關于 A*、Dijkstra、BFS 尋路算法的可視化解釋
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
廣度優先搜索、Dijkstra和A*是圖上的三種典型路徑規劃算法。它們都可用于圖搜索,不同之處在于隊列和啟發式函數兩個參數。
本項目探索并可視化不同算法如何根據選擇參數進行圖搜索。
算法的一般性原理如下:
將邊界初始化為包含起始節點的隊列。
當邊界隊列不為空時,從隊列中“訪問”并刪除一個“當前”節點,同時將訪問節點的每個鄰居節點添加到隊列,其成本是到達當前節點的成本加上從當前節點訪問鄰居的成本再加上鄰居節點和目標節點的啟發式函數值。其中,啟發式函數是對兩個節點的路徑成本的估計。
存儲訪問路徑(通常存儲在cameFrom圖中),以便后續重建路徑。如果鄰居節點已經在列表中,同時新路徑的成本較低,那么更改其成本。
找到目標路徑(提前退出)或列表為空時,停止算法。
BFS
使用先進先出隊列實現BFS。這種隊列會忽略路徑中鏈接的開銷,并根據跳數進行擴展,因此可以確保找到最短路徑的跳數,而跳數相關的成本。啟發式函數的選擇是任意的,因為在這個過程中其并不起作用。
使用數組可實現先進先出,即將元素附加到末尾并從頭刪除。
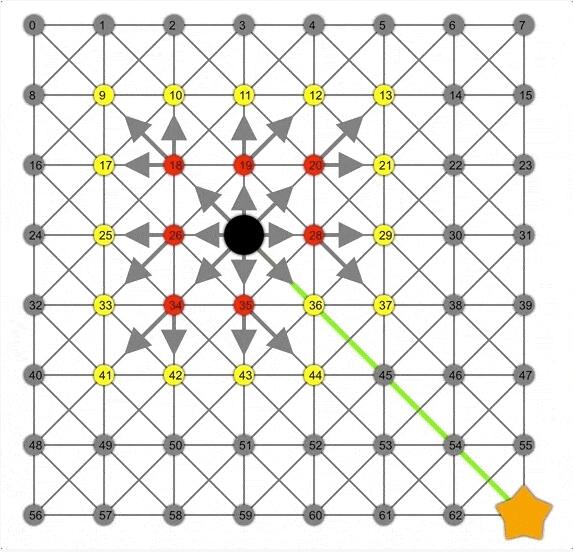
BFS演示動圖。注意邊界節點(黃色)是如何在網格中擴展為正方形的。在這里,正方形是相同“跳距”的節點集。
Dijkstra
在圖上使用優先級隊列和始終返回0的啟發式函數,便得到Dijkstra算法。
相比于BFS,Dijkstra最大的不同在于考慮了成本。通過該算法,可以根據節點到節點的成本找到最短路徑。
優先級隊列使用數組實現,在每次插入新節點后對該數組進行排序。盡管實現優先級隊列還有其他更高效的方式,但在我們的場景中,數組是足夠快的,而且實現起來也簡單。
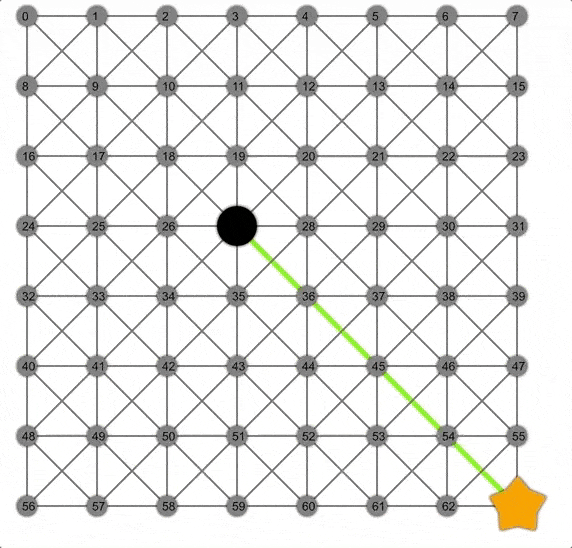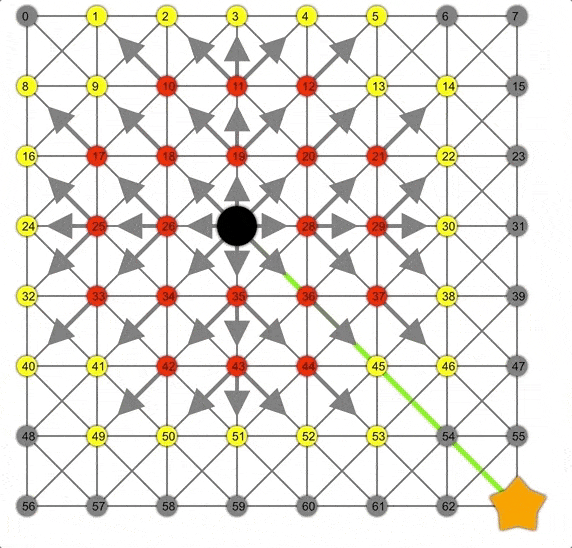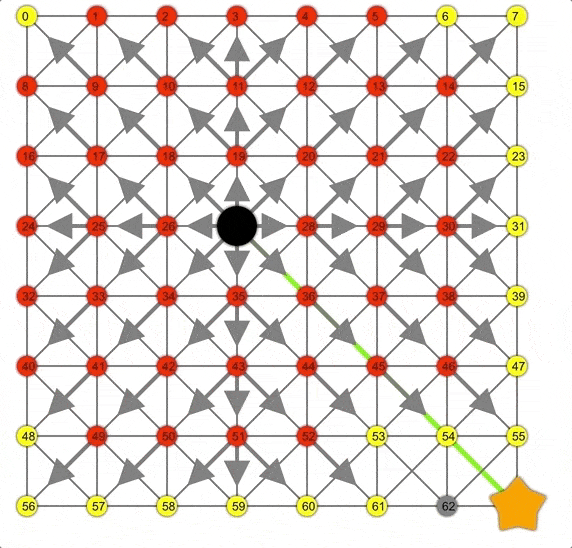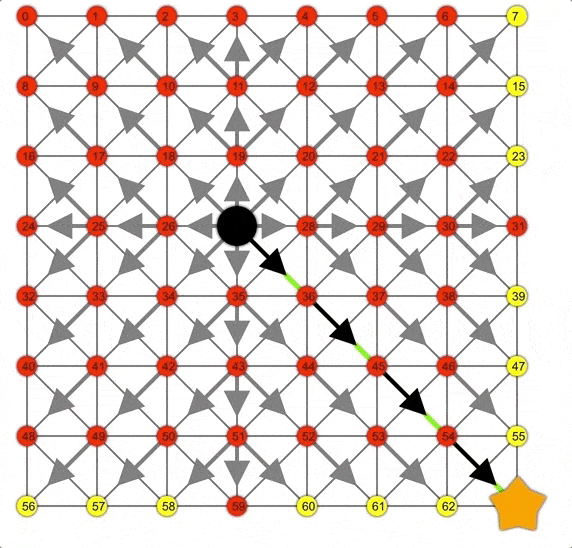
Dijkstra展示動畫,注意此時的邊界是一個圓。
A*
為實現A*算法,需要傳遞一個實際啟發式函數,例如兩個節點之間的歐式距離。通過“節點成本”+“節點到目標節點的估算成本”對節點進行加權,通過優先搜索更大可能的節點加快搜索速度。
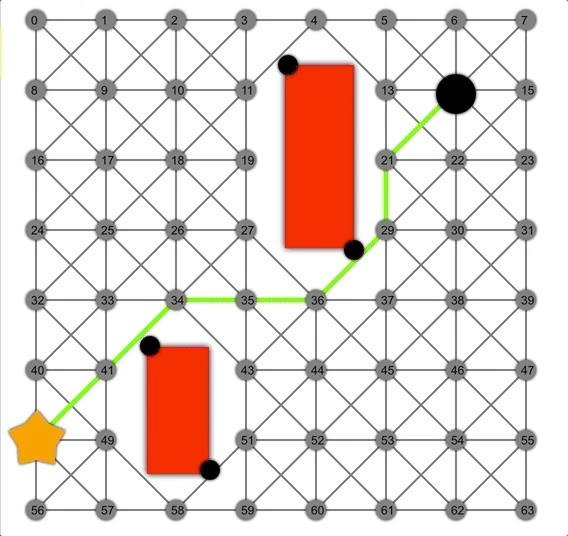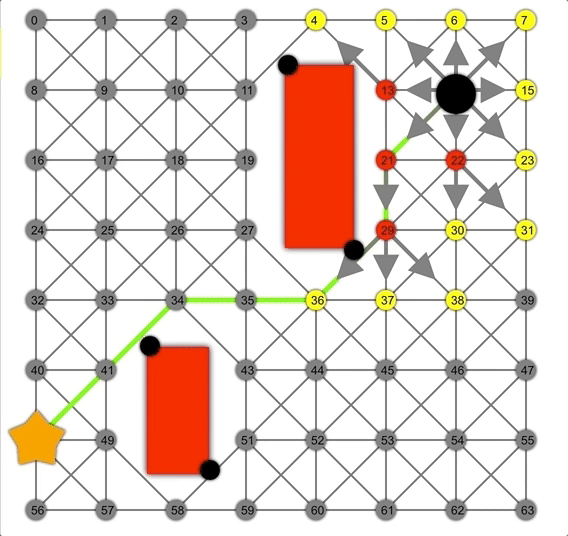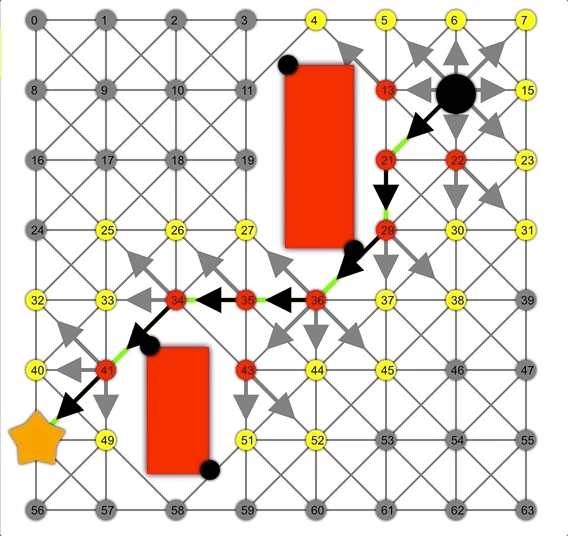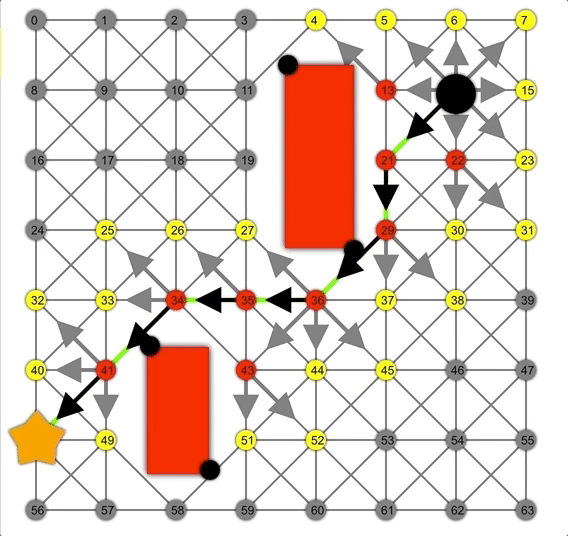
借助啟發式方法,A*可以比Dijkstra或BFS更快地找到正確路徑。
非允許的啟發式函數
只有應用可允許啟發式函數,A*才能找到最短路徑,這也意味著算法永遠不會高估實際路徑長度。由于歐氏距離是兩點之間的最短距離/路徑,因此歐氏距離絕不會超出。
但如果將其乘以常數k>0會怎樣呢?這樣會高估距離,成為非允許的啟發式函數。
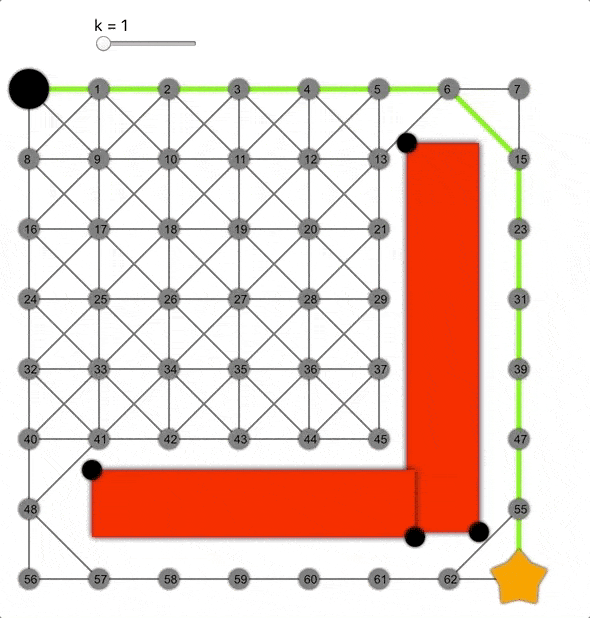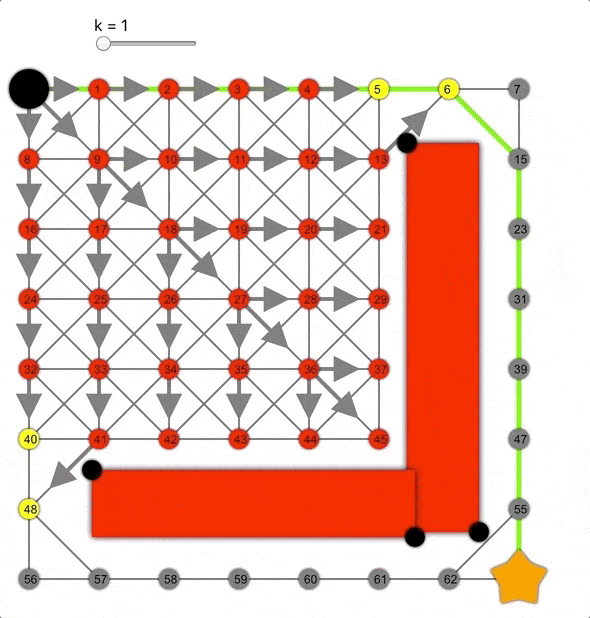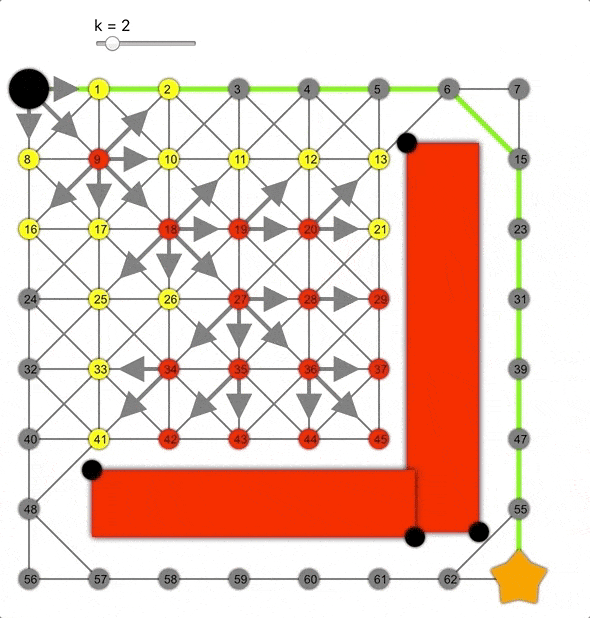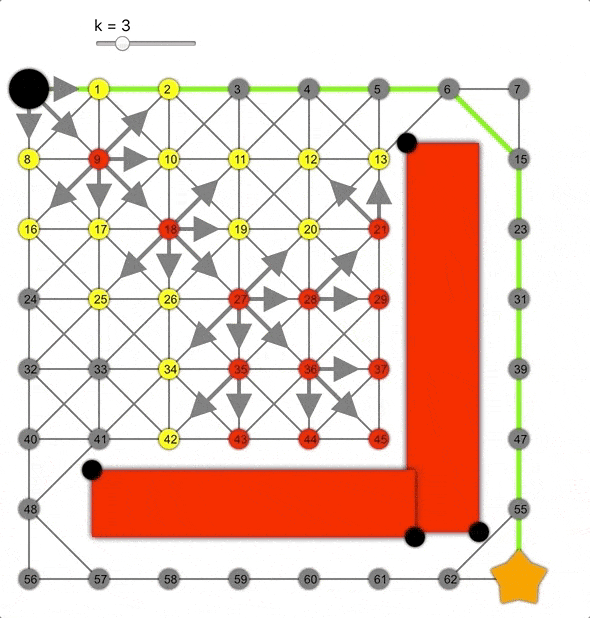
k值越大,算法越容易到達目標,但同時準確性降低,導致生成的路徑并非總是最短的。
算法實現
本項目通過Javascript實現,以便讀者在Web上進行訪問。另外,我使用react渲染UI,使用react-konva渲染圖形。
路徑發現是指接受隊列類型和啟發式函數,并返回另一個函數,即真實路徑發現(稱為currying)。
這樣,用戶每次更改設置后,都會使用確定參數創建一個新的路徑發現函數,并將之用于圖搜索。
為可視化路徑發現的步驟,我使用javascript生成器,這意味著函數返回一個迭代器,而不僅僅是一個值。因此,訪客在每一步都可以生成算法的整個狀態,并將其保存到數組,然后通過頁面頂部的滑塊顯示特定狀態。
此鏈接進入交互演示頁面:https://interactive-pathfinding.netlify.com/