沒想到,我們的分布式緩存竟這樣把注冊(cè)中心搞垮!
每當(dāng)有機(jī)會(huì)寫故障類主題的時(shí)候,我都會(huì)在開始前靜靜地望著顯示器很久,經(jīng)過(guò)多次煎熬和掙扎之后才敢提起筆來(lái),為什么呢?
因?yàn)檫@樣的話題很容易招來(lái)吐槽,比如 “說(shuō)了半天,不就是配置沒配好嗎?”,或者 “這代碼是豬寫的嗎?你們團(tuán)隊(duì)有懂性能測(cè)試的同學(xué)嗎?”,這樣的評(píng)論略帶挑釁,而且充滿了鄙視之意。
不過(guò)我覺得,在技術(shù)的世界里,多數(shù)情況都是客觀場(chǎng)景決定了主觀結(jié)果,而主觀結(jié)果又反映了客觀場(chǎng)景,把場(chǎng)景與結(jié)果串起來(lái),用自己的方式寫下來(lái),傳播出去,與有相同經(jīng)歷的同學(xué)聊上一聊,也未嘗不是一件好事。
上個(gè)月,我們的系統(tǒng)因注冊(cè)中心崩塌而引發(fā)的一場(chǎng)事故,本是一件稀松平常的事件,可我們猜中了開始卻沒料到原因,始作俑者竟是已在產(chǎn)線運(yùn)行多年的某分布式緩存系統(tǒng)。
回顧一下故障過(guò)程
這到底是怎么一回事呢?先來(lái)回顧一下故障過(guò)程。
11 月,某交易日的上午 10 點(diǎn)左右。在中間件監(jiān)控系統(tǒng)沒有觸發(fā)任何報(bào)警的情況下,某應(yīng)用團(tuán)隊(duì)負(fù)責(zé)人突然跑過(guò)來(lái)說(shuō):“怎么緩存響應(yīng)這么慢?你們?cè)诟墒裁词聠?”
由于此正在交易盤中,中間件運(yùn)維團(tuán)隊(duì)瞬間炸鍋,緊急查看了一系列監(jiān)控?cái)?shù)據(jù),先是通過(guò) Zabbix 查看了如 CPU、內(nèi)存、網(wǎng)絡(luò)及磁盤等基礎(chǔ)預(yù)警,一切正常,再查看服務(wù)健康狀況,經(jīng)過(guò)一圈折騰之后,也沒發(fā)現(xiàn)任何疑點(diǎn)。
懵圈了,沒道理啊。10 點(diǎn) 30 分,收到一通報(bào)警信息,內(nèi)容為 “ZK 集群中的某一個(gè)節(jié)點(diǎn)故障,端口不通,不能獲取 Node 信息,請(qǐng)迅速處理!”。
這簡(jiǎn)單,ZK 服務(wù)端口不通,重啟,立即恢復(fù)。10 點(diǎn) 40 分,ZK 集群全部癱瘓,無(wú)法獲取 Node 數(shù)據(jù)。
由于應(yīng)用系統(tǒng)的 Dubbo 服務(wù)與分布式緩存使用的是同一套 ZK 集群,而且在此期間應(yīng)用未重啟過(guò),因此應(yīng)用服務(wù)自身暫時(shí)未受到影響。
沒道理啊,無(wú)論應(yīng)用側(cè)還是緩存?zhèn)龋粋€(gè)月以來(lái)都沒有發(fā)布過(guò)版本,而且分布式緩存除了在 ZK 中存一些節(jié)點(diǎn)相關(guān)信息之外,基本對(duì) ZK 無(wú)依賴。
10 點(diǎn) 50 分,ZK 集群全部重啟,10 分鐘后,再次癱瘓。神奇了,到底哪里出了問(wèn)題呢?
10 點(diǎn) 55 分,ZK 集群全部重啟,1 分鐘后,發(fā)現(xiàn) Node Count 達(dá)到近 22W+,再次崩潰。

10 點(diǎn) 58 分,通過(guò)增加監(jiān)控腳本,查明 Node 源頭來(lái)自分布式緩存系統(tǒng)的本地緩存服務(wù)。
11 點(diǎn) 00 分,通過(guò)控制臺(tái)關(guān)閉本地緩存服務(wù)后,ZK 集群第三次重啟,通過(guò)腳本刪除本地化緩存所產(chǎn)生的大量 Node 信息。
11 點(diǎn) 05 分,產(chǎn)線 ZK 集群全部恢復(fù),無(wú)異常。一場(chǎng)風(fēng)波雖說(shuō)過(guò)去了,但每個(gè)人的臉上流露出茫然的表情。
邪了門了,這本地緩存為什么能把注冊(cè)中心搞崩塌?都上線一年多了,之前為什么不出問(wèn)題?為什么偏偏今天出事?一堆的問(wèn)號(hào),充斥著每個(gè)人的大腦。
我們本地緩存的工作機(jī)制
在這里,我就通過(guò)系統(tǒng)流程示意圖的方式,簡(jiǎn)要的說(shuō)明下我們本地緩存系統(tǒng)的一些核心工作機(jī)制。
①非本地緩存的工作機(jī)制

②本地緩存的工作機(jī)制:Key 預(yù)加載/更新

③本地緩存的工作機(jī)制:Set/Delete 操作

④本地緩存的工作機(jī)制:Get 操作

順帶提一句,由于歷史性與資源緊缺的原因,我們部分緩存系統(tǒng)與應(yīng)用系統(tǒng)的 ZK 集群是混用的,正因如此,給本次事故埋下了隱患。
ZK 集群是怎樣被搞掛的呢?
說(shuō)到這里,相信對(duì)中間件有一定了解的人基本能猜出本事件的全貌。
簡(jiǎn)單來(lái)說(shuō),就是在上線初期,由于流量小,應(yīng)用系統(tǒng)接入量小,我們本地緩存的消息通知是利用 ZK 來(lái)實(shí)現(xiàn)的,而且還用到了廣播。
但隨著流量的增加與應(yīng)用系統(tǒng)接入量的增多,消息發(fā)送量成倍增長(zhǎng),最終達(dá)到承載能力的上限,ZK 集群崩潰。的確,原因基本猜對(duì)了,但消息發(fā)送量為什么會(huì)成倍的增長(zhǎng)呢?
根據(jù)本地緩存的工作機(jī)制,我們一般會(huì)在里面存些什么呢?
- 更新頻率較低,但訪問(wèn)卻很頻繁,比如系統(tǒng)參數(shù)或業(yè)務(wù)參數(shù)。
- 單個(gè) Key/Value 較大,網(wǎng)絡(luò)消耗比較大,性能下降明顯。
- 服務(wù)端資源匱乏或不穩(wěn)定(如 I/O),但對(duì)穩(wěn)定性要求極高。
懵圈了,就放些參數(shù)類信息,而且更新頻率極低,這樣就把五個(gè)節(jié)點(diǎn)的 ZK 集群打爆了?
為了找到真相,我們立即進(jìn)行了代碼走讀,最終發(fā)現(xiàn)了蹊蹺。
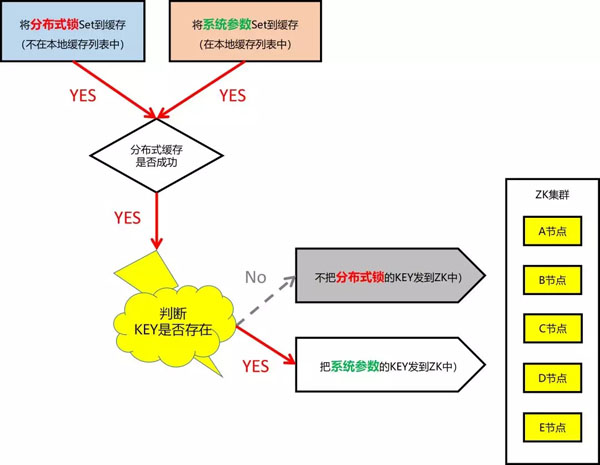
根據(jù)設(shè)計(jì),在 “本地緩存的工作機(jī)制 - Set/Delete 操作” 的工作機(jī)制中,當(dāng)一個(gè) Key 完成服務(wù)端緩存操作后,如果沒有被加到本地緩存規(guī)則列表中的 Key,是不可能被觸發(fā)消息通知的。
但這里明顯存在 Bug,導(dǎo)致把所有的 Key 都發(fā)到了 ZK 中。
這樣就很好理解了,雖然應(yīng)用系統(tǒng)近期沒有發(fā)布版本,但卻通過(guò)緩存控制臺(tái),悄悄地把分布式鎖加到了這套緩存分片中,所以交易一開盤,只需幾十分鐘,立馬打爆。
另外,除了發(fā)現(xiàn) Bug 之外,通過(guò)事后測(cè)試驗(yàn)證,我們還得出了以下幾點(diǎn)結(jié)論:
- 利用 ZK 進(jìn)行消息同步,ZK 本身的負(fù)載能力較弱,是否切換到 MQ?
- 監(jiān)控手段的單一,監(jiān)控的薄弱。
- 系統(tǒng)部署結(jié)構(gòu)不合理,基礎(chǔ)架構(gòu)的 ZK 不應(yīng)該與應(yīng)用的 ZK 混用。

說(shuō)到這里,這個(gè)故事也該結(jié)束了。
講在***
看完這個(gè)故事,一些愛好懟人的小伙伴也許會(huì)忍不住發(fā)問(wèn)。你們自己設(shè)計(jì)的架構(gòu),你們自己編寫的代碼,難道不知道其中的邏輯嗎?這么低級(jí)的錯(cuò)誤,居然還有臉拿出來(lái)說(shuō)?
那可未必,對(duì)每個(gè)技術(shù)團(tuán)隊(duì)而言,核心成員的離職與業(yè)務(wù)形態(tài)的變化,都或多或少會(huì)引發(fā)技術(shù)團(tuán)隊(duì)對(duì)現(xiàn)有系統(tǒng)形成 “知其然,而不知其所以然” 的情況,雖說(shuō)每個(gè)團(tuán)隊(duì)都在想方設(shè)法進(jìn)行避免,但想完全杜絕,絕非易事。
作為技術(shù)管理者,具備良好的心態(tài),把每次故障都看成是一次蟬變的過(guò)程,從中得到總結(jié)與經(jīng)驗(yàn),并加以傳承,今后不再犯,那就是好樣的。
不過(guò),萬(wàn)一哪天失手,給系統(tǒng)來(lái)了個(gè)徹底癱瘓,該怎么辦呢?祝大家一切順利吧。
作者:王曄倞
編輯:陶家龍、孫淑娟
出處:轉(zhuǎn)載自吃草的羅漢(ID:kidd_wyl)微信公眾號(hào)。