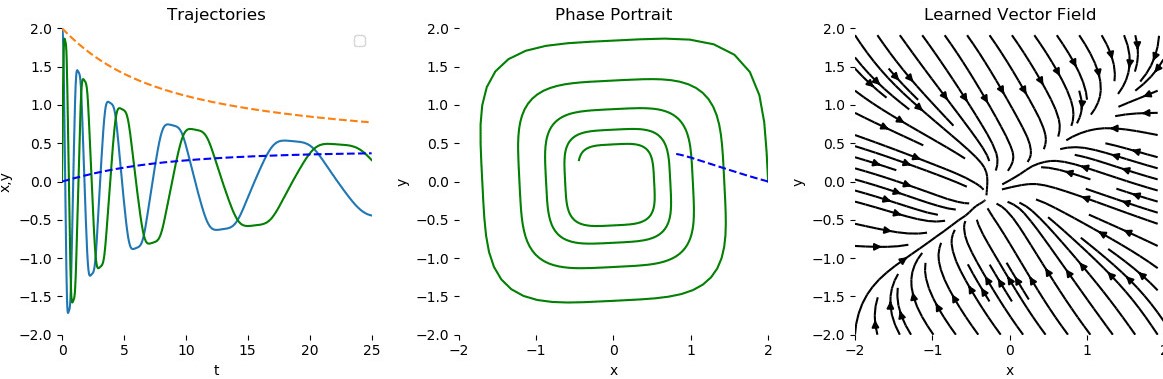
源:上面提到的研究論文
利用這種新的技術(shù),我們可以使用任何常微分方程求解器(OOE Solver),像是歐拉方法來(lái)取代梯度上升,使得整個(gè)過(guò)程更有效率。
而且正如你所知,時(shí)間序列數(shù)據(jù)無(wú)所不在-從證券市場(chǎng)的金融數(shù)據(jù)到醫(yī)療保健產(chǎn)業(yè),因此一旦這項(xiàng)技術(shù)成熟它的應(yīng)用將十分廣泛。但它目前仍然有待發(fā)展。
希望它能往好的方向發(fā)展吧!
5.神經(jīng)進(jìn)化-“再一次地模仿自然”
神經(jīng)進(jìn)化是一個(gè)過(guò)去的想法,最早可以追溯到二十一世紀(jì)初期,由于最近在強(qiáng)化學(xué)習(xí)的領(lǐng)域中和著名的反向傳播算法進(jìn)行比較而顯示出其前景和發(fā)展。比如在神經(jīng)架構(gòu)搜索,自動(dòng)機(jī)器學(xué)習(xí),超參數(shù)優(yōu)化等領(lǐng)域。
用一句話(huà)來(lái)說(shuō),“神經(jīng)進(jìn)化是一項(xiàng)利用基因算法改進(jìn)神經(jīng)網(wǎng)絡(luò)的技術(shù)”,不僅僅可以改進(jìn)權(quán)重和參數(shù),還能改進(jìn)網(wǎng)絡(luò)的(拓?fù)洌┙Y(jié)構(gòu)(最新的研究)。
這是一場(chǎng)梯度下降優(yōu)化算法和進(jìn)化優(yōu)化算法在訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型上的戰(zhàn)役。

源:https://blog.otoro.net
但我們?yōu)槭裁匆褂盟兀?/p>
因?yàn)椋赨ber最近的研究中(深度神經(jīng)進(jìn)化),他們發(fā)現(xiàn)這項(xiàng)技術(shù)比起反向傳播可以使模型更快的收斂。在比較低端的PC上幾天的計(jì)算時(shí)間可以縮短為幾個(gè)小時(shí)。
如果你正在用梯度下降訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)并卡在了像局部最優(yōu)點(diǎn)或者梯度彌散的地方,那么神經(jīng)進(jìn)化可以幫你得到更好的結(jié)果。
你不需為這項(xiàng)替換付出。在每個(gè)神經(jīng)網(wǎng)絡(luò)被應(yīng)用到的場(chǎng)所,這項(xiàng)技術(shù)都可以被用來(lái)優(yōu)化并訓(xùn)練它們。
“兩個(gè)腦袋比一個(gè)腦袋來(lái)的要好,不是因?yàn)橛心硞€(gè)腦袋不容易出錯(cuò),而是因?yàn)樗鼈儾惶赡芊竿环N錯(cuò)誤。"-C.S Lewis
6.谷歌的AI孩子-”AI創(chuàng)造AI“
調(diào)整超參數(shù)是一項(xiàng)每個(gè)數(shù)據(jù)科學(xué)家都深?lèi)和唇^的繁瑣而又無(wú)聊的任務(wù)。由于神經(jīng)網(wǎng)絡(luò)實(shí)際上是一個(gè)黑盒子,我們無(wú)法明確地知道我們改變的超參數(shù)會(huì)如何影響一個(gè)網(wǎng)絡(luò)的學(xué)習(xí)。
在2018年,谷歌在自動(dòng)機(jī)器學(xué)習(xí)(AutoML)的世界中作出了一項(xiàng)突破,制作出了一個(gè)叫做NASNet的模型。這個(gè)物品識(shí)別模型擁有82.7%的準(zhǔn)確率,比計(jì)算機(jī)視覺(jué)領(lǐng)域內(nèi)的其他任何模型都要高1.2%,同時(shí)效率還要至少高出4%。
最重要的是,它是通過(guò)使用強(qiáng)化學(xué)習(xí)的方法,在另外一個(gè)AI的幫助下發(fā)展而成的。

圖源:谷歌研究院
“神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)”。。。這確實(shí)是一個(gè)驚人的想法,你不這么認(rèn)為嗎?
在這里,它的家長(zhǎng)AI叫做Controller network(控制者網(wǎng)絡(luò)),它在數(shù)千次的迭代中逐步培養(yǎng)出其AI孩子。在每次迭代中,它計(jì)算出孩子的性能并使用這個(gè)信息來(lái)在下一次迭代中建造一個(gè)更好的模型。
這種創(chuàng)造性的思考方式推動(dòng)了”學(xué)會(huì)學(xué)習(xí)“的概念(或者元學(xué)習(xí)),從而不論是從準(zhǔn)確性還是效率都可以擊敗這個(gè)星球上任何人類(lèi)所設(shè)計(jì)出來(lái)的神經(jīng)網(wǎng)絡(luò)。
想象一下在計(jì)算機(jī)視覺(jué)的領(lǐng)域之外它還能做什么。難怪這個(gè)概念激起了人們對(duì)于超級(jí)過(guò)載人工智慧最深的恐懼。
7. GANs-”神經(jīng)網(wǎng)絡(luò) vs. 神經(jīng)網(wǎng)絡(luò)“
GAN是生成式對(duì)抗網(wǎng)絡(luò)的簡(jiǎn)寫(xiě),它們可以學(xué)會(huì)模仿任意的數(shù)據(jù)分布。
這是什么意思呢?
在GANs之前,機(jī)器學(xué)習(xí)算法專(zhuān)注于尋找輸入和輸出之間的關(guān)聯(lián)。它們被叫做判別算法。例如,一個(gè)圖像分類(lèi)器可以區(qū)分蘋(píng)果和橙子。
當(dāng)你把一張照片輸入到網(wǎng)絡(luò)中時(shí),它或返回0(我們讓它指代蘋(píng)果)或者返回1(指橙子)。你可以認(rèn)為它在分配標(biāo)簽。它在內(nèi)部創(chuàng)建了一個(gè)模型,確定了哪些特征對(duì)應(yīng)了蘋(píng)果,哪些特征對(duì)應(yīng)了橙子,然后吐出一個(gè)帶有一定概率的標(biāo)簽。。
然而。。。盡管它們?cè)趦?nèi)部可能有辦法用某種方式表示蘋(píng)果和橙子從而對(duì)它們進(jìn)行比較,但它們沒(méi)有辦法生成出蘋(píng)果和橙子的圖片。
這里就是GANs拿手的地方。一個(gè)GAN包含了兩個(gè)網(wǎng)絡(luò)-一個(gè)生成器和一個(gè)鑒別器。
沿用之前的例子,如果我們想要生成一張?zhí)O果的照片,那么我會(huì)使用一個(gè)解卷積網(wǎng)絡(luò)來(lái)作為我的生成器以及一個(gè)卷積網(wǎng)絡(luò)來(lái)作為我的鑒別器。
這個(gè)生成器一開(kāi)始只會(huì)生成一張隨機(jī)的噪聲圖像并試著讓它看起來(lái)像是一個(gè)蘋(píng)果。另一方面,鑒別器會(huì)試著鑒別出輸入的圖片是真實(shí)的還是偽造的(由生成器所生成)。
如果鑒別器可以正確地區(qū)分出圖片,那么生成器就要努力改進(jìn)自己去生成出更加真實(shí)的圖片。同時(shí)鑒別器也努力提高自己的判別能力。這意味著,不管如何,改進(jìn)都是不可避免的,問(wèn)題只是它發(fā)生在鑒別器身上還是生成器身上而已。
這看起來(lái)有點(diǎn)像一種雙重反饋循環(huán)。
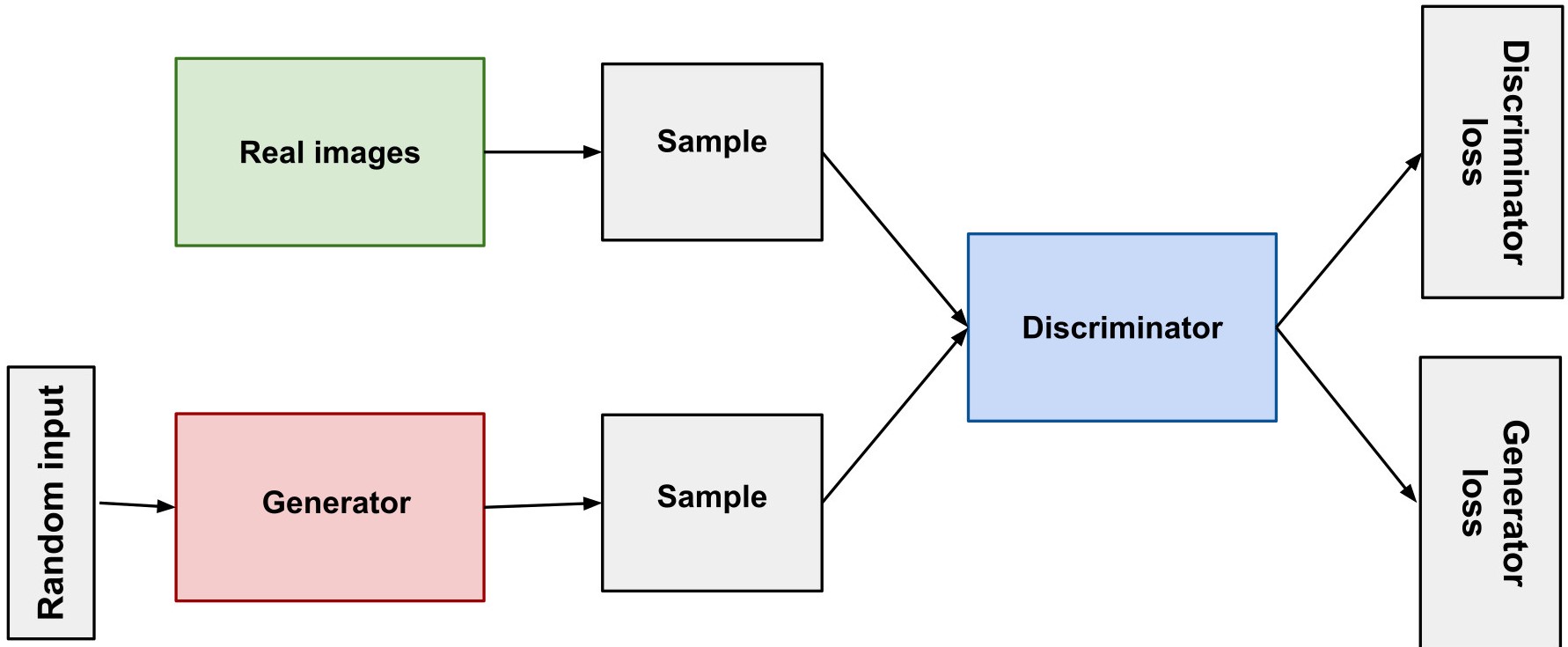
GANs的復(fù)雜性使得它們難以訓(xùn)練,最近在英偉達(dá)發(fā)布的一篇研究論文中他們描述了一種方法,通過(guò)漸進(jìn)地改進(jìn)生成器和鑒別器來(lái)訓(xùn)練GANs。(有趣的說(shuō)法!)。
關(guān)于GAN的機(jī)制我們說(shuō)的足夠多了,那么我們?cè)撊绾问褂盟兀?/p>
一些酷炫的GAN的應(yīng)用:
- 使面孔變老
- 超高分辨率
- 圖像混合
- 衣服轉(zhuǎn)換
- 3D物體生成,之類(lèi)的。
更多信息可以參見(jiàn)這篇文章。
8.遷移學(xué)習(xí)-”使用預(yù)先訓(xùn)練好的網(wǎng)絡(luò)“
從零開(kāi)始訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)是需要昂貴的計(jì)算成本,有時(shí)還會(huì)變得非常混亂。但試想一下我們可以從另外一個(gè)以前在其他數(shù)據(jù)集上已經(jīng)訓(xùn)練好的網(wǎng)絡(luò)中獲取知識(shí),并將其重新用在我們新的目標(biāo)數(shù)據(jù)集的訓(xùn)練過(guò)程中。
這樣子,我們可以加速在新的領(lǐng)域上進(jìn)行學(xué)習(xí)的過(guò)程并且節(jié)省大量的計(jì)算能耗和資源。可以把它想成是一場(chǎng)起點(diǎn)比其他人要靠前的跑步比賽。
不要把你的時(shí)間浪費(fèi)在重復(fù)造輪子上
顯然,你不可以把這項(xiàng)技術(shù)用在兩個(gè)毫不相關(guān)的領(lǐng)域上,但在一些領(lǐng)域上-自然語(yǔ)言處理和計(jì)算機(jī)視覺(jué),使用已經(jīng)訓(xùn)練好的網(wǎng)絡(luò)是一種新的規(guī)范
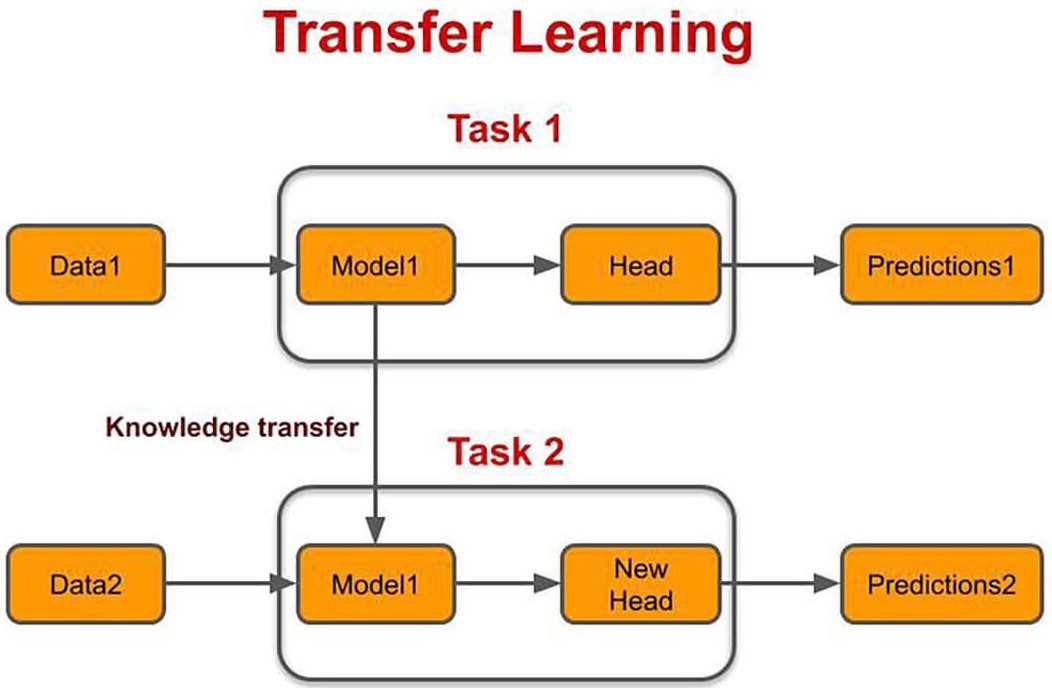
Source:https://www.topbots.com/
計(jì)算機(jī)視覺(jué)領(lǐng)域中,在物品偵測(cè),物品識(shí)別,和圖像分類(lèi)任務(wù)中,人們會(huì)使用像VGG ConvNet,AlexNet,ResNet-50,InceptionV3,EfficientNet之類(lèi)的已經(jīng)預(yù)訓(xùn)練好的網(wǎng)絡(luò)。特別是在任務(wù)剛開(kāi)始的階段。
即使是在像神經(jīng)風(fēng)格轉(zhuǎn)移(NST)這樣的任務(wù)上,你可以使用VGG19來(lái)迅速獲取內(nèi)在表示從而節(jié)省時(shí)間。
在如情感識(shí)別和語(yǔ)言翻譯的NLP任務(wù)中,各類(lèi)的不同詞向量嵌入方法如斯坦福的GloVe(表示詞匯的全局向量)或者谷歌的Word2Vec都是標(biāo)配。
我不想提及那些最新的語(yǔ)言模型(那些大家伙)如谷歌的BERT,OpenAI的GPT-2(生成式預(yù)訓(xùn)練Transformer),和全能的GPT-3。他們都是在我們這些平民難以想象的海量的信息中訓(xùn)練出來(lái)的。他們幾乎把整個(gè)網(wǎng)絡(luò)作為他們的輸入數(shù)據(jù)集并花費(fèi)了數(shù)百萬(wàn)美元來(lái)進(jìn)行訓(xùn)練。
從這一點(diǎn)而言,它看起來(lái)像是未來(lái)我們使用的預(yù)訓(xùn)練網(wǎng)絡(luò)。
9.神經(jīng)形態(tài)架構(gòu) -”次世代材料“
在看了那么多軟件世界的進(jìn)展之后,我們來(lái)關(guān)注一下硬件部分。
但在那之前,先來(lái)看一下這個(gè)荒謬的對(duì)比。。。
人類(lèi)的腦子里平均有860億個(gè)神經(jīng)元和大約1千萬(wàn)億突觸。直觀(guān)地說(shuō),你實(shí)際上可以通過(guò)解開(kāi)你的腦子來(lái)到達(dá)月球(用400000千米長(zhǎng)的神經(jīng)纖維)。
如果你想要模擬你的腦子,你需要消耗大量的計(jì)算能源(1百億億次運(yùn)算),這是在現(xiàn)有的技術(shù)水平上無(wú)法實(shí)現(xiàn)的。
即使是最強(qiáng)大的超級(jí)計(jì)算機(jī)也無(wú)法實(shí)現(xiàn)這么大的運(yùn)算量,更別提我們的大腦僅僅需要20瓦的電力(比點(diǎn)燃一個(gè)燈泡還少)就可以做到這種程度。
為什么?因?yàn)?rdquo;架構(gòu)“
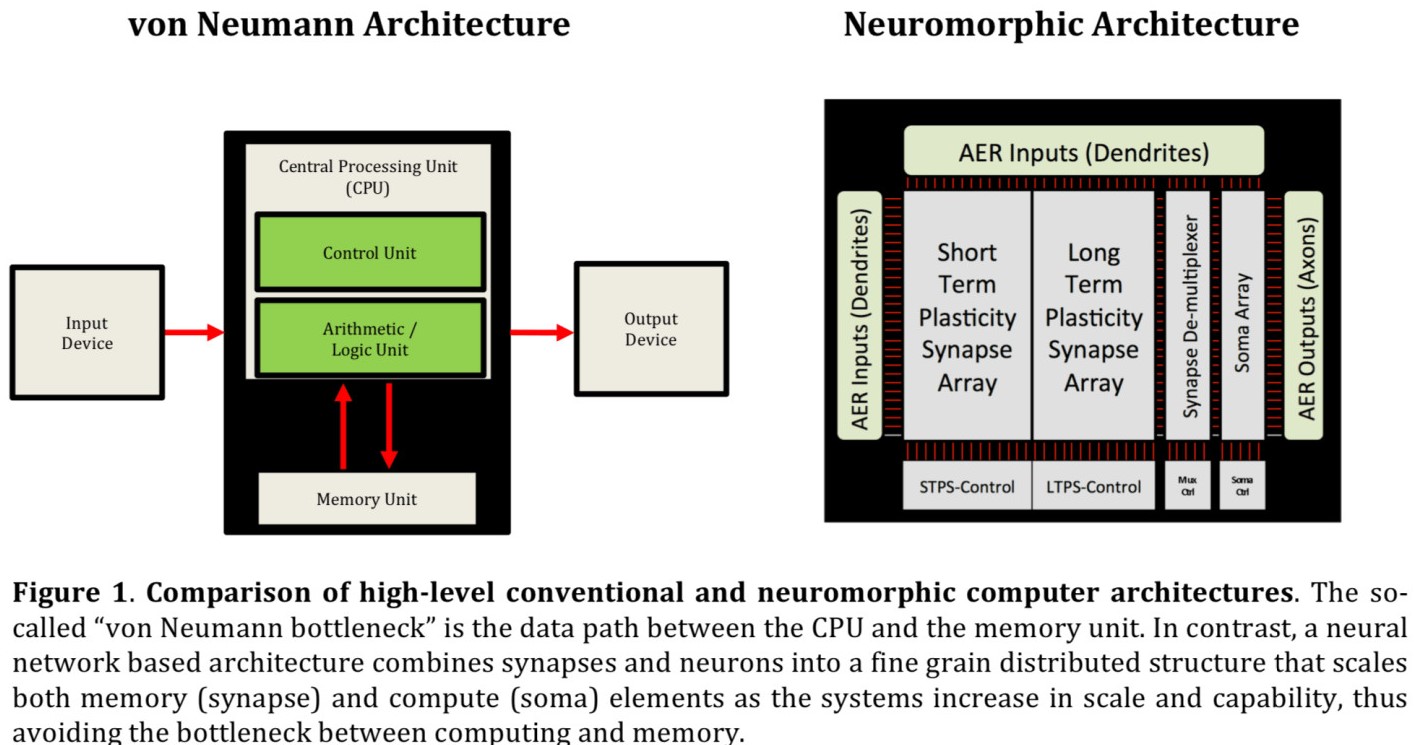
圖源:https://randommathgenerator.com/
你知道嗎,今天我們用到的每一臺(tái)計(jì)算機(jī)都是基于一個(gè)有75年歷史的架構(gòu),即馮諾依曼架構(gòu)。在這個(gè)架構(gòu)中,內(nèi)存和處理器是相互分離的,這使得我們?cè)趫?zhí)行大運(yùn)算量的任務(wù),如大型矩陣乘法,時(shí)存在著性能瓶頸。
這個(gè)馮諾依曼瓶頸的產(chǎn)生是因?yàn)槲覀儓?zhí)行一系列指令的時(shí)候傳入輸入和得到輸出的過(guò)程是有順序的。但在我們的腦子中,進(jìn)行記憶和處理的單元本質(zhì)上是同一個(gè),這使得它可以用閃電般的速度處理巨量的數(shù)據(jù)同時(shí)只需要消耗極小量的能量。在這里,連接記憶和處理單元的就是記憶本身。
有一些公司例如IBM和Intel正嘗試模擬一個(gè)像我們生物的腦子一樣的架構(gòu)。它最終會(huì)催生出一種新的計(jì)算方式,神經(jīng)形態(tài)計(jì)算。
使用多塊GPU和TPU的日子就要到頭了。我真的迫不及待那一天的到來(lái)!
進(jìn)展:IBM的真北芯片和Intel的神經(jīng)形態(tài)芯片。
10.通用人工智能(AGI)-“我們的終極目標(biāo)”
當(dāng)你聽(tīng)到有人嘶喊到“總有一天,AI會(huì)把我們都?xì)⒐狻?rdquo;那么通用人工智能最有可能做出這樣的事情。
為什么?
因?yàn)楝F(xiàn)在我們正在處理的是“弱人工智能”意思是我們現(xiàn)在的模型在它們的特定領(lǐng)域之外一無(wú)是處。但是,全球的科學(xué)家和研究人員都在致力于產(chǎn)生一種可以完成各類(lèi)任務(wù),或者能學(xué)會(huì)完成幾乎任何給定任務(wù)的人工智能。
如果他們成功了,可以預(yù)測(cè)到的是,這會(huì)導(dǎo)致智慧爆炸,遠(yuǎn)超人類(lèi)的智慧并最終催生出超級(jí)智能。
當(dāng)這件事發(fā)生的時(shí)候,那個(gè)超級(jí)智能會(huì)變成一個(gè)擁有知覺(jué),自我意識(shí),以及更高的認(rèn)知能力的存在。
源:https://www.theverge.com(實(shí)在忍不住放上這張照片)
之后會(huì)發(fā)生什么?只有天知道。
有一個(gè)專(zhuān)門(mén)的詞來(lái)形容這種情況。Singularity是一個(gè)假設(shè)的時(shí)間點(diǎn),到那個(gè)時(shí)候技術(shù)發(fā)展會(huì)變得不可控且不可逆,最終對(duì)人類(lèi)文明產(chǎn)生不可預(yù)見(jiàn)的改變。-維基百科
我們不能簡(jiǎn)單地停止它的發(fā)展嗎?不。
人工智能就像是今天的電能一樣。我們對(duì)它擁有著重度依賴(lài),停止它的發(fā)展就像是回到黑暗時(shí)代。此外,沒(méi)有國(guó)家會(huì)停止它的發(fā)展因?yàn)橛幸环N共同的心態(tài)-”即使我們不發(fā)展,他們也會(huì)“-就像我們制造具有大規(guī)模殺傷力的核武器時(shí)的心態(tài)。
埃隆馬斯克的擔(dān)心并非空穴來(lái)風(fēng)。他是認(rèn)真的。
總結(jié)
我覺(jué)得已經(jīng)說(shuō)出了一些制造一個(gè)完美AI的方法的要點(diǎn)。但誰(shuí)在乎呢?除非我們有辦法和他們共存。
我希望在Neuralink工作的人們能夠在世界末日之前完成他們的人腦-機(jī)器接口。且埃隆馬斯克設(shè)法在不把我們的腦子暴露給新世代黑客的情況下使用它。