漫畫版:什么是深度學習?
Google 如何在短短幾秒鐘內將整個網頁翻譯成不同的語言,或者你的手機圖庫如何根據它們的位置對圖片進行分組? 這些都是深度學習的結果。
但什么是深度學習呢?

深度學習是機器學習的一個子集,而機器學習又是人工智能的一個子集。
人工智能是一種使機器能夠模仿人類行為的技術,機器學習是一種通過使用數據訓練的算法來實現 AI 的技術,最后深度學習是一種受人腦結構(生物神經網絡)啟發的機器學習。這種結構在深度學習領域稱為人工神經網絡。
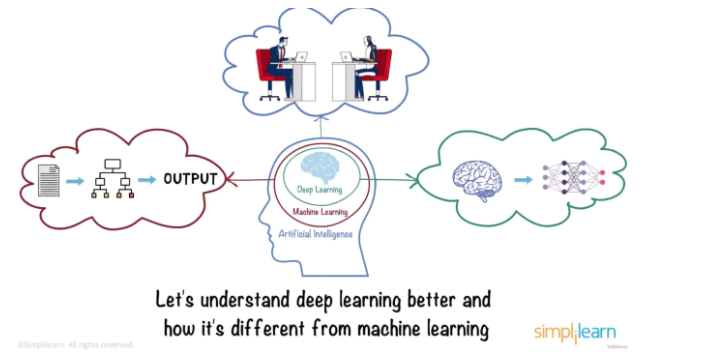
讓我們來更好地理解深度學習,以及它與機器學習的區別。
假設我們有一個可以區分西紅柿和櫻桃的機器,如果使用機器學習完成,則必須告訴機器可以區分兩者的特征。這些特征可能是大小(Size)和莖的類別(Type of Stem)。
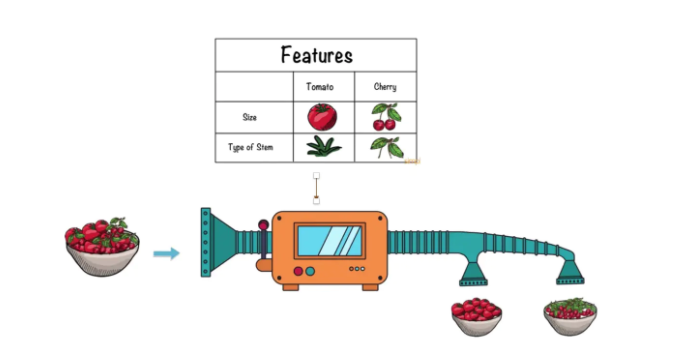
如果使用深度學習,神經網絡可以提取特征,而不需要人工干預。
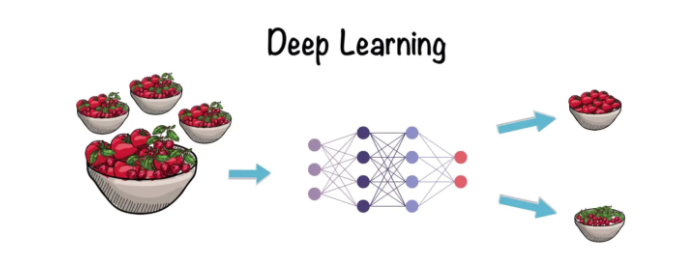
當然,這種特性需要擁有大量的數據來訓練我們的機器。現在讓我們來深入研究神經網絡的工作原理。
原理
在這里,我們有三個學生,他們每人在一張紙上寫下數字 9, 但他們寫的并不完全一樣。人類的大腦可以很容易地識別數字,但是計算機如何識別它們? 使用深度學習可以實現。
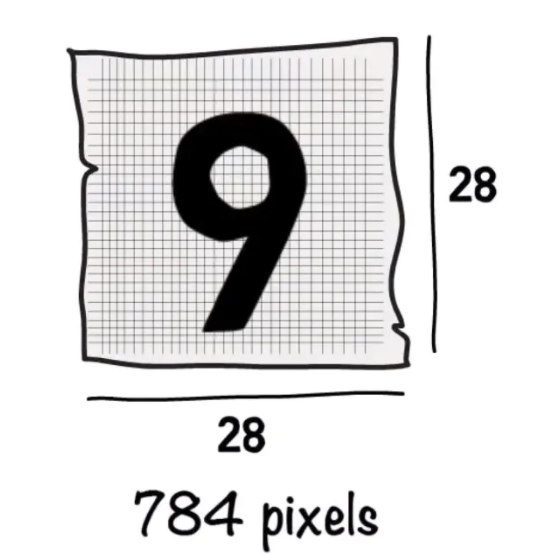
每個數字以 28x28 像素的圖像形式顯示,總計 784 像素。
這是一個經過訓練可識別手寫數字的神經網絡,神經元是神經網絡中最基本的的核心實體,是進行信息處理的地方,784 個像素中的每個像素都被送到神經網絡第一層的神經元,這形成了輸入層,輸入層僅接受輸入,不進行函數處理。
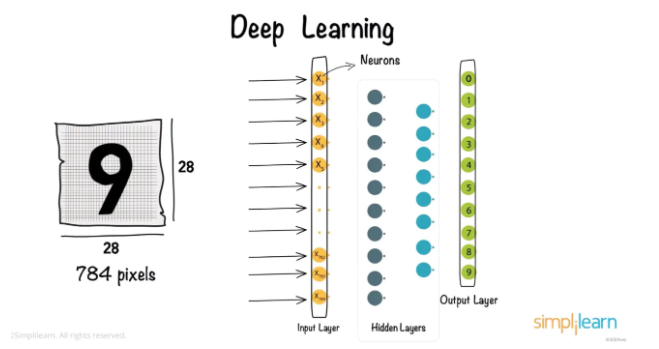
另一端是輸出層,輸入層與輸出層之間的一層神經元稱為隱含層。隱含層與輸出層的神經元都是擁有激活函數的功能神經元。
輸入層神經元接收到 784 個輸入信號,這些輸入信號通過帶權重的連接進行傳遞,神經元接收到的總輸入值將與神經元的閾值(每個神經元都有一個閾值稱為偏差 Bias)進行比較,然后通過激活函數(Activation Function)處理以產生神經元的輸出,激活函數的結果決定了神經元是否被激活。
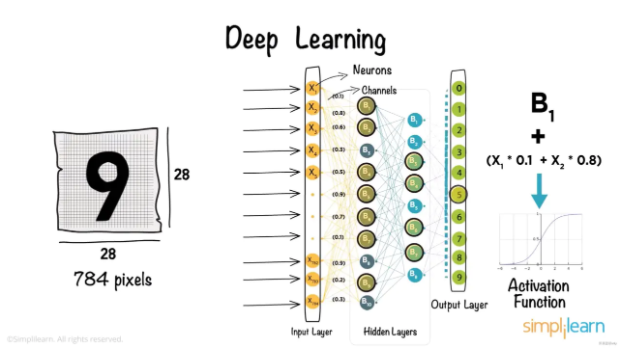
神經網絡的學習過程,就是根據訓練數據來調整神經元之間的“連接權”(connection weight)以及每個功能神經元的閾值。換言之,神經網絡學到的東西,蘊含在連接權與閾值中。
應用
那么深度學習有哪些應用呢?

在客服行業:當大多數人與客服代理交談時,交談看起來是那么真實,他們甚至沒有意識到這實際上是個機器人。
在醫療行業,神經網絡可檢測癌細胞并分析 MRI 圖像以提供詳細結果。
像科幻小說一樣的自動駕駛汽車現在已經成為現實。蘋果、特斯拉和日產一些公司在研發自動駕駛汽車。

局限性
深度學習的范圍很廣,但也面臨著一些局限性。

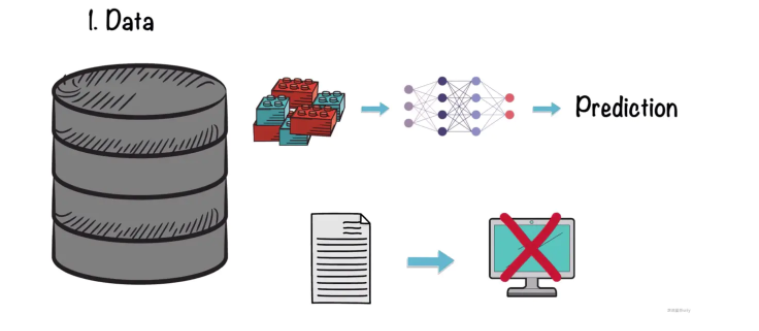
數據量
第一個局限性便是數據。雖然深度學習是處理非結構化數據的最有效方法,但神經網絡需要大量的數據來訓練。
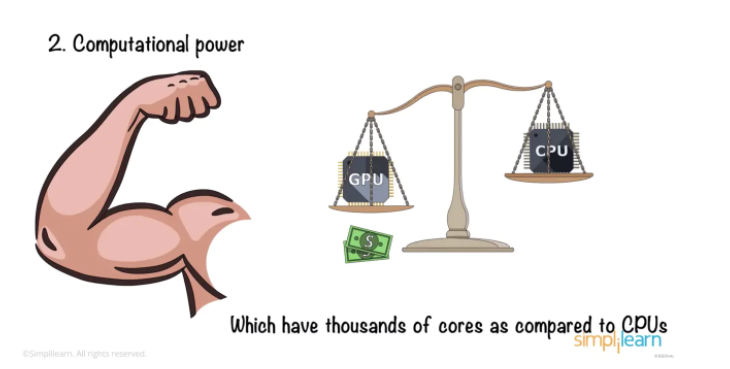
計算能力
假設我們擁有大量的樣本數據,但并不是每臺機器都有處理這些數據的能力,這給我們帶來了第二個限制:計算能力。通常簡稱“算力”。
訓練神經網絡需要成千上萬的圖形處理單元。與 CPU 相比,GPU 當然更貴。
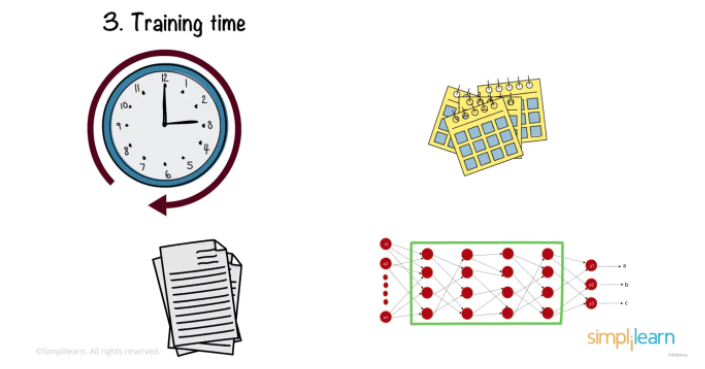
訓練時間
最后就是訓練時間,深度神經網絡需要幾個小時甚至幾個月的訓練,時間隨著網絡中數據量和層數的增加而增加。
深度學習框架
一些流行的深度學習框架,包括 Tensorflow、Pytorch、Caffe、DL4J 和 Microsoft cognitive toolkit。

未來
我們對深度學習和人工智能在未來的應用只看到了表面,未來會充滿驚喜。

Horse 技術正在為盲人開發一種使用深度學習的設備,用計算機視覺向用戶描述世界,整體復制人類的思維。
小測驗
所以給你一個小測驗, 神經網絡的正確工作順序排序:
- A. The bias is added 加偏差
- B. The weighted sum of the inputs is calculated 計算輸入的加權和
- C. Specific neuron is activated 特異性神經元被激活
- D. The result is fed to an activation function 結果被輸入到激活函數

答案:
B、 計算輸入的加權和
A、 加偏差
D、 結果被輸入到激活函數
C、 特異性神經元被激活
說明:在神經網絡中,一層中的每個神經元都與相應層中的其他神經元相連。這些連接具有隨機權重。計算輸入的加權和,并以偏置形式添加一個附加輸入(w * x + b)。其結果被輸入到激活函數。基于特定的閾值,只有那些超過閾值的神經元才會被激活。