













數據中臺怎么選型?終于有人講明白了

01數據倉庫選型
數據倉庫選型是整個數據中臺項目的重中之重,是一切開發和應用的基礎。而數據倉庫的選型,其實就是Hive數倉和非Hive數倉的較量。Hive數倉以Hive為核心,搭建數據ETL流程,配合Kylin、Presto、HAWQ、Spark、ClickHouse等查詢引擎完成數據的最終展現。而非Hive數倉則以Greenplum、Doris、GaussDB、HANA(基于SAP BW構建的數據倉庫一般以HANA作為底層數據庫)等支持分布式擴展的OLAP數據庫為主,支持數據ETL加工和OLAP查詢。
自從Facebook開源Hive以來,Hive逐漸占領了市場。Hive背靠Hadoop體系,基于HDFS的數據存儲,安全穩定、讀取高效,同時借助Yarn資源管理器和Spark計算引擎,可以很方便地擴展集群規模,實現穩定地批處理。Hive數據倉庫的優勢在于可擴展性強,有大規模集群的應用案例,受到廣大架構師的推崇。
雖然Hive應用廣泛,但是其缺點也是不容忽視的。
Hive的開源生態已經完全分化,各大互聯網公司和云廠商都是基于早期的開源版本進行個性化修改以后投入生產使用的,很難再回到開源體系。Hive現在的3個版本方向1.2.x、2.1.x、3.1.x都有非常廣泛的應用,無法形成合力。
開源社區發布的Hive版本過于粗糙,漏洞太多。最典型的就是Hive 3.1.0版本里面的Timestamp類型自動存儲為格林尼治時間的問題,無論怎么調整參數和系統變量都不能解決。據HDP官方說明,需要升級到3.1.2版才能解決。根據筆者實際應用的情況,Hive 3.1.2版在大表關聯時又偶爾出現inert overwrite數據丟失的情況。
Hive最影響查詢性能的計算引擎也不能讓人省心。Hive支持的查詢引擎主要有MR、Spark、Tez。MR是一如既往的性能慢,升級到3.0版也沒有任何提升。基于內存的Spark引擎性能有了大幅提升,3.x版本的穩定性雖然也有所加強,但是對JDBC的支持還是比較弱。基于MR優化的Tez引擎雖然是集成最好的,但是需要根據Hadoop和Hive版本自行編譯,部署和升級都十分復雜。
Hive對更新和刪除操作的支持并不友好,導致在數據湖時代和實時數倉時代被迅速拋棄。
Hive的查詢引擎也很難讓用戶滿意,最典型的就是以下查詢引擎。
1)Spark支持SQL查詢,需要啟動Thrift Server,表現不穩定,查詢速度一般為幾秒到幾分鐘。
2)Impala是CDH公司推出的產品,一般用在CDH平臺中,查詢速度比Spark快,由于是C++開發的,因此非CDH平臺安裝Impala比較困難。
3)Presto和Hive一樣,也是Facebook開源的,語法不兼容Hive,查詢速度一般為幾秒到幾分鐘。
4)Kylin是國人開源的MOLAP軟件,基于Spark引擎對Hive數據做預算并保存在Hbase或其他存儲中,查詢速度非常快并且穩定,一般在10s以下。但是模型構建復雜,使用和運維都不太方便。
5)ClickHouse是目前最火的OLAP查詢軟件,特點是查詢速度快,集成了各大數據庫的精華引擎,獨立于Hadoop平臺,需要把Hive數據同步遷移過去,提供有限的SQL支持,幾乎不支持關聯操作。
以Hadoop為核心的Hive數據倉庫的頹勢已經是無法扭轉的了,MapReduce早已被市場拋棄,HDFS在各大云平臺也已經逐步被對象存儲替代,Yarn被Kubernetes替代也是早晚的事。
我們把視野擴展到Hive體系以外,就會發現MPP架構的分布式數據庫正在蓬勃發展,大有取代Hive數倉的趨勢。
其中技術最成熟、生態最完善的當屬Greenplum體系。Greenplum自2015年開源以來,經歷了4.x、5.x、6.x三個大版本的升級,功能已經非常全面和穩定了,也受到市場的廣泛推崇。基于Greenplum提供商業版本的,除了研發Greenplum的母公司Pivotal,還有中國本地團隊的創業公司四維縱橫。此外,還有阿里云提供的云數據庫AnalyticDB for PostgreSQL、百度云FusionDB和京東云提供的JDW,都是基于Greenplum進行云化的產品。華為的GaussDB在設計中也參考了Greenplum數據庫。
OLAP查詢性能最強悍的當屬SAP商業數據庫HANA,這是數據庫領域當之無愧的王者。HANA是一個軟硬件結合體,提供高性能的數據查詢功能,用戶可以直接對大量實時業務數據進行查詢和分析。
HANA唯一的缺點就是太貴,軟件和硬件成本高昂。HANA是一個基于列式存儲的內存數據庫,主要具有以下優勢。
- 把數據保存在內存中,通過對比我們發現,內存的訪問速度比磁盤快1000000倍,比SSD和閃存快1000倍。傳統磁盤讀取時間是5ms,內存讀取時間是5ns。
- 服務器采用多核架構(每個刀片8×8核心CPU),多刀片大規模并行擴展,刀片服務器價格低廉,采用64位地址空間—單臺服務器容量為2TB,100GB/s的數據吞吐量,價格迅速下降,性能迅速提升。
- 數據存儲可以選擇行存儲或者列存儲,同時對數據進行壓縮。SAP HANA采用數據字典的方法對數據進行壓縮,用整數代表相應的文本,數據庫可以進一步壓縮數據和減少數據傳輸。
百度開源的Doris也在迎頭趕上,并且在百度云中提供云原生部署。Apache Doris是一款架構領先的MPP分析型數據庫產品,僅須亞秒級響應時間即可獲得查詢結果,高效支持實時數據和批處理數據。Apache Doris的分布式架構非常簡潔,易于運維,并且支持10PB以上的超大數據集,可以滿足多種數據分析需求,例如固定歷史報表,實時數據分析,交互式數據分析和探索式數據分析等。Apache Doris支持AGGREGATE、UNIQUE、DUPLICATE三種表模型,同時支持ROLLUP和MATERIALIZED VIEW兩種向上聚合方式,可以更好地支撐OLAP查詢請求。另外,Doris也支持快速插入和刪除數據,是未來實時數倉或者數據湖產品的有力競爭者。
嘗試在OLTP的基礎上融合OLAP的數據庫TiDB、騰訊TBase(云平臺上已改名為TDSQL PostgreSQL版)、阿里的OceanBase都在架構上做了大膽的突破。TiDB采用行存儲、列存儲兩種數據格式各保存一份數據的方式,分別支持快速OLTP交易和OLAP查詢。TBase則是分別針對OLAP業務和OLTP業務設置不同的計算引擎和數據服務接口,滿足HTAP場景應用需求。OceanBase數據庫使用基于LSM-Tree的存儲引擎,能夠有效地對數據進行壓縮,并且不影響性能,可以降低用戶的存儲成本。
02ETL工具選型
目前,業界比較領先的開源ETL數據抽取工具主要有Kettle、DataX和Waterdrop。商業版本的DataStage、Informatica和Data Services三款軟件不僅配置復雜、開發效率低,執行大數據加載也非常慢。
Kettle(正式名為Pentaho Data Integration)是一款基于Java開發的開源ETL工具,具有圖形化界面,可以以工作流的形式流轉,有效減少研發工作量,提高工作效率。Kettle支持不同來源的數據,包括不同數據庫、Excel/CSV等文件、郵件、網站爬蟲等。除了數據的抽取與轉換,還支持文件操作、收發郵件等,通過圖形化界面來創建、設計轉換和工作流任務。
DataX是阿里巴巴集團內部廣泛使用的離線數據同步工具/平臺,實現包括MySQL、Oracle、SQL Server、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute (ODPS)、DRDS等各種異構數據源之間高效的數據同步功能。
Waterdrop是一款易用、高性能、支持實時流式和離線批處理的海量數據處理工具,程序運行在Apache Spark和Apache Flink之上。Waterdrop簡單易用、靈活配置、無需開發,可運行在單機、Spark Standalone集群、Yarn集群、Mesos集群之上。Waterdrop支持實時流式處理,擁有高性能、海量數據處理能力,支持模塊化和插件化,易于擴展。用戶可根據需要來擴展插件,支持Java/Scala實現的Input、Filter、Output插件。
總的來說,Kettle適合中小企業ETL任務比較少并且單表數據量在百萬以下的項目,開發速度快,支持的數據來源豐富,方便快速達成項目目標。DataX支持需要批處理抽取數據的項目,支持千萬級、億級數據的快速同步,性能高效、運維穩定。Waterdrop是后起之秀,在DataX的基礎上還支持流式數據處理,是DataX的有力競爭者和潛在替代產品。
03調度平臺選型
調度平臺可以串聯ETL任務并按照指定的依賴和順序自動執行。調度平臺一般用Java語言開發,平臺實現難度小,大多數數據倉庫實時廠商都有自研的調度平臺。
在早期銀行業的數據倉庫項目中,大多數據ETL過程都是通過DataStage、Informatica或者存儲過程實現的。筆者接觸過最好用的產品就是先進數通公司的Moia Control。Moia Control定位于企業統一調度管理平臺,致力于為企業的批處理作業制定統一的開發規范、運維方法,對各系統的批量作業進行統一管理、調度和監控。Moia Control的系統架構如
圖1所示,系統分為管理節點和Agent節點,管理節點負責調度任務的配置和分發作業,Agent節點負責任務的執行和監控。Moia Control在金融領域具有非常廣泛的應用。
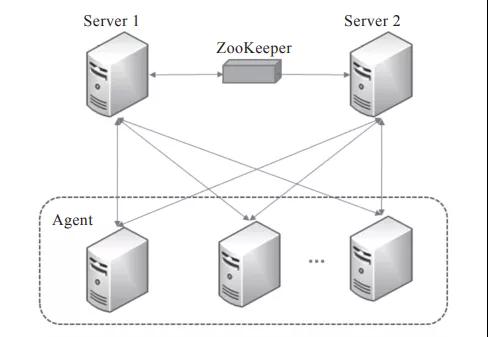
圖1 Moia Control系統架構
在開源領域,伴隨著大數據平臺的崛起,雖然先后涌現了Oozie、Azkaban、AirFlow等深度融合Hadoop生態的產品,但都是曇花一現,目前已經逐步被DolphinScheduler取代。DolphinScheduler于2019年8月29日由易觀科技捐贈給Apache啟動孵化。DolphinScheduler的產品架構如圖2所示。
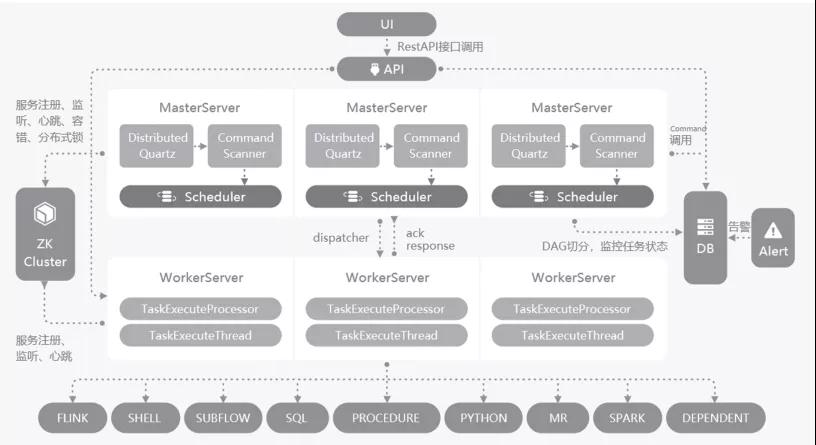
圖2 DolphinScheduler 產品架構
DolphinScheduler是全球頂尖架構師與社區認可的數據調度平臺,把復雜性留給自己,易用性留給用戶,具有如下特征。
1)云原生設計:支持多云、多數據中心的跨端調度,同時也支持Kubernetes Docker的部署與擴展,性能上可以線性增長,在用戶測試情況下最高可支持10萬級的并行任務控制。
2)高可用:去中心化的多主從節點工作模式,可以自動平衡任務負載,自動高可用,確保任務在任何節點死機的情況下都可以完成整體調度。
3)用戶友好的界面:可視化DAG圖,包括子任務、條件調度、腳本管理、多租戶等功能,可以讓運行任務實例與任務模板分開,提供給平臺維護人員和數據科學家一個方便易用的開發和管理平臺。
4)支持多種數據場景:支持流數據處理,批數據處理,暫停、恢復、多租戶等,對于Spark、Hive、MR、Flink、ClickHouse等平臺都可以直接調用。
此外,Kettle本身包含調度平臺的功能,我們可以直接在KJB文件中定義定時調度任務,也可以通過操作系統定時任務來啟動Kettle,還可以去Kettle中文網申請KettleOnline在線調度管理系統。
Kettle通過KJB任務里面的START組件可以設置定時調度器,操作界面如圖3所示。
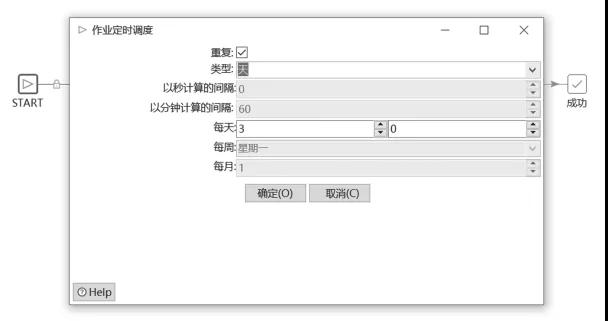
圖3 Kettle定時頁面
此外,在Kettle中文網還提供了功能更為強大的KettleOnline工具,非常適合較大型Kettle項目使用,具體功能這里就不展開介紹了。
除了上述調度工具之外,還有一些小眾的Web調度工具,例如Taskctl、XXL-JOB等。總的來說,都能滿足基本的需求。有研發實力的公司可以在開源版本的基礎上進一步完善功能,打造屬于自己的調度平臺。
04BI工具選型
BI是一套完整的商業解決方案,用于將企業現有的數據進行有效的整合,快速、準確地提供報表并提出決策依據,幫助企業做出明智的業務經營決策。BI工具是指可以快速完成報表創建的集成開發平臺。
和調度平臺不一樣,BI領域商業化產品百花齊放,而開源做成功的產品卻基本沒有。這也和產品的定位有關,調度平臺重點關注功能實現,整體邏輯簡單通用,便于快速研發出滿足基本功能的產品。而BI則需要精心打磨,不斷完善和優化,才能獲得市場的認可。
在早期Oracle稱霸數據庫市場的年代,BI領域有3個巨頭,分別是IBM Cognos、Oracle BIEE和SAP BO。在早期BI領域,IBM 50億美元收購Cognos、SAP 68億美元收購BO都曾創造了軟件行業的收購紀錄。這兩起收購發生分別發生在2007年和2008年。此后是傳統BI的黃金十年,這三大軟件占領了國內BI市場超過80%的份額。筆者參加工作的第一個崗位就是BIEE開發工程師,而后又兼職做過兩年的Cognos報表開發,對二者都有比較深刻的認識。
在傳統BI時代,主要按照星形模型和雪花模型構建BI應用,在開發BI報表之前,必須先定義各種維度表和事實表,然后通過各BI軟件配套的客戶端工具完成數據建模,即事實表和維度表的關聯,以及部分指標邏輯的計算(例如環比、同比、年累計等)。最后在Web頁面上定制報表樣式,開發出基于不同篩選條件下,相同樣式展現不同數據的固定報表。整個開發過程邏輯清晰,模塊劃分明確,系統運行也比較穩定,作為整個數據分析項目的“臉面”,贏得了較高的客戶滿意度。
傳統BI以固定表格展現為主,輔以少量的圖形。雖然模型和頁面的分離讓開發變得簡單,目前廣泛應用于金融行業和大型國企管理系統中,但是也有不少缺點,例如,星形模型的結構在大數據場景下查詢速度非常慢、模型與頁面的分離造成版本難以管控、模型中內嵌函數導致查找數據問題變得困難等。
2017年前后,Tableau強勢崛起,以“敏捷BI”的概念攪動了整個BI市場,引領BI進入一個全新的時代。
Tableau最大的特點是以可視化為核心,強調BI應用構建的敏捷性。Tableau拋棄了傳統BI的模型層,可以直接基于數據庫的表或者查詢來構建報表模塊,大大降低了開發難度,提升了報表的開發效率和查詢性能。曾經需要一天才能完成的報表開發,現在可能一個小時不到就可以完成,極大提升了產出效率。
在傳統BI時代,國產BI軟件雖然也在發展,但是不夠強大。在敏捷BI時代,FineBI、永洪BI、SmartBI、觀遠BI等商業化產品順勢崛起,開始搶占國內BI市場。帆軟公司的Fine Report和FineBI更是其中的佼佼者,穩坐國產BI軟件的頭把交椅,將產品鋪向了廣大中小企業。國產BI在培訓體系上做得更為完善,以至于筆者發現在最近半年的面試中,差不多有一半的應聘者使用過帆軟公司的產品。
在國產化BI之外,跨國軟件公司也在敏捷BI方向上做出了調整,其中筆者接觸過的就有微軟的Power BI和微策略的新一代MSTR Desktop。同時,云廠商也加入BI市場的爭奪,其中百度云Sugar、阿里云QuickBI都是內部產品對外提供服務的案例。
總的來說,在敏捷BI領域,國外廠商的軟件成熟度高,版本兼容性好。國內廠商的軟件迭代比較快,也容易出現Bug。從實現效果上看,以上軟件的差異并不大,BI戰場已經變成了UI的較量了,只要UI能設計出好的樣式,絕大多數BI軟件都可以實現近似的效果。
關于作者:王春波,資深架構師和數據倉庫專家,現任上海啟高信息科技有限公司大數據架構師,Apache Doris和openGauss貢獻者,Greenplum中文社區參與者。 公眾號“數據中臺研習社”運營者。
本文摘編于《高效使用Greenplum:入門、進階與數據中臺》,經出版方授權發布。(書號:9787111696490)轉載請保留文章來源。




















