Pandas中的這3個函數,沒想到竟成了我數據處理的主力
導讀:學Pandas有一年多了,用Pandas做數據分析也快一年了,常常在總結梳理一些Pandas中好用的方法。例如三個最愛函數、計數、數據透視表、索引變換、聚合統計以及時間序列等等,每一個都稱得上是認知的升華、實踐的結晶。今天,延承這一系列,再分享三個函數,堪稱是個人日常在數據處理環節中應用頻率較高的3個函數:apply、map和applymap,其中apply是主角,map和applymap為贈送。
數據處理環節無非就是各種數據清洗,除了常規的缺失值和重復值處理邏輯相對較為簡單,更為復雜的其實當屬異常值處理以及各種數據變換:例如類型轉換、簡單數值計算等等。在這一過程中,如何既能保證數據處理效率而又不失優雅,Pandas中的這幾個函數堪稱理想的解決方案。
為展示應用這3個函數完成數據處理過程中的一些demo,這里以經典的泰坦尼克號數據集為例。需要下載該數據集和文中示例源碼的可后臺回復關鍵字apply獲取下載方式。
01 apply的方法論
在學習apply具體應用之前,有必要首先闡釋apply函數的方法論。apply英文原義是"應用"的意思,作為編程語言中的函數名,似乎在很多種語言都有體現,比如近日個人在學習Scala語言中apply被用作是伴生對象中自動創建對象的缺省實現,如此重要的角色也可見apply這個函數的重要性。那么apply應用在Pandas中,其核心功能其實可以概括為一句話:
- apply:我本身不處理數據,我們只是數據的搬運工。
說人話就是,apply自身是不帶有任何數據處理功能的,但可以用作是對其他數據處理方法的調度器,至于調度什么又為誰而調度呢?這是理解apply的兩個核心環節:
- 調度什么?調度的是apply函數接收的參數,即apply接收一個數據處理函數為主要參數,并將其應用到相應的數據上。所以調度什么取決于接收了什么樣的數據處理函數;
- 為誰調度?也就是apply接收的數據處理函數,其作用對象是誰?或者說數據處理的粒度是什么?答案是數據處理的粒度包括了點線面三個層面:即可以是單個元素(標量,scalar),也可以是一行或一列(series),還可以是一個dataframe。
當然,這些文字描述肯定還比較抽象,那么不妨直接進入正題:talk is cheap,show me the code!
02 apply基本方法
示例前面提到,理解apply核心在于明確兩個環節:調度函數和作用對象。調度函數就是apply接收的參數,既可以是Python內置的函數,也支持自定義函數,只要符合指定的作用對象(即是標量還是series亦或一個dataframe)即可。而作用對象則取決于調用apply的對象類型,具體來說:
- 一個Series對象調用apply時,數據處理函數作用于該Series的每個元素上,即作用對象是一個標量,實現從一個Series轉換到另一個Series;
- 一個DataFrame對象調用apply時,數據處理函數作用于該DataFrame的每一行或者每一列上,即作用對象是一個Series,實現從一個DataFrame轉換到一個Series上;
- 一個DataFrame對象經過groupby分組后調用apply時,數據處理函數作用于groupby后的每個子dataframe上,即作用對象還是一個DataFrame(行是每個分組對應的行;列字段少了groupby的相應列),實現從一個DataFrame轉換到一個Series上。
以泰坦尼克號數據集為例,這里分別舉幾個小例子。原始數據集如下:
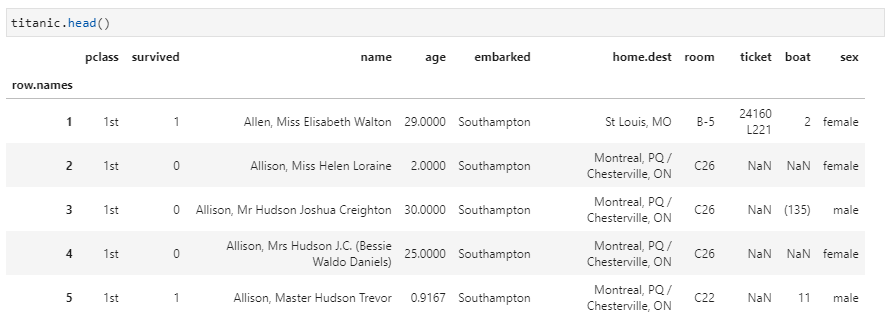
1. 應用到Series的每個元素①將性別sex列轉化為0和1數值,其中female對應0,male對應1。應用apply函數實現這一功能非常簡單:
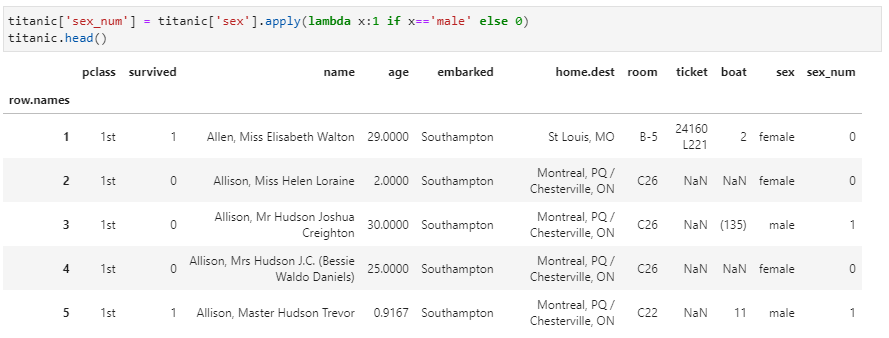
其中,這里apply接收了一個lambda匿名函數,通過一個簡單的if-else邏輯實現數據映射。該功能十分簡單,接收的函數也不帶任何其他參數。
②下面再來一個稍微復雜一點的案例,注意到年齡age列當前數據類型是小數,需要將其轉換為整數,同時還有0.9167這種過小的年齡,所以要求接受一個函數,支持接受指定的最大和最小年齡限制,當數據中超出此年齡范圍的統一用截斷填充,同時由于原數據集中age列存在缺失值,還需首先進行缺失值填充。這里首先實現一個自定義函數用于實現指定的年齡處理功能:
- def get_age(age, max_age, min_age):
- age = int(age) # 轉換為整數
- if age > max_age:
- age = max_age
- if age < min_age:
- age = min_age
- return age
然后,直接對age列調用該函數即可,其中除了第一個參數age由調用該函數的series進行向量化填充外,另兩個參數需要指定,在apply中即通過args傳入。具體而言,實現如下:
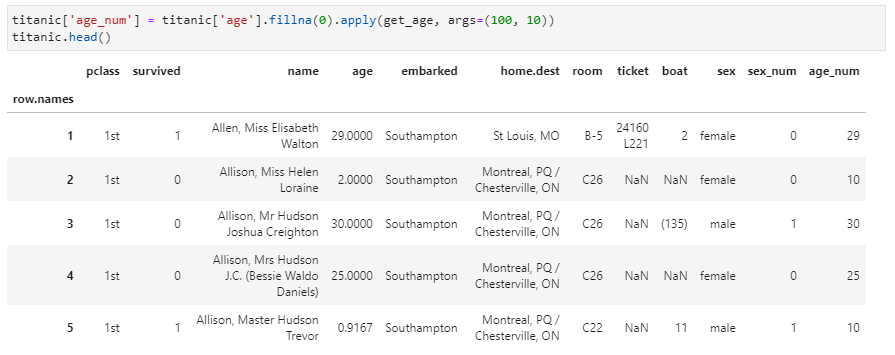
2. 應用到DataFrame的每個Series
DataFrame是pandas中的核心數據結構,其每一行和每一列都是一個Series數據類型。那么應用apply到一個DataFrame的每個Series,自然存在一個問題是應用到行還是列的問題,所以一個DataFrame調用apply函數時需要指定一個axis參數,其中axis=0對應行方向的處理,即對每列應用apply接收函數;axis=1對應列方向處理,即對每行應用接收函數。默認為axis=0。這里仍然舉兩個小例子:
①取所有數值列的數據最大值。當然,這個處理其實可以直接調用max函數,但這里為了演示apply應用,所以不妨照此嘗試:

上述apply函數完成了對四個數值列求取最大值,其中缺省axis參數為0,對應行方向處理,即對每一列數據求最大值。
②然后來一個按行方向處理的例子,例如根據性別和年齡,區分4類人群:即女孩、成年女子、男孩、成年男子,其中年齡以18歲為界值進行區分。首先給出人群劃分的函數實現:
- def cat_person(sr):
- if sr['sex_num'] == 0:
- if sr['age_num'] < 18:
- return '女孩'
- else:
- return '成年女子'
- else:
- if sr['age_num'] < 18:
- return '男孩'
- else:
- return '成年男子'
基于此,用apply簡單調用即可,其中axis=1設置apply的作用方向為按列方向,即對每行進行處理。其中每行都相當于一個帶有age和sex等信息的Series,通過cat_person函數進行提取判斷,即實現了人群的劃分:

3. 應用到DataFrame groupby后的每個分組DataFrame
實際上,個人一直覺得這是一個非常有效的用法,相較于原生的groupby,通過配套使用goupby+apply兩個函數,實現更為個性化的聚合統計功能。例如,這里我們希望統計不同艙位等級內的"生存年齡比"(僅為配合舉例而隨意定義的指標,無實際含義),定義為各艙位等級內生存人員的年齡之和與所有人員年齡之和的比值。為實現這一數據統計,則首先應以艙位等級作為分組字段進行分組,而后對每個分組內的數據進行聚合統計,示例代碼如下:
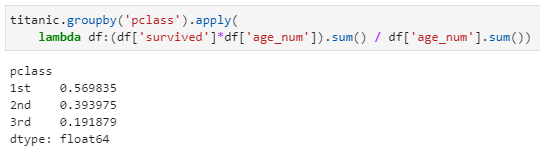
其中apply接收一個lambda匿名函數,該匿名函數接收一個dataframe為參數(該dataframe中不含pclass列),并提取survived列和age_num列參與計算。最后得到每個艙位等級的一個統計指標結果,返回類型是一個Series對象。
這里,再補充一個前期分享過的一片推文:Pandas用的6不6,來試試這道題就能看出來,實際上也是實現了相同的分組聚合統計功能。
以上,可以梳理apply函數的執行流程:首先明確調用apply的數據結構類型,是Series還是DataFrame,如果是DataFrame還需進一步確定是直接調用apply還是經過groupby分組之后調用,其中前者對應apply的接收函數處理一行或一列,后者對應接收函數處理每個分組對應的子DataFrame,最后根據作用對象類型設計相應的接收函數,從而完成個性化的數據處理。
03 apply的兩個兄弟
前面介紹了apply的三種應用場景,作用對象分別對應元素、Series以及DataFrame,可以說功能已經非常強大了。除了apply之外,pandas其實還提供了兩個功能極為相近的函數:map和applymap,不過相較于功能強大的apply來說,二者功能則相對局限。具體而言,二者分別實現功能如下:
1.map。在Python中提到map關鍵詞,個人首先聯想到的是兩個場景:①一種數據結構,即字典或者叫映射,通過鍵值對的方式組織數據,在Python中叫dict;②Python的一個內置函數叫map,實現數據按照一定規則完成映射的過程。而在Pandas框架中,這兩種含義都有所體現:對一個Series對象的每個元素實現字典映射或者函數變換,其中后者與apply應用于Series的用法完全一致,而前者則僅僅是簡單將函數參數替換為字典變量即可。仍以替換性別一列為0/1數值為例,應用map函數的實現方式為:
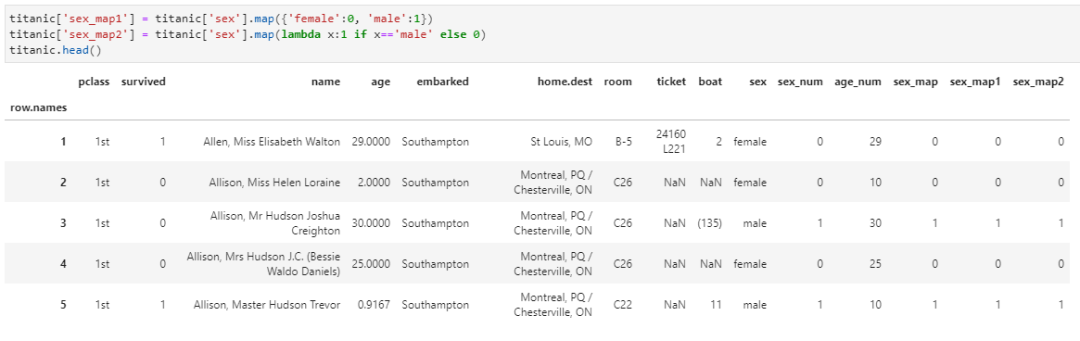
雖然map對于Series元素級的變換提供了兩種數據轉換方式,但卻僅能用于Series,而無法應用到DataFrame上。但與此同時,map相較于apply又在另一個方面具有獨特應用,即對于索引列這種特殊的Series只能應用map,而無法應用apply。
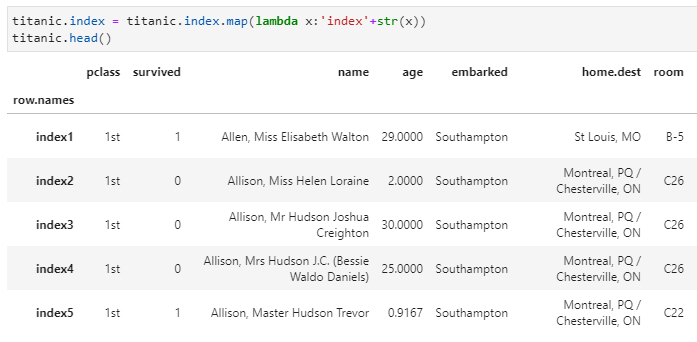
2.applymap。從名字上可以看出,這好像是個apply函數與map函數的混合體,實際上也確實有這方面的味道:即applymap綜合了apply可以應用到DataFrame和map僅能應用到元素級進行變換的雙重特性,所以applymap是將接收函數應用于DataFrame的每個元素,以實現相應的變換。
從某種角度來講,這種變換得以實施的前提是該DataFrame的各列元素具有相同的數據類型和相近的業務含義,否則運用相同的數據變換很難保證實際效果。
假設需要獲取DataFrame中各個元素的數據類型,則應用applymap實現如下:
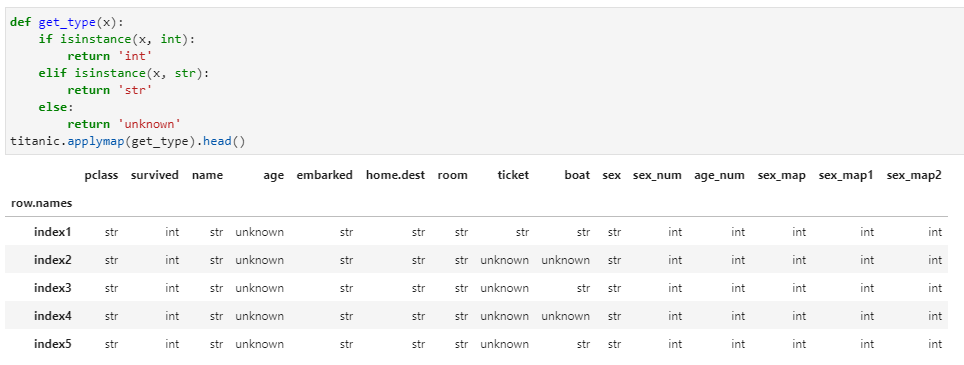
04 小結
- apply、map和applymap常用于實現Pandas中的數據變換,通過接收一個函數實現特定的變換規則;
- apply功能最為強大,可應用于Series、DataFrame以及DataFrame分組后的group DataFrame,分別實現元素級、Series級以及DataFrame級別的數據變換;
- map僅可作用于Series實現元素級的變換,既可以接收一個字典完成變化也可接收特定的函數,而且不僅可作用于普通的Series類型,也可用于索引列的變換,而索引列的變換是apply所不能應用的;
- applymap僅可用于DataFrame,接收一個函數實現對所有數據實現元素級的變換