













戴爾易安信DSS 8440服務器|業界首款采用Graphcore技術的機器學習服務器
在過去的一年里,許多行業受疫情沖擊發展陷入停滯,人工智能應用卻實現了逆勢突破。在世界人工智能大會WAIC2020上,李蘭娟院士表示,AI在疫情防控中,發揮了重要作用。
此外,AI在無人駕駛汽車等前沿領域也持續發力;在AI頂層設計方面,國家也不遺余力積極制定相關標準,出臺了《國家新一代人工智能標準體系建設指南》,為人工智能的規范發展掃平障礙。
AI高速發展的背后,離不開“燃料”算力的助推。算力作為AI 2.0的四大要素之一,為人工智能提供計算能力的支撐。
需求倒逼創新
AI芯片行業將迎變革
在過去的幾十年里,基于摩爾定律,芯片行業的發展一直推動著芯片制程和性能的穩步提升,算力需求的增長也促進了人工智能工作負載中大量采用專用的AI加速器(GPU、FPGA、ASIC、xPU等)。
與傳統的CPU架構相比,這些加速器能夠執行更快的AI作業和并行計算。它們為有效執行控制ML/DL工作負載提供了專門的支持。
現在市場上已經有各類 AI加速器:GPU、FPGA、ASIC等等,各種各樣的計算平臺被運用到AI計算中。之所以會出現這么多各種形式的 AI 芯片,正是因為算法的多元化,例如機器學習算法有 LR、GBDT,深度學習中的 CNN、DNN 等,這些算法都非常復雜,如果機器要很快地讓這些算法“跑”起來,一定需要算法的邏輯跟芯片計算的邏輯相互匹配。
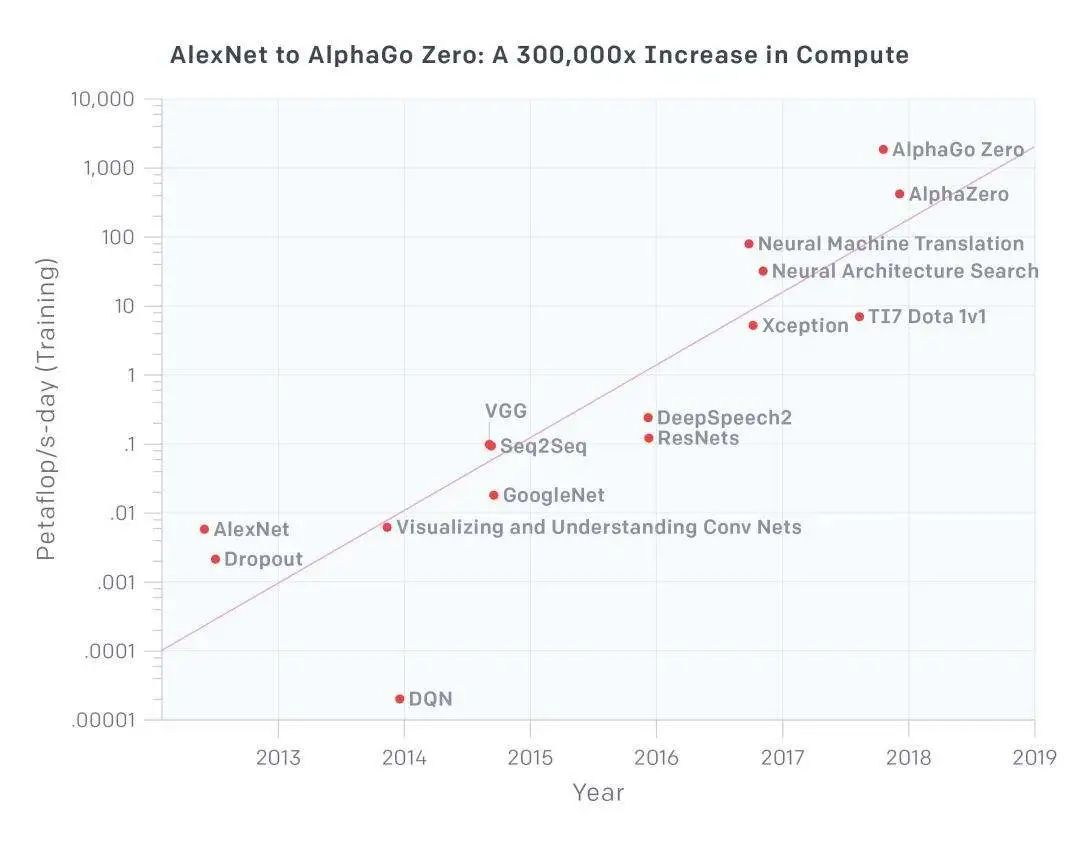
據OpenAI組織發布的一份分析報告顯示,自2012年以來,在人工智能訓練中所使用的計算量呈指數級增長,3.5個月的時間計算量就翻了一倍(相比之下,摩爾定律有18個月的倍增周期)。自2012年以來,該指標增長了30多萬倍。按照這個趨勢,想要滿足未來AI發展的需求,芯片行業勢必要有所變革。
Graphcore IPU:專為人工智能而生
一種全新的完全可編程處理器
Graphcore是一家創辦于2016年的人工智能芯片設計初創公司,總部位于英國,以“專注于新型 AI 處理器架構,專門適用于算力密集型的機器學習任務”,入選2020年度《麻省理工科技評論》“50家聰明公司”榜單。該公司開發了一款被稱為IPU智能處理單元(intelligence processing unit)的新型AI加速器。
Graphcore IPU是專門為AI/Machine Learning設計的處理器,擁有完全不同于前面幾類處理器類型的全新架構,能夠提供強大的并行處理能力。Graphcore IPU區別于其他處理器的一個重要因素還在于,它實現了快速訓練模型和實時操控,這使得它能夠在自然語言處理以及理解自動駕駛方面取得重大進展。

Graphcore 的IPU特點可概括為:
- 同時支持 Training 和 Inference;
- 采用同構多核(many-core)架構,超過1000個獨立的處理器;
- 支持 all-to-all的核間通信,采用Bulk Synchronous Parallel的同步計算模型;
- 采用大量片上SRAM,不需要外部DRAM。

據介紹,IPU處理器是迄今為止最復雜的處理器芯片,它在一個16納米芯片上有幾乎240億個晶體管,每個芯片提供125 teraFLOPS運算能力。一個標準4U機箱中可以插入8張卡,卡間通過IPU-Link互連。8張卡上的IPU可以看做一個處理器工作,提供 1.6PetaFLOPS的運算能力。
與GPU爭鋒?
IPU:沒在怕的
英偉達公司率先于1999年提出GPU的概念,GPU使顯卡減少了對CPU的依賴,然而隨著模型越來越大,參數越來越多,面對高精度高吞吐量的需求,算力優勢顯著的IPU也許更能代表AI芯片的發展方向。
Graphcore IPU在現有以及下一代模型上的性能均優于GPU,在自然語言處理方面的速度能比GPU快25%到50%;在圖像分類方面,吞吐量7倍于GPU,而且時延更低。
Natural Language Processing-BERT
BERT (Bidirectional Encoder Representations from Transformers)是目前使用的最著名的NLP模型之一。IPU加速了BERT的訓練和推理,在極低延遲的情況下, IPU能夠進行實現2倍于目前解決方案的吞吐量,同時延遲性能比當前的解決方案提升1.3倍。
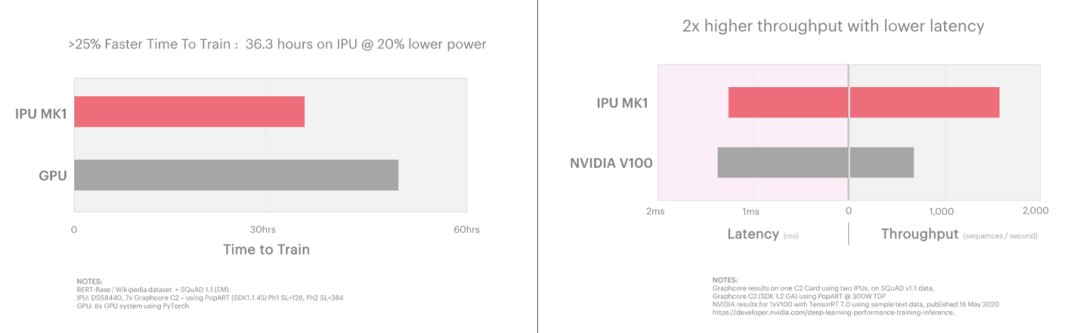
計算機視覺:EfficientNet & ResNeXt模型
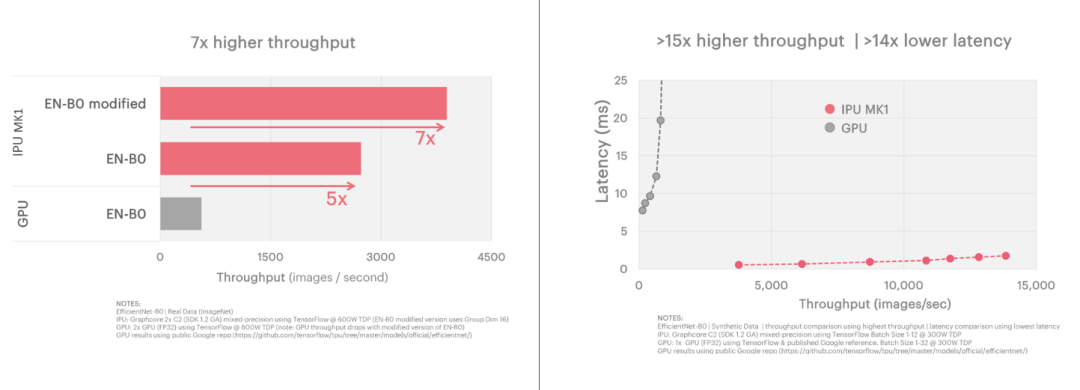
由于IPU架構的特定特性,它非常擅長于分組卷積的模型。在計算機視覺模型如efficient entnet和ResNeXt中顯著提升了訓練和推理的性能。
在EfficientNet推理(左圖)和訓練(右圖)模型測試中,IPU在比GPU延遲低14倍的情況下實現了15倍的高吞吐量的優勢,推理模型種子能夠實現7倍于目前GPU解決方案的吞吐量。
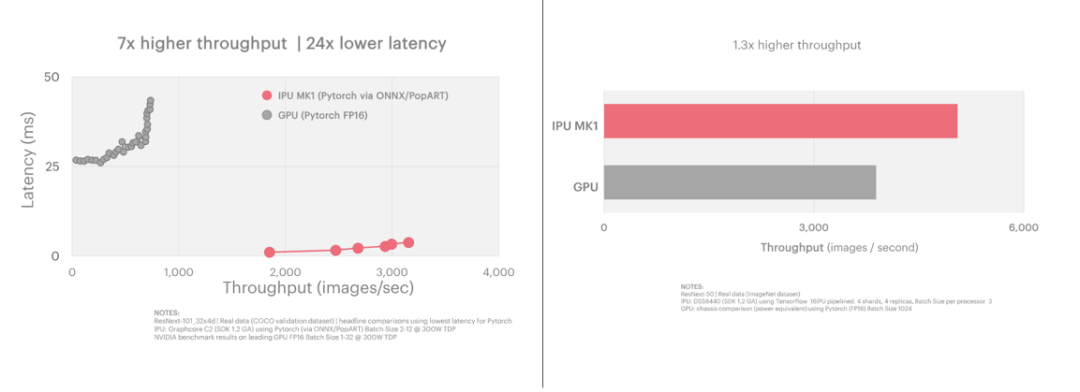
如下圖所示,ResNeXt-101: Inference(左圖) 和 ResNeXt-50 Training(右圖)與GPU相比,Graphcore C2 IPU處理器在延遲低24倍的情況下實現了7倍的高吞吐量。
好馬配好鞍——IPU全軟件棧和框架支持
Graphcore提供了Poplar SDK IPU軟件開發平臺,幫助用戶高效地構建人工智能應用,可為當今的領先模型提供開箱即用的先進性能。
Poplar SDK可與TensorFlow、Pytorch和ONNX等流行框架一起使用。它支持高階的機器智能圖描述,可編譯加載到IPU上優化的Poplar圖和相關的控制程序。大規模的處理器內存意味著可以充分利用龐大的處理器內帶寬,可將整個模型加載到IPU上。
Poplar SDK支持一系列標準框架。通過TensorFlow,Poplar SDK可直接接受XLA圖,并將XLA編譯輸出為Poplar圖和控制程序。
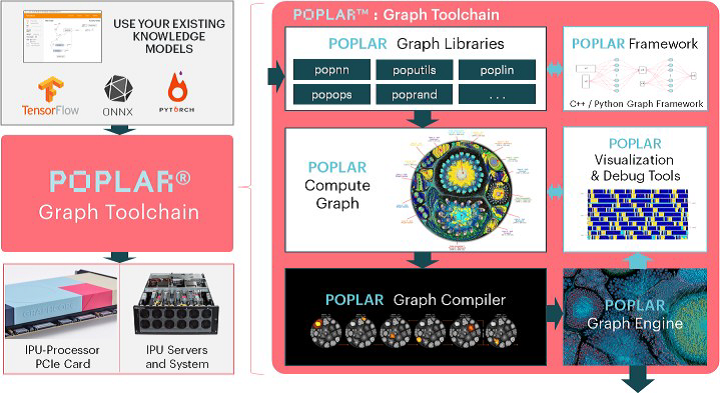
Graphcore還為ONNX提供了訓練運行時(runtime),并且正與ONNX各組織緊密合作,以將其納入ONNX標準環境中。
DSS 8440服務器:業界首款采用Graphcore技術的機器學習服務器
作為Graphcore的合作伙伴,戴爾科技希望能為用戶提供更強大的算力支持,將業內領先的創新研發成果融入機器學習硬件產品,推出了業界首款搭載Graphcore IPU的戴爾易安信DSS 8440服務器。它屬于兩處理器插槽的4U服務器,旨在為人工智能應用提供卓越的性能。
支持8個Graphcore C2卡(雙IPU),可提供高達1.6Peta FLOP的混合精度機器智能計算能力。
采用了多功能平衡加速器,可以搭載4個、8個或10個NVIDIA Tesla V100 GPUs以及更高達16塊T4 GPUs,用戶可以根據需要和最佳配置,有效地分配機器學習資源。
擁有高速輸入/輸出性能,利用IPU-Link的“階梯式”拓撲,在兩個IPU C2卡之間的總體雙向帶寬為256GB/s。此配置保障了多塊IPU卡之間高速共享模型參數或數據,為科學和工程環境中的建模、模擬和預測分析等計算密集型工作負載提供更優性能。
對于分布式訓練應用,戴爾易安信DSS 8440服務器還提供多個100Gbps網絡鏈接,以實現服務器到服務器的可擴展性。
搭載了Graphcore IPU的戴爾易安信DSS 8440服務器,是人工智能訓練和推理應用的理想之選。用戶利用DSS 8440中大量的低延遲本地存儲和強大的吞吐能力,可從海量的數據源中獲得更快的結果。

戴爾易安信豐富的機器學習專業知識,經典機器學習、深度學習的硬件和解決方案,能夠幫助AI 技術開發、研發型的初創小企業,快速部署穩定可靠且高算力的基礎架構產品,支持創新研發提高其核心競爭力。
尊敬的讀者
隨著2021新年的到來
戴爾科技開年第一“惠”盛情來襲
助企業新的一年牛氣沖天!
多款服務器、工作站、商用筆記本
等產品限時優惠
更有0元試用、現金紅包
等活動等你來參與
快來掃描下方二維碼
或點擊文末閱讀原文
了解活動詳情

相關內容推薦:戴爾科技開年第一“惠”盛情來襲|爆款服務器“骨折價”限時搶購
















