













事關(guān)人類生存?為什么要探尋AI系統(tǒng)的可解釋性?
本文轉(zhuǎn)載自公眾號“讀芯術(shù)”(ID:AI_Discovery)
這可能是你第一次聽說“可解釋人工智能”一詞,但你一定很快就能理解它:可解釋人工智能(XAI)是指構(gòu)建人工智能應(yīng)用程序的技術(shù)和方法,人們可以由此理解這些系統(tǒng)做出特定決策的“原因”。
換句話說,如果我們能從一個人工智能系統(tǒng)得到關(guān)于其內(nèi)部邏輯的解釋,那么這個系統(tǒng)就被認為是一個XAI系統(tǒng)。可解釋性是人工智能界開始流行的一個新屬性,我們將在下文討論其在近幾年出現(xiàn)的緣由。
首先,讓我們深入探究這一問題的技術(shù)根源。
人工智能促進我們的生活
科技的進步必然使我們能夠更方便地享受更好的服務(wù)。科技是生活中不可缺少的一部分,且肯定利大于弊,無論你喜歡科技與否,它對我們生活的影響只會與日俱增。
計算機、互聯(lián)網(wǎng)和移動設(shè)備的發(fā)明使生活更加便捷高效。繼計算機和互聯(lián)網(wǎng)之后,人工智能已經(jīng)成為生活新的增強劑。從50年代和60年代數(shù)學(xué)領(lǐng)域的努力嘗試到90年代的專家系統(tǒng),我們才取得了今天的成就。
我們可以在汽車上使用自動駕駛儀,使用谷歌翻譯與外國人交流,使用無數(shù)的應(yīng)用程序來潤色我們的照片,使用智能推薦算法找到最好的餐廳。人工智能對生活的影響不斷增強,現(xiàn)在已經(jīng)成為生活中不可或缺的、毋庸置疑的助力。
另一方面,人工智能系統(tǒng)已經(jīng)變得如此復(fù)雜,普通用戶幾乎不可能理解它如何運作。我敢說只有不足1%的谷歌翻譯用戶知道它是如何運行的,但是我們?nèi)匀恍湃芜@個系統(tǒng),并且廣泛使用。
我們應(yīng)該了解這一系統(tǒng)是如何工作的,或者至少,應(yīng)該能夠在必要的時候獲取它的相關(guān)信息。
過于注重準確性
數(shù)學(xué)家和統(tǒng)計學(xué)家們研究傳統(tǒng)的機器學(xué)習(xí)算法已有數(shù)百年歷史,如線性回歸、決策樹和貝葉斯網(wǎng)絡(luò)。這些算法都非常直觀,其發(fā)展先于計算機的發(fā)明。當你依據(jù)其中一種傳統(tǒng)算法進行決策時,很容易生成解釋。
然而,它們只在一定程度上達到了準確度。因此,傳統(tǒng)算法的可解釋度很高,但也算不上很成功。
后來,麥卡洛克-皮茨(McCulloch-Pitts)神經(jīng)元發(fā)明后,發(fā)生了翻天覆地的變化。這一發(fā)展促使了深度學(xué)習(xí)領(lǐng)域的創(chuàng)立。深度學(xué)習(xí)是人工智能的一個分支領(lǐng)域,主要研究利用人工神經(jīng)網(wǎng)絡(luò)來復(fù)制大腦中神經(jīng)元細胞的工作機制。
由于運算能力的提高以及開源深度學(xué)習(xí)框架的優(yōu)化,我們逐漸能夠構(gòu)建高精確度性能的復(fù)雜神經(jīng)網(wǎng)絡(luò)。人工智能研究人員們開始競爭,以盡可能達到最高精確度水平。而這種競爭無疑幫助我們構(gòu)建了偉大的人工智能產(chǎn)品,但同時付出的代價是:低解釋性。
神經(jīng)網(wǎng)絡(luò)非常復(fù)雜且難以理解。它們可以用數(shù)十億個參數(shù)來構(gòu)建。例如,Open AI的革命性NLP模型,GPT-3,就擁有超過1750億個機器學(xué)習(xí)參數(shù);從這樣一個復(fù)雜的模型中推導(dǎo)出任何一個推理都極具挑戰(zhàn)。
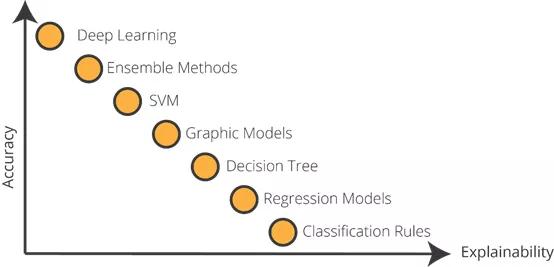
機器學(xué)習(xí)算法運行的精準度VS.可解釋性
如你所見,一個人工智能開發(fā)人員依靠傳統(tǒng)算法而非深度學(xué)習(xí)模型的損失良多。所以,我們看到越來越多的精確模型與日俱增,而其可解釋性卻越來越低。但是,我們需要可解釋性更甚于以往。
越來越多的人工智能系統(tǒng)被應(yīng)用于某些敏感領(lǐng)域
還記得以前人們在戰(zhàn)爭中使用真刀真槍嗎。是的,一切都在改變,遠超你的想象。智能AI無人機已經(jīng)可以在沒有人為干預(yù)的情況下干掉任何人。一些軍隊也已經(jīng)有能力實施這些系統(tǒng);但是,他們也對未知的結(jié)果感到擔憂。他們不想依賴那些自己都不清楚運作原理的系統(tǒng)。事實上,美國國防部高級研究計劃局已經(jīng)有一個正在進行的XAI項目。
無人駕駛汽車是另一個例子。現(xiàn)在已經(jīng)可以在特斯拉汽車上使用自動駕駛儀了。這對司機來說是極大的便利。但是,與之而來也有巨大的責任。當你的汽車遇到道德困境時,它會怎么做;在道德困境中,它必須在兩個罪惡的抉擇中選擇損失較小的一個。
例如,自動駕駛儀是否應(yīng)該犧牲一條狗來拯救一個路上的行人?你也可以在麻省理工學(xué)院的道德機器上一睹集體道德和個人道德。
日復(fù)一日,人工智能系統(tǒng)在更大程度上影響著我們的社會生活。我們需要知道它們在一般情況和特殊事件中如何做出決定。
人工智能的指數(shù)級增長可能會造成生存威脅
我們都看過《終結(jié)者》,目睹了機器如何具有自我意識,并可能毀滅人類。人工智能是強大的,它可以幫助我們成為一個多星球物種,同時也可能完全摧毀我們,就如《啟示錄》中的場景一樣。
事實上,研究表明,超過30%的人工智能專家認為,當我們實現(xiàn)通用人智能(ArtificialGeneral Intelligence)時,結(jié)果要么糟糕,要么極其糟糕。所以,防止災(zāi)難性后果的最有力武器就是了解人工智能系統(tǒng)的工作方法,這樣我們就可以使用制衡機制,就如限制政府權(quán)利過度一樣。
解決人工智能相關(guān)爭議需要推理和解釋
由于過去兩個世紀人權(quán)和自由的發(fā)展,目前的法律及條例已經(jīng)要求在敏感領(lǐng)域有一定程度的可解釋性。法律論證和推理領(lǐng)域也涉及可解釋性的界限。
人工智能的應(yīng)用程序僅是接管了一些傳統(tǒng)的職業(yè),但這并非代表它們的控制器就不負責提供解釋。它們必須遵守同樣的規(guī)則,也必須為其服務(wù)提供解釋。一般法律原則要求在發(fā)生法律糾紛時(例如,當自動駕駛的特斯拉撞上行人)對自動化決策作出解釋。
但是,一般規(guī)則和原則并不是要求強制性解釋的唯一理由。我們也有一些當代的法律法規(guī),規(guī)范了不同形式的解釋權(quán)。
歐盟的《通用數(shù)據(jù)保護條例》(GDPR)已經(jīng)定義了解釋權(quán),當公民受到自動化決策的約束時,有必要對人工智能系統(tǒng)的邏輯進行合理的解釋。
另一方面,在美國,公民有權(quán)獲得拒絕其信貸申請的解釋。事實上,這種權(quán)利迫使信用評分公司在給客戶評分時采用回歸模型(這一模型更易于解釋),以便他們能夠提供強制性的解釋。
消除人工智能系統(tǒng)的歷史偏見需要可解釋性
自古以來人類就有歧視現(xiàn)象,這也反映在收集的數(shù)據(jù)中。當一個開發(fā)人員訓(xùn)練一個人工智能模型時,他會給歷史數(shù)據(jù)灌以所有偏見和歧視性元素。而如果觀測有種族偏見,模型在進行預(yù)測時也會映射這些偏見。
巴特利特(Bartlett)的研究表明,在美國,至少有6%的少數(shù)族裔的信貸申請純粹是由于歧視性慣例而被拒絕。因此,用這些具有偏見的數(shù)據(jù)來訓(xùn)練一個信用申請系統(tǒng)將對少數(shù)民族產(chǎn)生毀滅性的影響。
對一個社會而言,我們必須了解算法是如何運行的,以及如何才能消除偏見,這樣才能保證社會自由、平等和博愛。
自動化業(yè)務(wù)的決策需要可靠性和信任度
從金融角度來說可解釋性也是有意義的。當使用一個支持人工智能的系統(tǒng)來為組織的銷售和市場營銷工作建議具體的行動時,你可能會好奇它為何會如此建議。
決策者們必須明白為什么他們需要采取特定行動,因為他們將為此行動負責。這對實體企業(yè)和金融企業(yè)都意義重大。尤其是在金融市場,一個錯誤的舉動會讓公司付出高昂的代價。
如你所見,這些觀點有力論證了為何我們需要可解釋的人工智能。這些觀點來自不同的學(xué)科和領(lǐng)域,如社會學(xué)、哲學(xué)、法學(xué)、倫理學(xué)和商科。因此,我們需要人工智能系統(tǒng)的可解釋性



























