













我的朋友受到社交媒體的算法推薦“蠱惑”,加入了激進組織
大數據文摘出品
作者:Caleb
說到社交媒體的算法推薦,還真是讓人歡喜讓人憂。
事情是這樣的。
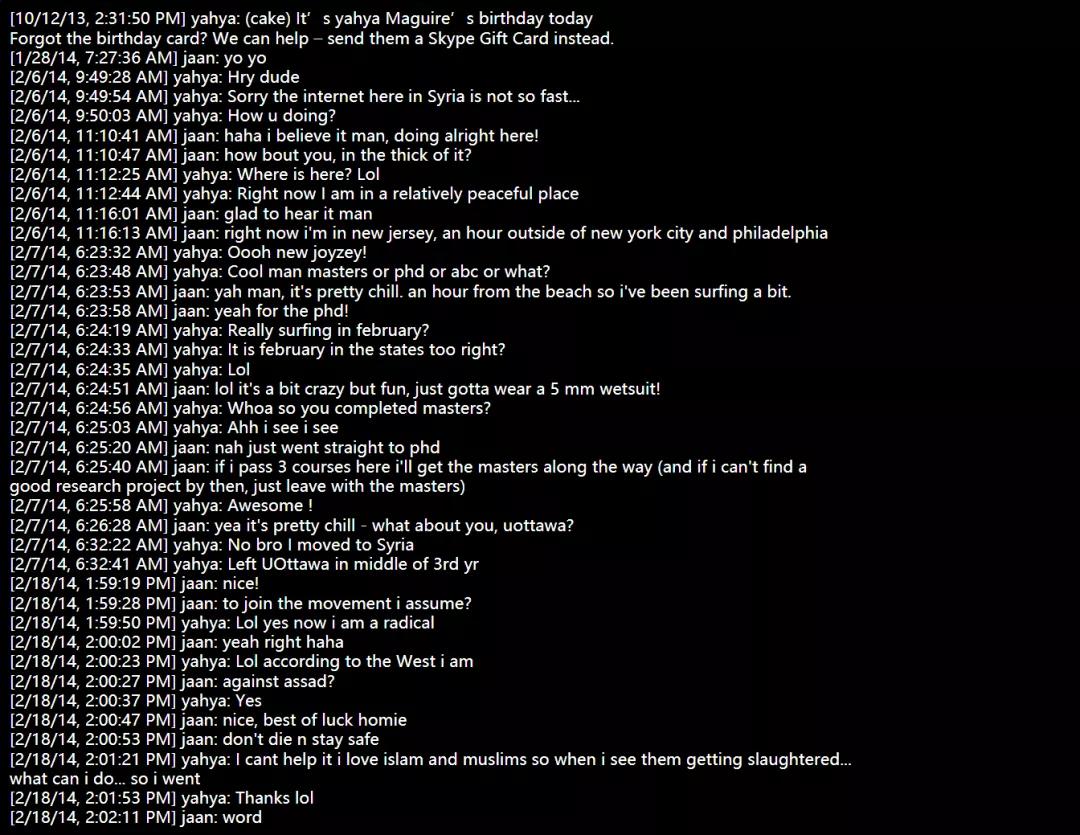
當時,我的一個朋友John正在申請麥吉爾大學的生物學博士,我也正在鉆研生物化學領域。我們因為在同一家制藥廠實習迅速熱絡起來,經常還在我家地下室打球、錄制視頻等。
但是一年后我發現,John變了。他開始狂熱地信仰宗教,總是和我爭論宗教知識應該是世界上唯一的科學,也是從那個時候開始,John把名字改成了Yahya,留起了胡子,說話也帶上了明顯的口音。
同時,John的Facebook賬號上開始涌現出大量的激進內容,其中一些視頻內還對美國和加拿大的所謂“異教徒”懷有明顯的仇恨與惡意。
最后一次與John交談的時候,我已經知道特勤局已經對他進行了長達數月的調查。
結合我在谷歌和DeepMind的實習經歷,以及我在算法推薦系統領域的學習,John的事件讓我開始思考如今風頭正盛的基于推薦算法的社交媒體。
在John這件事上,可以肯定的是,John逐漸激進的事實與Facebook的推薦算法有著密切的關系。但是,還無法確定的是,是怎樣的算法推薦讓John開始轉變信仰,當John的Facebook發帖變得越來越極端的時候,此時的新聞推送是根據怎樣的算法得出的?
當我們嘗盡了基于算法推薦的社交媒體的種種甜頭之后,如今,嚴重的負面效應開始顯現。這在最近美國所發生的一連串事件中都能得到印證,尤其是當平臺自動為你推薦一些激進內容或者是發布一些激進組織的相關信息時。
于是我也開始思考,當我在推特或者其他新聞推送中點開一些激進視頻時,我是否也在無形之中對其成型起到了推波助瀾的作用?
在社交媒體中使用機器學習的風險
隨著智能手機的普及,我們逐漸習慣于把虛擬助手、社交媒體等作為新聞來源來幫助我們了解這個世界。久而久之,平臺的傾向性也會影響我們自身的傾向,甚至是行為。
這些推薦機制的原理都是來源于機器學習。
機器學習算法就是一組指令,幫助機器從數據模式中進行學習,這些模式還能幫助人們進行決策。比如,新聞源就可以通過被稱為推薦系統的機器學習來創建。這在廣告領域的應用可能更為廣泛,廣告商想知道的是,用戶最可能點擊什么樣的廣告,從而更大程度地進行資源分配。
但在這種好處背后是難以撼動的激勵機制和權力結構,Facebook、蘋果和谷歌等公司仍然忙于利用會員制和廣告費來賺取收入,對于“房間里的大象”,所有人都選擇了視而不見。
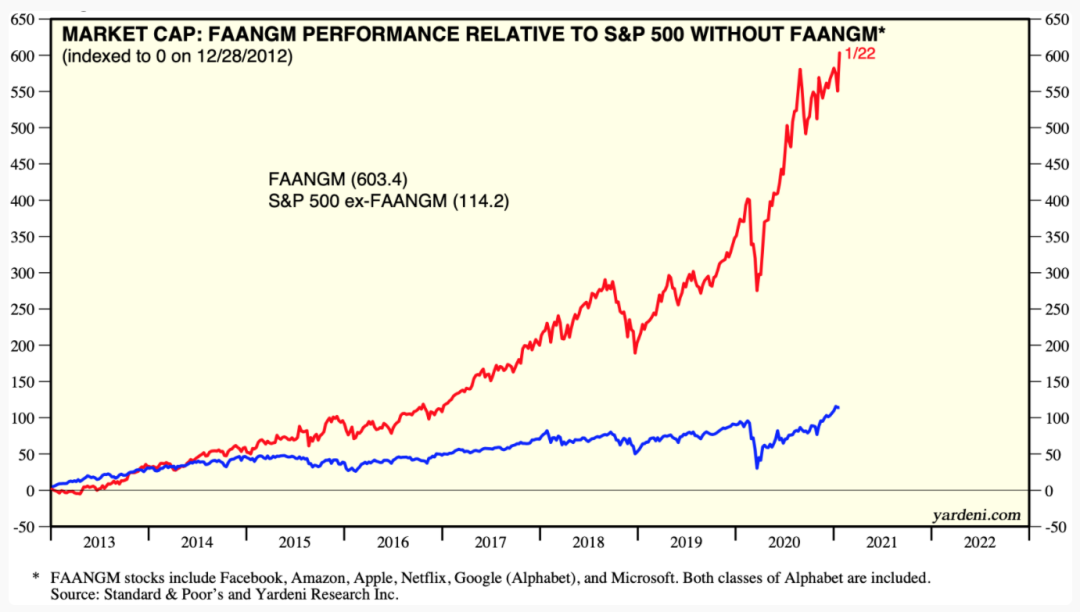
2020年,六家FAANGM公司(Facebook,亞馬遜、蘋果、Netflix、谷歌和微軟)的商業模式組成一個季度標普指數和負責的大部分收益,這些公司的員工平均年薪為339,574美元。
當這種現象成為普遍的時候,社交媒體便能夠利用機器學習來放大現有的不平等,以及針對易受錯誤信息影響的人群發布更帶有偏激性的內容。
最大的證據便是Facebook成立了一支反恐團隊,但具有諷刺意味的是,其本身依賴于機器學習,也不乏相同的商業動機。換句話說,當屏蔽的內容越多,被禁的人就越多,公司的收入就會減少。
目前,Facebook已經承認其對緬甸的報道具有傾向性。同樣,推特、YouTube和Facebook也在近期美國的政治事件中發揮了作用,Facebook的舉報人承認,全球政治操縱能力部分是通過機器學習來創建的,這可能會增加地緣政治風險。
針對如John般這樣可能因為自己的經歷而受到社交媒體影響的人,我們更需要在社會層面上,與相對自由的道德和法律專家以及機器學習研究專家進行更具有針對性的討論。
如何減輕機器學習的社會風險
令人好奇的是,在算法社交媒體的有害影響已被記錄在案的前提下,有哪些法律途徑可以管理以機器學習為動力的企業。例如,在個人層面上,我們都會易受影響于某類新聞,這是受到法律保護,不能被歧視。也就是說,社交媒體利用我們的這些“弱點”進行攻擊其實是非法的。
那么問題來了,哪些途徑可以幫助保留機器學習的收益,同時保護弱勢群體免受有害影響?
假設科學家找到確鑿的證據,根據種族、性別或收入,有些人更容易沉迷于機器學習所推薦的內容,那么我們能否稱,歧視是發生了,從而降低公司的市值?畢竟,社交媒體沉迷對公司而言意味著更深的用戶粘度和參與度,但是在業務指標上好看的數字可能并不會使受其影響的人們變得更好。
除此之外,更直接的一種方式是降低廣告收入。建造AI的實驗室正面臨虧損,這意味著當營收下降到一定程度時,他們將首先離開。
同時,支撐谷歌、Facebook和其他大公司業務的機器學習工具順應的開源的趨勢,正變得更加易于訪問。隨著廣告收入持續下降,算法偏見將會成為主流公眾知識。
收入持續下降、用戶隱私意識覺醒和開放源代碼都可以成為推動社交媒體往良性發展的動力,而不是通過數據來利用用戶。學術實驗室還可以通過領導透明、開放源碼的努力來發揮作用,以幫助了解機器學習系統中的利益相關者如何為研究造福整個社會。
但是,當我們等待并希望有關掌權者創造變革時,作為個人,我們可以做很多事情,以了解和學習如何管理生活中許多方面的機器學習算法帶來的風險。
個人應該怎么做
正如上文所言,這些策略本身其實是告訴自己,代表自身及他人倡導與收集N=1數據,屆時可能會對大型社交平臺的動機產生更深刻的認識。
與受影響的人開始對話:參與工作環境。如果你正在構建機器學習工具,請實際使用它們。需要考慮到,這份工具可能會影響誰,并與這些人交談。交談中可以簡單描述所做的工作,以及驅動該技術的數據和商業利益。
例如,我從描述我的機器學習和心理健康研究中獲得了強烈的負面反饋,從而塑造了該研究并幫助改正了課程。與我們的朋友,家人和社區的這種非正式的民族志田野調查被低估了,并提供了一種低風險、高影響力的方式來告知我們學習的內容:與誰以及為誰學習。
注意到人們在工業界和學術界研究的是不同事物。工業往往是一條單向道,警惕金籠效應,即那些賺很多錢的人可能會不愿考慮或討論機器學習的風險,或者可能由于擔心被解雇而避免對其進行研究。
例如,算法公平性的領域得到關注是因為微軟禁止其研究人員對歧視性廣告的研究。類似的,谷歌人工智能與道德團隊因為在論文中強調了谷歌搜索模式的缺陷而被解雇。此類事件對相關人員而言代價高昂,這就是為什么在商業利益凌駕于公眾利益和學術自由之上的罕見情況下,他們能夠大聲疾呼,舉報或以其他方式告知公眾時,需要得到額外支持的原因。
阻止定位并清除隱私設置。如果要讓80億人選擇通過利用私人數據來個性化廣告,那么激勵錯誤信息的商業模式將很難發展。使用uBlock或其他瀏覽器擴展程序可以阻止所有新聞提要或HTML元素以及在YouTube等上使用機器學習創建的內容;在Facebook上取消關注所有人以清除新聞源。
通過啟用自動刪除位置、網絡和語音記錄的歷史記錄來刪除數據。我為私人利益犧牲的數據越少,我注意到的認知負荷就越少,這也許是因為對涉及我的數據的預期場景,可能應用的機器學習系統以及系統在世界范圍內產生的第二級和第三級影響的擔憂減少了。
希望通過本文為大家提供一個解決問題的思路,找到問題可能出現的地方,問題是如何發展起來的,以及我們應該采取怎樣的方法來解決。
當然,回到本文主題上,無論是對于激進態度本身,還是錯誤信息,我們都應該隨時保持警惕,以阻止那些無法很好地管理機器學習而做出不明智決定的商業動機。
相關報道:
https://www.reddit.com/r/MachineLearning/comments/l8n1ic/discussion_how_much_responsibility_do_people_who/
https://jaan.io/my-friend-radicalized-this-made-me-rethink-how-i-build-AI
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】






















