













如何解釋AI做出的決策?一文梳理算法應用場景和可解釋性

英國的 Information Commissioner’s Office (ICO)和 The Alan-Turing Institute 聯合發布了《Explanation decisions made with AI》指南。該指南旨在為機構和組織提供實用建議,以幫助向受其影響的個人解釋由 AI 提供或協助的程序、服務和決定,同時幫助機構和組織遵循歐盟 GDPR 等與個人信息保護相關的政策要求。該指南分為三個部分,第 1 部分:可解釋 AI 的基礎知識;第 2 部分:可解釋 AI 的實踐;第 3 部分:可解釋 AI 對機構 / 組織的意義。指南最后給出了主流的 AI 算法 / 模型的適用場景,以及對這些算法 / 模型的可解釋性分析,可作為實踐任務中結合應用場景特點選擇能夠滿足領域要求的可解釋性的 AI 算法 / 模型的參考。
本文結合《Explanation decisions made with AI》指南,重點對算法的應用場景和可解釋性分析進行了梳理總結。此外,我們還解讀了一篇醫學領域可解釋性方法的最新論文—《評估藥物不良事件預測中基于注意和 SHAP 時間解釋的臨床有效性》,以了解關于可解釋性方法的最新研究進展。
1、算法的應用場景和可解釋性分析
《Explanation decisions made with AI》指南給出了主流的 AI 算法 / 模型的適用場景,以及對這些算法 / 模型的可解釋性分析,作者對主流模型的可解釋性情況進行了梳理總結。
算法類型 | 可能的應用 | 解釋 |
線性回歸 (LR) | 在金融(如信用評分)和醫療保健(根據生活方式和現有的健康狀況預測疾病風險)等高度監管的行業中具有優勢,因為它的計算和監督都比較簡單。 | 由于線性和單調性,具有較高的可解釋性。隨著特征數量的增加(即高維度),可解釋性會變差。 |
邏輯回歸 | 像線性回歸一樣,在高度管制和安全關鍵部門有優勢,特別是在基于分類問題的用例中,如對風險、信用或疾病的是/否決策。 | 良好的可解釋性,但不如LR,因為特征是通過邏輯函數轉換的,與概率結果的關系是對數,而不是相加。 |
正則化回歸(LASSO和Ridge) | 與線性回歸一樣,在要求結果可理解、可獲得和透明的高度監管和安全關鍵部門中具有優勢。 | 由于通過更好的特征選擇程序改善了模型的稀疏性,因此具有高度的可解釋性。 |
廣義線性模型(GLM) | 適用于目標變量具有需要指數族分布集的約束條件的用例(例如,如果目標變量涉及人數、時間單位或結果的概率,則結果必須具有非負值。) | 良好的可解釋性水平,跟蹤了LR的優點,同時也引入了更多的靈活性。因為其鏈接功能,確定特征的重要性可能不如用加性特征簡單的LR那么直接,一定程度上失去了透明度。 |
廣義加性模型(GAM) | 適用于預測變量和響應變量之間的關系不是線性的(即輸入-輸出關系在不同時間以不同速度變化),但需要最佳可解釋性的用例。 | 良好的可解釋性,因為即使在存在非線性關系的情況下,GAM也可以用圖形清晰地表示預測變量對響應變量的影響。 |
決策樹 | 由于產生DT結果的分步邏輯對非技術用戶來說很容易理解(取決于節點/特征的數量),這種方法可用于需要透明度的高風險和安全關鍵的決策支持情況,以及相關特征數量相當少的許多其他用例。 | 如果DT保持相當小的規模,那么可解釋的程度就很高,這樣就可以從頭到尾跟蹤邏輯。與LR相比,DT的優勢在于前者可以適應非線性和變量交互,同時保持可解釋性。 |
規則/決定清單和集 | 與DT一樣,由于產生規則列表和規則集的邏輯對非技術用戶來說很容易理解,這種方法可用于需要透明度的高風險和安全關鍵的決策支持情況,以及其他許多需要明確和完全透明地說明結果的用例。 | 規則列表和規則集是所有最佳性能和不透明的算法技術中具有最高程度的可解釋性之一。然而,它們也與DT有相同的可能性,即當規則列表變長或規則集變大時,可理解的程度就會消失。 |
基于案例的推理(CBR)/原型和批評 | CBR適用于任何基于經驗的領域。推理用于決策的任何領域。例如,在醫學上,當以前類似案例的成功經驗指向決策者建議的治療方法時,就會在CBR的基礎上推薦。CBR擴展到原型和批評的方法意味著更好地促進對復雜數據分布的理解,以及增加數據挖掘的洞察力、可操作性和可解釋性。 | CBR是可以通過設計來解釋的。它使用從可解釋的設計中提取的例子。它使用從人類知識中提取的例子,以便將輸入的特征吸收到人類可識別的表征中。它通過稀疏的特征和熟悉的原型保留了模型的可解釋性。 |
超稀疏線性整數模型(SLIM) | SLIM已被用于需要快速、簡化而又最準確的臨床決策的醫療應用中。一個被稱為風險校準SLIM(RiskSLIM)的版本已被應用于刑事司法領域,表明其稀疏線性方法對生態犯罪的預測與目前使用的一些不透明模型一樣有效。 | 由于其稀疏和易理解的特點,SLIM為以人為中心的決策支持提供了最佳的可解釋性。作為一個手動完成的評分系統,它還確保了實施它的引導員-用戶的積極參與。 |
Na?ve Bayes | 雖然這種技術由于不現實的特征獨立性假設而被認為是naive的,但眾所周知它是非常有效的。它的快速計算時間和可擴展性使其適合于高維特征空間的應用。 | Naive Bayes分類器具有高度的可解釋性,因為每個特征的類成員概率是獨立計算的。然而,假設獨立變量的條件概率在統計上是獨立的,這也是一個弱點,因為沒有考慮特征的相互作用。 |
K近鄰(KNN) | KNN是一種簡單、直觀、多功能的技術,應用廣泛,但對較小的數據集效果最好。由于它是非參數性的(對基礎數據分布不做任何假設),它對非線性數據很有效,同時不失可解釋性。常見的應用包括推薦系統、圖像識別、客戶評級和排序。 | KNN的工作假設是,通過查看它們所依賴的數據點與產生類似類別和結果的數據點的接近程度,可以預測類別或結果。這種關于近似性/接近性的重要性的直覺是對所有KNN結果的解釋。當特征空間保持小的時候,這樣的解釋更有說服力,所以實例之間的相似性仍然是可以得到的。 |
SVM | SVM對于復雜的分類任務來說是非常通用的。它們可以用來檢測圖像中物體的存在(有臉/無臉;有貓/無貓),對文本類型進行分類(體育文章/藝術文章),以及識別生物信息學中感興趣的基因。 | 可解釋性水平低,取決于維度特征空間。在上下文確定的情況下,使用SVM應輔以輔助解釋工具。 |
ANN | ANN最適合于完成高維特征空間的各種分類和預測任務,即有非常大的輸入向量的情況。它們的用途可能包括計算機視覺、圖像識別、銷售和天氣預報、藥品發現和股票預測、機器翻譯、疾病診斷和欺詐檢測。 | 由于曲線(極端非線性)的傾向和輸入變量的高維度,導致ANN非常低的可解釋性。ANN被認為是 "黑盒 "技術的縮影。在適當的情況下,應當引入解釋工具輔助ANN的使用。 |
隨機森林 | 隨機森林經常被用來有效地提高單個決策樹的性能,改善其錯誤率,并減輕過擬合。它們在基因組醫學等高維問題領域非常流行,也被廣泛用于計算語言學、計量經濟學和預測性風險建模。 | 由于在bagged數據和隨機特征上訓練這些決策樹群的方法、特定森林中的樹木數量以及單個樹木可能有數百甚至數千個節點的可能性,可能導致隨機森林方法非常低的可解釋性。 |
集合方法 | 集合方法有廣泛的應用,跟蹤其組成學習者模型的潛在用途(包括DT、KNN、隨機森林、NaiveBayes,等等)。 | 集合方法的可解釋性因使用何種方法而不同。例如,使用bagging技術的模型,即把在隨機數據子集上訓練的學習者的多個估計值平均起來,其原理可能難以解釋。對這些技術的解釋需求應該結合其組成學習者的情況分別考慮。 |
2、評估藥物不良事件預測中基于注意力機制和 SHAP 時間解釋的臨床有效性
 可解釋的機器學習是一個新興的領域,它嘗試以更人性化的方式幫助我們理解黑盒分類器模型的決策。特別是對于醫療領域,可解釋性對于提供公開透明的分析和合法的決策結果至關重要。具備可解釋性,一線醫療利益相關者就可以信任模型的決定并采取適當的行動。此外,全面的可解釋性能夠確保醫療實施的用戶可能獲取監管權利,例如根據歐盟通用數據保護條例(GDPR):"獲得解釋的權利"。
可解釋的機器學習是一個新興的領域,它嘗試以更人性化的方式幫助我們理解黑盒分類器模型的決策。特別是對于醫療領域,可解釋性對于提供公開透明的分析和合法的決策結果至關重要。具備可解釋性,一線醫療利益相關者就可以信任模型的決定并采取適當的行動。此外,全面的可解釋性能夠確保醫療實施的用戶可能獲取監管權利,例如根據歐盟通用數據保護條例(GDPR):"獲得解釋的權利"。
在醫療領域,深度學習模型應用于電子健康記錄(Electronic Health Record,EHR)數據獲得了很好的效果。例如循環神經網絡(RNN)能夠有效捕捉 EHR 中時間相關的和異質的數據復雜性。然而,RNNs 的一個主要缺點是缺乏內在的可解釋性。在過去的研究過程中,已經產生了幾種使 RNNs 更具解釋性的方法,例如,通過引入注意力機制使模型本身更易解釋,如用 RETAIN;事后可解釋性框架(如 SHAP)可以應用于概述 RNNs 的時間解釋等等。
RETAIN[2]:用于分析 EHR 數據以預測病人未來出現心力衰竭的風險。RETAIN 受注意力機制啟發,通過使用一個兩層的神經注意力模型,并對 EHR 數據進行逆序輸入系統,模擬醫生滿足病人需求及分析病人記錄時專注于病人過去診療記錄中某些特殊臨床信息、風險因素的過程,在保證預測結果準確性(Accuracy)的同時確保了結果的可解釋性(interpretability)。
SHAP[3]:來自于博弈論原理,SHAP(SHapley Additive exPlanations)為特征分配特定的預測重要性值,作為特征重要性的統一度量,能夠解釋現代機器學習中大多數的黑盒模型,為機器學習模型量化各個特征的貢獻度。給定當前的一組特征值,特征值對實際預測值與平均預測值之差的貢獻就是估計的 Shapley 值。
然而,關于醫學預測領域 RNN 的可解釋技術所提供的時間解釋的質量,還存在著研究空白。支持和反對使用注意力作為解釋方法的論點都存在,一些證據表明,使用注意力得分可以提供足夠的透明度來解釋單個特征如何影響預測結果。而還有一些證據則質疑了注意力機制的有效性,因為注意力值和更直觀的特征重要性測量之間的相關性很弱。在實踐中,用于模型解釋的可視化平臺已經成功地利用了注意力分數來為醫學預測提供解釋。然而,使用注意力值的整體效用還需要更深入的驗證,特別是與利用其他可解釋方法(如 SHAP)相比。
本文的主要目標是探索具有內在可解釋性的 RNN 通過注意力機制能夠在多大程度上提供與臨床兼容的時間解釋,并評估這種解釋應該如何通過應用事后方法來補充或取代,例如對黑盒 RNN 的 SHAP。本文具體在藥物不良事件(Adverse Drug Event,ADE)預測的醫學背景下探討這個問題。結合我們所解讀的《Explanation decisions made with AI》指南,這篇文章所討論的是典型的必須應用非線性統計技術的情況。在上一章節的梳理中,指南已經明確“由于曲線(極端非線性)的傾向和輸入變量的高維度,導致 ANN 非常低的可解釋性。ANN 被認為是 "黑盒" 技術的縮影。在適當的情況下,應當引入解釋工具輔助 ANN 的使用。”。因此,本文所做的工作就是為應用于醫學領域的 ANN 方法引入適當的輔助解釋工具(注意力機制和 SHAP 時間解釋)。當然,正如我們在之前的解讀中分析的,在一些應用場景中,簡單的白盒模型 / 方法無法滿足應用需要,為了保證較高的準確度 / 預測率,有時必須采用黑盒算法 / 模型。而如何在這種情況下通過引入輔助解釋工具幫助模型 / 系統的用戶更好的理解解釋,就是下面這篇論文會詳細介紹的了。
2.1 方法介紹
令ε={P1,...,Pn}表征 n 個病人的數據庫。Pj 表征 K 個病人就診數據記錄,Pj = {x_1, . . , x_k},其中,x_k 發生在時間點 t_k,包含一組描述該次診療的醫療變量,考慮到第 j 個病人在時間點 t-1 的病史數據 Pj={x_1, . . . , x_t-1},我們的任務是預測時間點 t 的 ADE 的發生,并準確地解釋為什么使用病人病史的整個時間結構來預測這種 ADE。為了解決這個問題,本文將 RNN 模型和可解釋性技術結合起來,對全局和局部解釋的方法進行了比較和臨床驗證的分析。
SHAP 框架確定了加法特征重要性方法的類別,以提供模型無關的解釋。SHAP 已經成為一種流行的模型可解釋性方法,因為它擁有多種理想的特性,即全局一致的解釋,這是其他事后方法所不能提供的,在這些方法中,局部定義的預測可能與全局模型的預測不一致。SHAP 建立在使用博弈論中的 Shapley 值的基礎上,在博弈論中,通過將不同的特征視為聯盟中的不同玩家來計算特定特征值對選定預測的影響。這些特征中的每一個都可以被看作是對預測的相對貢獻,這些貢獻可以通過計算可能的聯盟中的邊際貢獻的平均值而被計算為 Shapley 值。
Shapley 值(表示為φ_ij),可以理解為每個特征值 x_ij 對每個樣本 i 和特征 j 的預測偏離數據集的平均預測的程度。在本研究中,每個醫療變量的 Shapley 值是針對病史中的每個時間點計算的,以解釋每個醫療變量對預測的影響是如何高于或低于基于背景數據集的預測平均值的。
遞歸神經網絡(RNN)是前饋神經網絡模型的概括,用于處理連續的數據,擁有一個持續的內部狀態 h_t,由 j 個隱藏單元 h_j 組成,作為處理連續狀態之間的依賴關系的記憶機制,在本文案例中具體是指跨時間點的病人診療信息。
本文希望采用一個基本的 RNN architechure 與 SHAP 相結合,它應該能夠達到與 RETAIN 相當的性能水平,以幫助直接比較有效性解釋方法,而不會因為過度追求可解釋性而影響了模型本身的性能。具體的,本文基本 RNN 模型的內部狀態由門控遞歸單元(GRU)組成,通過迭代以下方程定義:
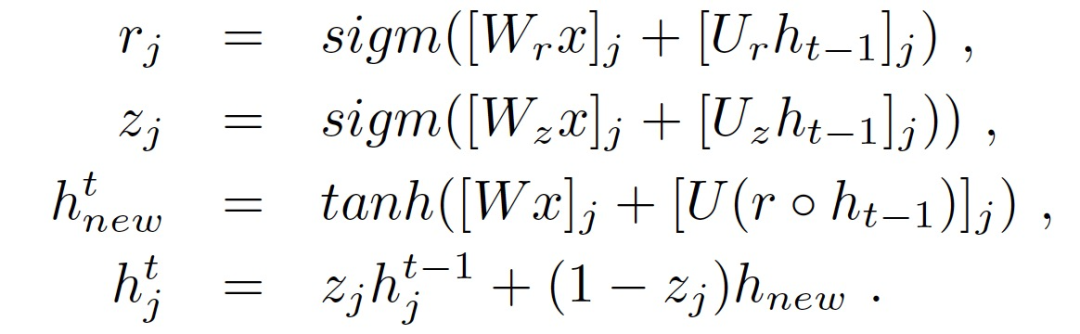
其中,r_j 為復位門,它決定了一個狀態中的每一個第 j 個隱藏單元的前一個狀態被忽略的程度;h_t-1 是上一個隱藏的內部狀態;W 和 U 是包含由網絡學習的參數權重的矩陣;z_j 是一個更新門,決定了隱藏狀態應該如何被更新為新的狀態 h_new;(h_j)^t 表示隱藏單元 h_j 的激活函數;sigm( )表示 sigmoid 函數;?是 Hadamard 積。
本文采用與 SHAP 相結合的 GRU 架構,包括兩個 128 個單元的堆疊的 GRU 隱藏層,然后是 dropout 層,最后是一個全連接層,通過一個 softmax 函數產生輸出分類概率?y。
為了收集基于注意力的時間解釋,本文采用了 RETAIN 的 RNN 架構,在預測階段,基于注意力的貢獻分數可以在單個醫學變量層面上確定。這個 RNN 首先由輸入向量 x_i 的線性嵌入組成:
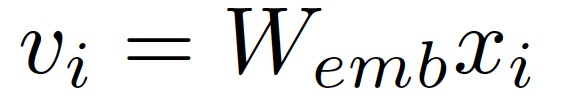
v_i∈R^m 是二進制輸入向量 x_i∈R^V 的嵌入,W_emb∈R^(m xV)是嵌入的權重向量,m 是 V 個醫療變量的嵌入維度。使用兩個 RNNs,RNNa 和 RNNb 分別用于生成訪問和可變水平的注意力向量α和β。注意力向量是通過在時間上向后運行 RNN 來生成的,這意味著 RNNα和 RNNβ都以相反的順序考慮訪問嵌入。最后,我們得到每個病人在第 i 次就診前的情況向量 c_i:
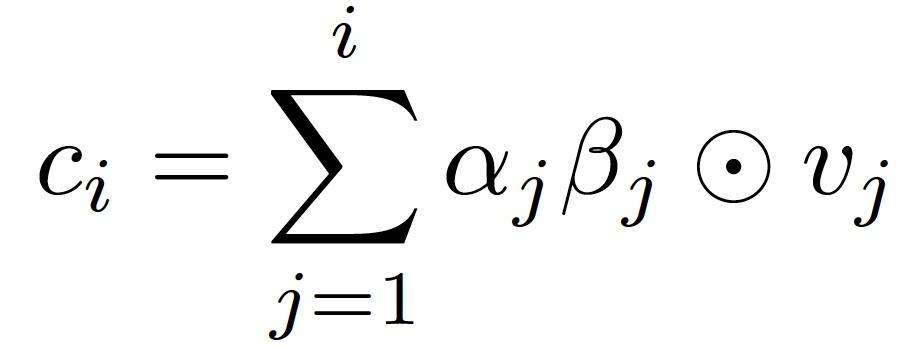
然后,最終預測結果的計算方法如下:
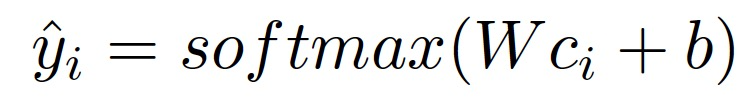

基于注意力的貢獻得分可以確定對某一預測貢獻最大的訪問和醫療變量。分數可以用下式計算:
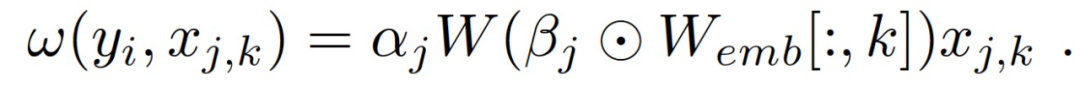

在本文研究中,根據 RNN-GRU 模型修改了 SHAP,使用的是原始 SHAP 實現的修改代碼庫。作者采用了深度學習模型的梯度解釋方法,該方法基于預期梯度,使用 1000 個隨機樣本的背景數據,為每個預測提供 Shapley 值的近似值。作者表示,這種特殊的近似處理并不保證 SHAP 的每一個屬性,但對于本文的目標來說是合適的。
2.2 驗證方法介紹
本研究使用的數據庫由 1,314,646 名患者的診斷、藥物和文本記錄組成,這些記錄來自斯德哥爾摩大學的瑞典健康記錄研究銀行(HealthBank);這是一個匿名的患者記錄數據庫,最初來自瑞典斯德哥爾摩卡羅林斯卡大學醫院的 TakeCare CGM 患者記錄系統。診斷由《國際疾病和相關健康問題統計分類》第十版(ICD-10)中的標準化代碼組成。藥物是根據解剖學治療化學分類系統(ATC)進行編碼的。為了減少問題的復雜性,并增加病人的匿名性,非 ADEICD-10 和 ATC 代碼被減少到其更高層次的等級類別,通過選擇每個代碼的前三個字符獲得。此外,就診是以月為單位定義的,這意味著在一個日歷月內分配給病人的所有代碼和藥物的組合構成了一次就診記錄。患者需要擁有至少三次這樣的記錄,相當于至少三個月的數據。與 ADE 相關的詞袋特征也被提取為二元醫學變量。本研究使用了 1813 個醫療變量,包括 1692 個 ICD-10 編碼,109 個 ATC 編碼和 12 個關鍵詞特征。
評估實驗將數據隨機劃分為訓練集、驗證集和測試集,比例分別為 0.7、0.1 和 0.2。在驗證集上呈現最佳 AUC 的訓練 epoch 所對應的模型配置部署在測試集上。為每位患者分配了一個二進制標簽,以表示在他們最后一次就診時是否有 ADE。每個病人樣本都是由包含醫療變量的就診序列組成的,刪除最后一次就診記錄。為了適應因 ADE 相對罕見而導致的類別不平衡問題,作者通過對多數類別的低度取樣創建了一個平衡的訓練集,其中利用了整個訓練集的一個隨機分區。為了說明模型行為的可變性,作者使用 3 個隨機模型和數據分區配置的平均值生成最終結果。在直接性能比較中,RNN-GRU 被配置成與 RETAIN 相同的多對一格式,并使用跨熵損失函數進行訓練。默認情況下,模型輸出大于 0.5 就會映射出一個正向 ADE 預測結果。
為了建立一個用于評估所研究的可解釋方法的臨床基本事實,本文實驗過程中總共招募了 5 位醫學專家,他們擁有醫學學位和豐富的臨床藥理學經驗。在第一階段的結構化調查中,這些專家被要求對通過 SHAP 和注意力方法確定的全局醫學變量進行打分,最終收錄了每種方法的前 20 個變量。評分包括從 - 5 到 5 的整數,0 不包括在內,其中 - 5 代表該變量與不發生 ADE 的可能性有非常高的關聯,而 5 代表變量與發生 ADE 的可能性有非常高的關聯。然后計算出臨床醫生變量得分的平均值。其次,實驗要求醫學專家對 10 個有代表性的個體病人記錄中的醫療變量進行同樣的評分,這些記錄包含了直接發生在兩個 RNN 都正確預測的 ADE 之前的醫療變量的歷史。這是一個案例研究任務,受試者對與過敏相關的 ADEs T78.4、T78.3 和 T78.2 的發生有關的變量進行評分。此外,受試者還被要求考慮變量本身的重要性、與其他變量的相互作用,以及過敏性疾病發生前的時間段。考慮時間的方法是將相同醫療變量的歷史記錄作為月度窗口輸入 RNN 模型。臨床醫生提供的平均分數被用作評估可解釋方法對同一批(10 份)病人記錄所提供的解釋的基本事實。
本文使用 Top-k Jaccard 指數比較兩種可解釋方法與臨床專家得分的相似性,該指數定義為交集大小除以原始集合中排名最高的前 k 個子集的聯合大小。排名是根據從臨床專家反應的平均值或從可解釋性方法返回的 Shapley 值或注意力貢獻分數分別計算出的降序絕對分數來定義的。最后,向醫學專家展示了如何將解釋方法可視化的示例,并要求他們思考這些解釋是否適用于現實生活中的臨床情況。
2.3 驗證結果
表 1 給出了 RETAIN 與 RNN-GRU 配置在 AUC 和 F1-Score 方面的性能比較,由表 1 中的結果可看出,用于生成解釋的模型在兩個模型中的性能相似,RETAIN 的性能略勝一籌。
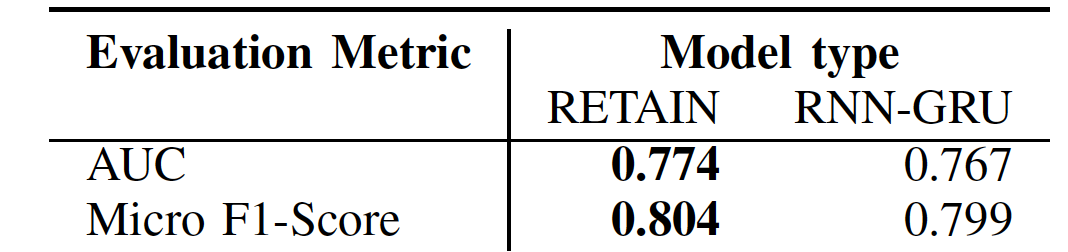
表 1. 在多對一預測配置中為所選架構指定的 ADE 預測的 ROC 曲線下的經驗測試集面積和微型 F1 分數
2.3.1 全局特征重要性
圖 1 和圖 2 是兩種方法對醫學變量的前 20 個全局重要性排名,顯示了平均絕對 SHAP 值,以及數據測試集中頂級特征的平均絕對關注值。圖 3 顯示的是所述的利益相關者參與方法產生的臨床專家平均絕對分數,用于對醫學變量進行評分。為清晰起見,作者通過計算所有病人就診中出現特定醫療變量的每個例子的貢獻系數分數的平均絕對值,來報告注意力貢獻分數的全局重要性。
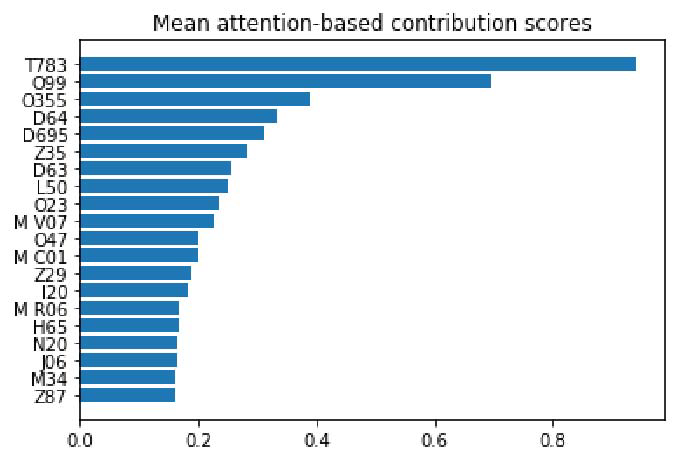
圖 1. 根據 RETAIN 模型的平均注意力貢獻得分,排名最前的醫學變量。ATC 代碼前綴為 "M"
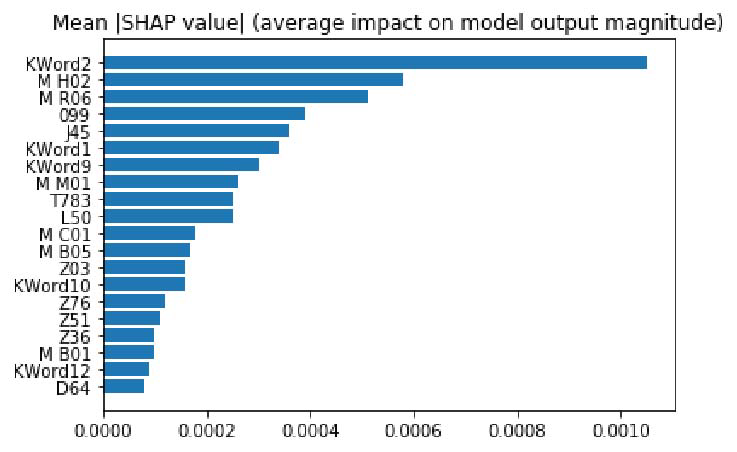
圖 2. 根據平均 SHAP 值對 RNN-GRU 模型輸出的影響,排名靠前的醫療變量。ATC 代碼前綴為 "M"。標記為 KWord * 的關鍵詞特征
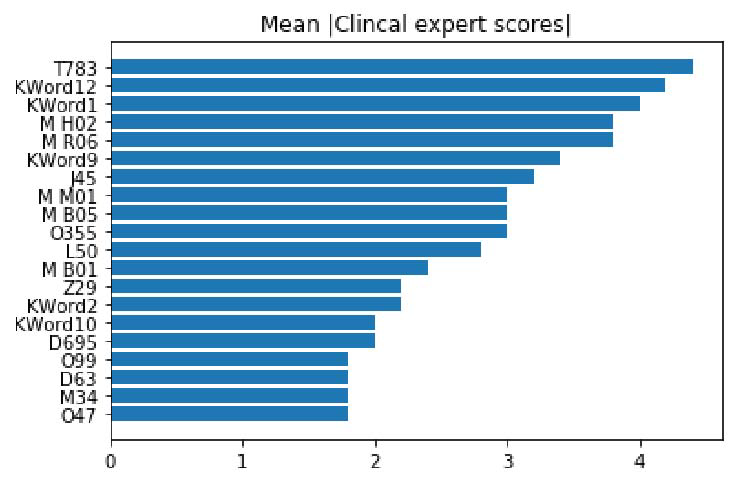
圖 3. 根據臨床專家定義的分數,排名靠前的醫療變量。ATC 代碼前綴為'M'
表 2 給出了 SHAP 和注意力排名與醫學專家排名的 top-k Jaccard 指數比較結果,由表 2 可看出與注意力排名相比,SHAP 在每個 k 值上都提供了與醫學專家更相似的總體解釋。
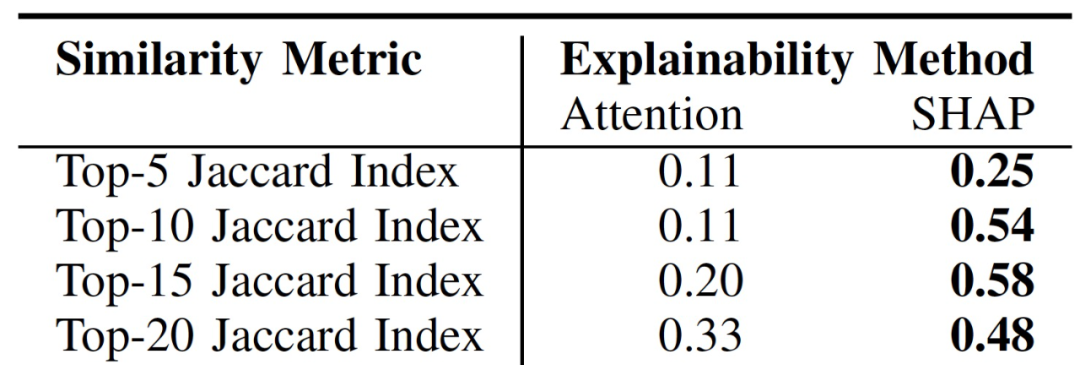
表 2. 可解釋性方法和臨床專家對最重要的醫療變量的排名之間的 Top-k Jaccard 相似性比較
2.3.2 過敏癥 ADEs 的個別解釋的案例研究
表 3 給出了過敏癥 ADEs 案例研究的結果,將 10 個有代表性的案例的平均臨床專家得分排名與注意力和 SHAP 提供的同等解釋得分排名進行比較。對于每個 Jaccard 指數,所選的前 k% 基于注意力的得分與臨床得分最相似。
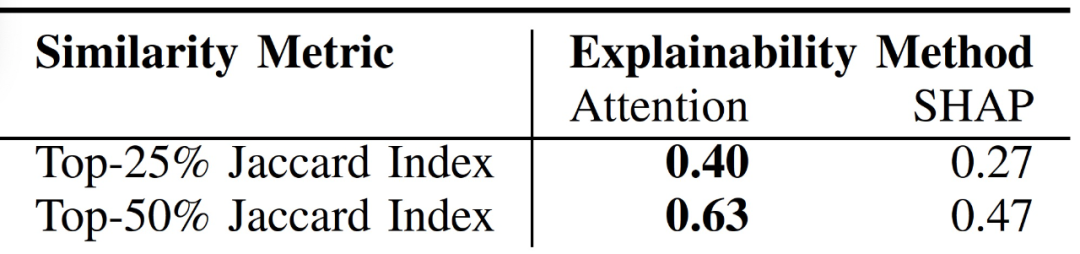
表 3. 可解釋性方法和臨床專家對單個病人記錄中最重要的醫療變量的平均 Top-k% Jaccard 相似度比較
2.3.3 對臨床遇到的問題進行可視化解釋的反饋
圖 4 展示了 SHAP 的時間解釋,表 4 給出了注意力機制的對應時間解釋。SHAP 的解釋是通過 SHAP 的特征相加的性質來提供的,以便直觀地看到醫療特征的存在或不存在是如何通過它們在每個時間點的 Shapley 值的總和來定義預測的。對于注意力的解釋,這種可視化是不可能的,因為貢獻值只反映相對重要性。
受試者得到了兩種方法的描述,并被要求回答:他們更喜歡哪種解釋,他們在理解解釋時面臨哪些挑戰,以及對改進解釋的建議。首先,5 位專家中的 4 位更喜歡 SHAP 提供的解釋,原因是它是一個更簡單的解釋,能夠比注意力解釋更有效地理解 ADE 風險的完整觀點。其次,受試者的主要顧慮是,解釋中提供的信息太多,在大多數臨床上無法使用,而且解釋一個變量的缺失是如何導致風險的也不直觀。改進的建議是,在可能的情況下顯示更少的醫療變量,以提高理解解釋的效率;其次,確保使用這種解釋的臨床醫生得到詳細的培訓。
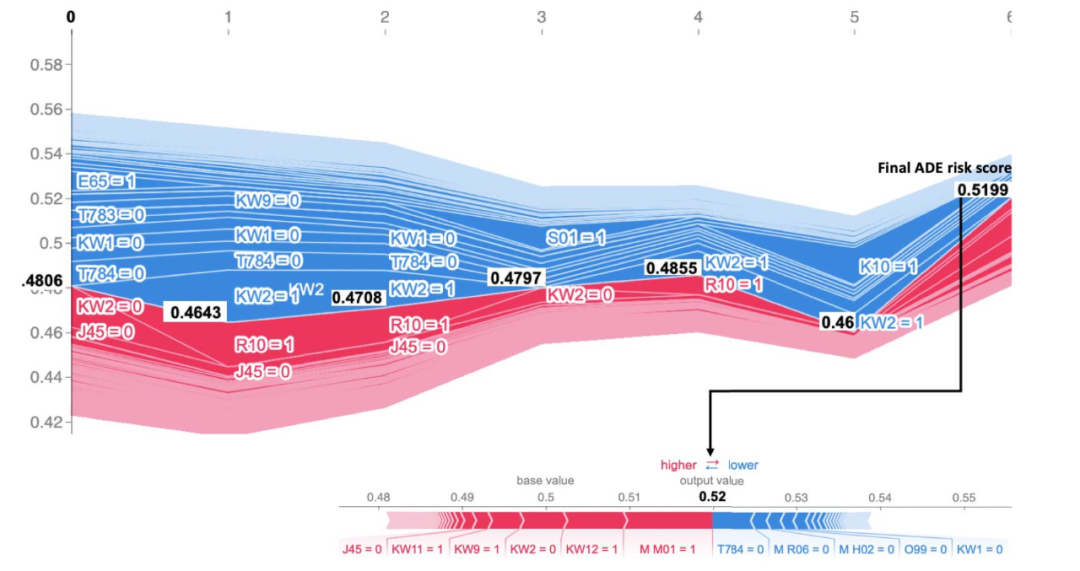
圖 4. 向臨床專家展示 SHAP 的解釋。ADE 真正陽性預測的示例,顯示用 SHAP 評估的 7 個病人就診時間的 ADE 風險的發展,最后一次就診提示有 ADE。賦值 = 0 和 = 1 分別表示沒有或存在導致風險的變數
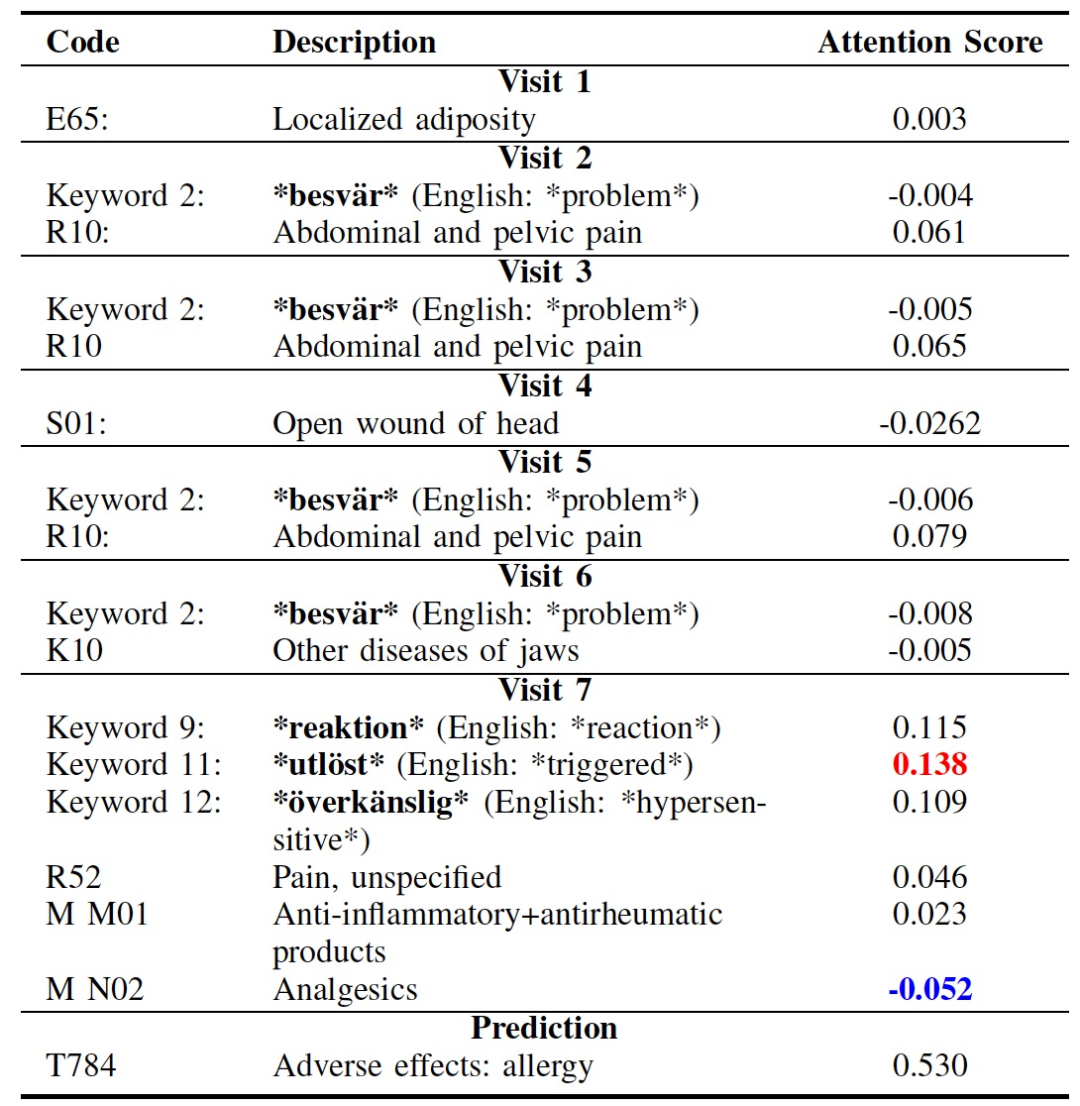
表 4. 與圖 4 相對應的真陽性 ADE 解釋的示例,使用 RETAIN 模型與藥物、診斷和文本數據。訪問得分和預測得分指的是相應的 ADE 代碼的 softmax 概率
2.4 文章討論
首先,本文實驗表明 RETAIN 和 RNN-GRU 模型的預測性能結果相似。這一發現對于臨床有效性評估很重要,因為我們不希望誘發一種偏見,即某一方法產生的解釋在臨床上的有效性較差,這是由于模型的性能較差,而不是解釋方法本身的原因。此外,考察圖 1 和圖 2 中的全局特征解釋,根據與圖 3 中的臨床專家排名的比較,這兩個排名都是獨特的,在醫學上基本符合 ADE。
SHAP 為每個 top-k Jaccard 指數提供了更多的臨床驗證的全局解釋,這在很大程度上受到了它對沒有出現在注意力排名中的文本特征的高排名的影響。就單個解釋而言,注意力為每個 top-k Jaccard 指數提供了最具有臨床有效性的解釋,這表明,由于注意力具有捕捉和利用相關領域知識的明顯能力,不應該將其作為一種可解釋的方法加以否定。
最后,從圖 4 和表 4 中醫學專家對解釋的反饋中得到的重要啟示是,由于 SHAP 在可視化特征對預測的貢獻方面具有加法特性,因此它能提供更緊湊和高效的解釋。這種緊湊性對于效率優先的實時臨床會診是至關重要的。另一方面,注意力機制不能提供同樣的緊湊性或加法性,因此對于詳細的離線解釋或不受時間限制的臨床會診可能更可取。
3、總結
由 ICO 和 The Alan-Turing Institute 共同發起的 "解釋用人工智能做出的決定(Explanation decisions made with AI)"(2020 年)是對使用人工智能系統的組織中的問責制和透明度要求的實際轉化的一次廣泛探索。
在過去的十幾年中,AI 算法 / 模型獲得了巨大的發展,從 “白盒” 不斷改進為“黑盒”,不管是產業界還是學術界,都可以看到大量追求 AI 決策性能提升的工作,將識別率提升 1%、將預測準確度提升 0.5%、在復雜背景環境下提升輸出準確度、提高推薦排序的準確性等等。隨著數字經濟的發展,國內外都越來越重視算法 / 模型的公平性、透明性、可解釋性和問責制。為了讓技術更好的服務于人類,而不是讓人類越來越被算法所奴役,解釋用 AI 做出的決策相信是未來大家都會越來越關注的問題,我們也期待更多更有效、更可行的可解釋性方法、工具的出現。


























