終于有人將數據中臺講清楚了,原來根本不算啥
一、數據中臺功能架構
數據中臺建設是一個宏大的工程,涉及整體規劃、組織搭建、中臺落地與運營等方方面面的工作,本節重點從物理形態上講述企業的數據中臺應該如何搭建。一般來講,企業的數據中臺在物理形態上分為三個大層:工具平臺層、數據資產層和數據應用層。
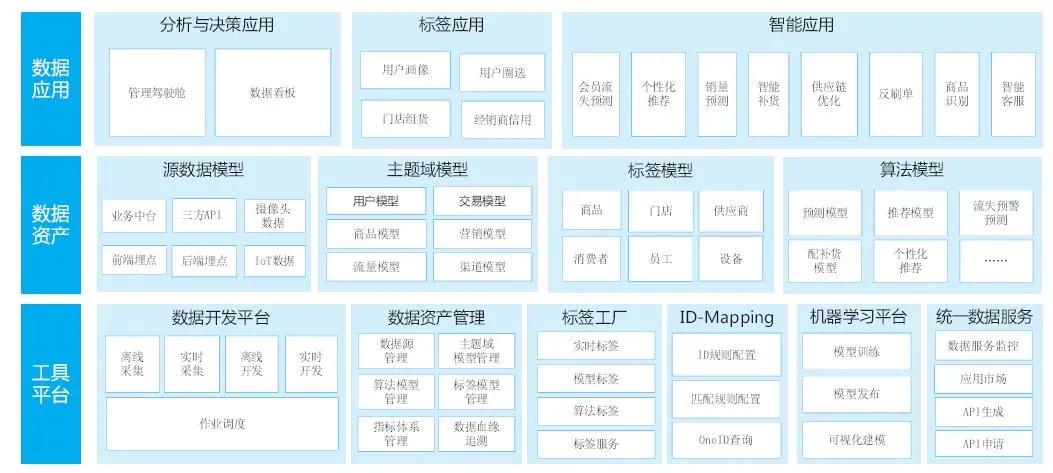
1. 工具平臺層
工具平臺層是數據中臺的載體,包含大數據處理的基礎能力技術,如集數據采集、數據存儲、數據計算、數據安全等于一體的大數據平臺;還包含建設數據中臺的一系列工具,如離線或實時數據研發工具、數據聯通工具、標簽計算工具、算法平臺工具、數據服務工具及自助分析工具。
以上工具集基本覆蓋了數據中臺的數據加工過程。
(1) 數據開發平臺
大數據的4V特征決定了數據處理是一個復雜的工程。建設數據中臺需要搭建建設數據中臺的基建工具,要滿足各種結構化、非結構化數據的采集、存儲與處理,要根據場景處理離線和實時數據的計算與存儲,要將一個個數據處理任務串聯起來以保障數據的運轉能賦能到業務端。
(2) 數據資產管理
數據中臺建設的成功與否,與數據資產是否管理有序有直接關系。前文提到,數據中臺是需要持續運營的。隨著時間的推移,數據不斷涌入數據中臺,如果沒有一套井然有序的數據資產平臺來進行管理,后果將不堪設想。
(3) 標簽工廠
標簽工廠又稱標簽平臺,是數據中臺體系內的明星工具類產品。標簽建設是數據中臺走向數據業務化的關鍵步驟。因此,一個強大的標簽工廠是數據中臺價值體現的有力保障。
標簽工廠按功能一般分為兩部分:底層的標簽計算引擎與上層的標簽配置與管理門戶。標簽計算引擎一般會采用MapReduce、Spark、Flink等大數據計算框架,而計算后的標簽存儲可采用Elasticsearch或者HBase,這樣存儲的好處是便于快速檢索。
(4) ID-Mapping
ID-Mapping又稱ID打通工具,是數據中臺建設的可選項。可選不代表不重要,在一些多渠道、多觸點的新零售企業,離開了這個工具,數據質量將大打折扣。
(5) 機器學習平臺
在整個機器學習的工作流中,模型訓練的代碼開發只是其中一部分。除此之外,數據準備、數據清洗、數據標注、特征提取、超參數的選擇與優化、訓練任務的監控、模型的發布與集成、日志的回收等,都是流程中不可或缺的部分。
2. 數據資產層
數據資產層是數據中臺的核心層,它依托于工具平臺層,那么這一層又有什么內容呢?答案是因企業的業務與行業而異,但總體來講,可以劃分為主題域模型區、標簽模型區和算法模型區。
(1) 主題域模型
主題域模型是指面向業務分析,將業務過程或維度進行抽象的集合。業務過程可以概括為一個個不可拆分的行為事件,如訂單、合同、營銷等。
為了保障整個體系的生命力,主題域即數據域需要抽象提煉,并且長期維護和更新,但是不輕易變動。在劃分數據域時,既要涵蓋當前所有業務的需求,又要保證新業務能夠無影響地被包含進已有的數據域中或者很容易擴展新的數據域。
(2) 標簽模型
標簽模型的設計與主題域模型方法大同小異,同樣需要結合業務過程進行設計,需要充分理解業務過程。標簽一般會涉及企業經營過程中的實體對象,如會員、商品、門店、經銷商等。這些主體一般來說都穿插在各個業務流程中,比如會員一般都穿插在關注、注冊、瀏覽、下單、評價、服務等環節。
(3) 算法模型
算法模型更加貼近業務場景。在設計算法模型的時候要反復推演算法模型使用的場景,包括模型的冷啟動等問題。整個模型搭建過程包含定場景、數據源準備、特征工程、模型設計、模型訓練、正式上線、參數調整7個環節。
3. 數據應用層
數據應用層嚴格來說不屬于數據中臺的范疇,但數據中臺的使命就是為業務賦能,幾乎所有企業在建設數據中臺的同時都已規劃好數據應用。數據應用可按數據使用場景來劃分為以下多個使用領域。
(1) 分析與決策應用
分析與決策應用主要面向企業的領導、運營人員等角色,基于企業的業務背景和數據分析訴求,針對客戶拉新、老客運營、銷售能力評估等分析場景,通過主題域模型、標簽模型和算法模型,為企業提供可視化分析專題。
用戶在分析與決策應用中快速獲取企業現狀和問題,同時可對數據進行鉆取、聯動分析等,深度分析企業問題及其原因,從而輔助企業進行管理和決策,實現精準管理和智能決策。
(2) 標簽應用
標簽旨在挖掘實體對象(如客戶、商品等)的特征,將數據轉化成真正對業務有價值的產物并對外提供標簽數據服務,多應用于客戶圈選、精準營銷和個性化推薦等場景,從而實現資產變現,不斷擴大資產價值。
標簽體系的設計立足于標簽使用場景,不同使用場景對標簽需求是不同的,譬如在客戶個性化推薦場景下,需要客戶性別、近期關注商品類型、消費能力和消費習慣等標簽。
(3) 智能應用
智能應用是數智化的一個典型外在表現。比如在營銷領域,不僅可實現千人千面的用戶個性化推薦,如猜你喜歡、加購推薦等,還可借助智能營銷工具進行高精準度的用戶觸達,推動首購轉化、二購促進、流失挽留等。
二、數據中臺技術架構
隨著大數據與人工智能技術的不斷迭代以及商業大數據工具產品的推出,數據中臺的架構設計大可不必從零開始,可以采購一站式的研發平臺產品,或者基于一些開源產品進行組裝。企業可根據自身情況進行權衡考慮,但無論采用哪種方案,數據中臺的架構設計以滿足當前數據處理的全場景為基準。
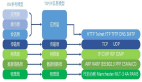
以開源技術為例,數據中臺的技術架構如圖所示,總體來看一般包含以下幾種功能:數據采集、數據計算、數據存儲和數據服務;在研發、運維和公共服務方面包括離線開發、實時開發、數據資產、任務調度、數據安全、集群管理。
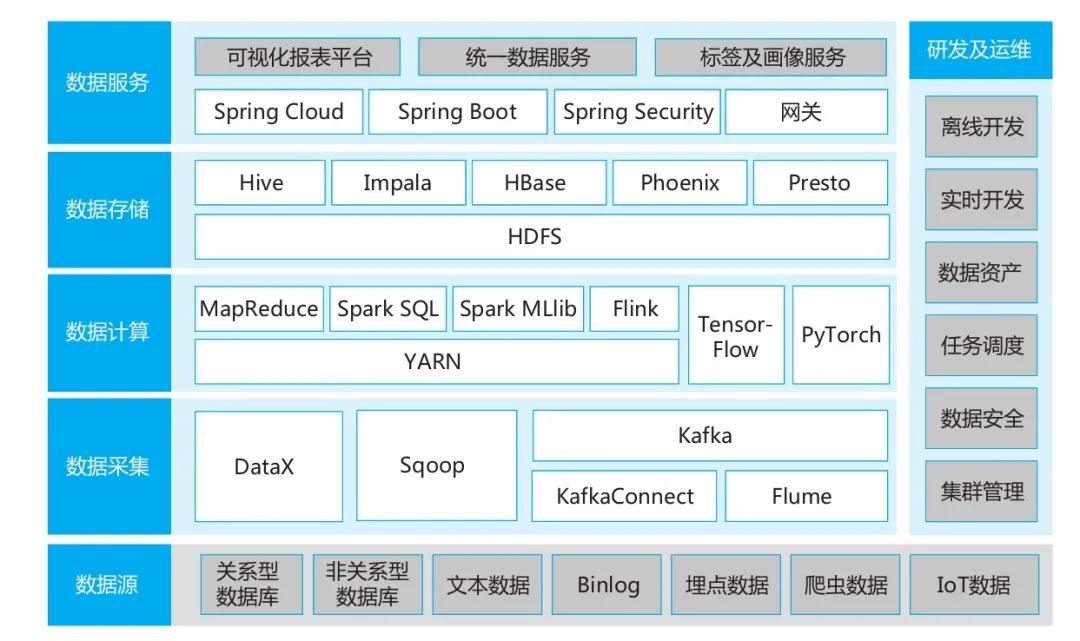
1. 數據采集層
按數據的實時性,數據采集分為離線采集和實時采集。離線采集使用DataX和Sqoop,實時采集使用Kafka Connect、Flume、Kafka。
在離線數據采集中,建議使用DataX和Sqoop相結合。DataX適合用在數據量較小且采用非關系型數據庫的場景,部署方式很簡單。Sqoop適合用在數據量較大且采用關系型數據庫的場景。
2. 數據計算層
數據計算采用YARN作為各種計算框架部署的執行調度平臺,計算框架有MapReduce、Spark及Spark SQL、Flink、Spark MLlib等。
3. 數據存儲層
數據存儲層所有的存儲引擎都基于Hadoop的HDFS分布式存儲,從而達到數據多份冗余和充分利用物理層多磁盤的I/O性能。在HDFS上分別搭建Hive、HBase作為存儲數據庫,在這兩個數據庫的基礎上再搭建Impala、Phoenix、Presto引擎。
4. 數據服務層
數據服務層采用的技術與業務應用類似,主要基于開源Spring Cloud、Spring Boot等構建,使用統一的服務網關。