













如何采用強化學習幫助選擇客戶更加關注的廣告
譯文【51CTO.com快譯】如今,全球的數字廣告代理商每天都會在新聞網站、搜索引擎、社交媒體、視頻流以及其他媒體平臺上投放數以億計的廣告。他們都想解答一個問題:其產品目錄中有哪些廣告更能吸引特定的用戶?當面對數以百計的網站、數以萬計的廣告以及數以百萬的訪問者時,獲得這個問題的正確答案將會對企業增加收入產生巨大影響。
對于廣告代理商來說,幸運的是,強化學習提供了一種解決方案(強化學習是一種主要應用在棋局和視頻游戲而聞名的人工智能分支技術)。采用強化學習模型可以獲得更大的回報。就網絡廣告而言,強化學習模式致力于尋找讓用戶更容易點擊的廣告。
全球的數字廣告行業每年產生數千億美元的收入,并提供了有關強化學習功能的案例研究。
1.采用A/B/n測試
為了更好地理解強化學習為優化廣告的推廣提供的幫助,可以考慮一個簡單的場景的應用:例如一家新聞網站已經和一家公司簽訂了合同,在新聞網站上刊登這家公司的廣告。該公司為在這個網站發布了五個不同的廣告,而在處理兩個以上的備選方案時,可以稱之為A/B/n測試。
網站運營者的首要目標是找到產生點擊次數最多的廣告。在廣告術語中,需要最大限度地提高點擊率(CTR)。點擊率是點擊次數與展現廣告數量的比值,也稱為展示次數。例如,如果展現了1,000次廣告,為網站帶來了3次點擊,則其點擊率將是3/1000 = 0.003或0.3%。
在通過強化學習解決問題之前,先來討論一下A/B測試,這是一種用于比較兩個競爭解決方案(A和B)的性能的標準技術,例如不同的網頁布局、產品推薦或廣告。當處理兩種以上的選擇時,稱為A/B/n測試。
在A/B/n測試中,通常將實驗對象隨機分為不同的組,每組都提供一種可用的解決方案。而在這個新聞網站發布廣告的案例中,這意味著將隨機向網站的每個訪問者展示五個廣告中的一個,并對展示結果進行評估。
假設對A/B/ n測試進行了10萬次展示,相當于每個廣告大約有2萬次展示。以下是5個廣告的點擊率:
廣告1:80/20,000=0.40%
廣告2:70/20,000=0.35%
廣告3:90/0,000=0.45%
廣告4:62/20,000=0.31%
廣告5:50/20,000=0.25%
該網站在10萬次廣告展示中獲得了352美元的收入,平均點擊率是0.35%。更重要的是,網站運營者發現第3個廣告的展示效果要優于其他幾個廣告,并將繼續將其用于吸引其他訪問者。而使用展示效果最差的廣告(第5個廣告),獲得收入應為250美元。如果使用展示效果最好的廣告(第3個廣告),收入應為450美元。因此,采用A/B/n測試提供了最低和最高收入的平均值,并提供了除了展現點擊率之外更具價值的知識。
數字廣告的轉化率其實非常低。在這個示例中,效果最好的廣告和效果最差的廣告之間只存在0.2%的細微差別。但是這種差別會可能在規模上產生重大影響。與第5個廣告相比,在展示次數為1,000次的情況下,展示第3個廣告將會多獲得2美元。在展示次數為100萬次的情況下,這個差額為2,000美元。當投放數十億次廣告時,0.2%的細微差別會對網站收入產生巨大影響。
因此,找到這些細微的差別對于廣告優化非常重要。A/B/n測試的問題在于查找這些差別并不是很有效。它通常平等地對待所有廣告的展示,只有運行數萬次廣告,才能以可靠的置信度發現它們之間的差異。這可能會導致收入損失,尤其是當發布更多廣告時。
傳統A/B/n測試的另一個問題是它是靜態的。一旦找到了最佳的廣告,就必須堅持下去。如果環境由于出現新的因素(例如季節和新聞趨勢等)而發生變化,并導致其他廣告中的一個具有潛在更高的點擊率(CTR),除非重新進行A/B/n測試,否則難以發現。
如果可以更改A/B/n測試使其更高效、更動態呢?這就是強化學習發揮重要作用的地方。廣告代理商必須找到一種最大限度地提高其回報的方法。
在這個案例中,強化學習代理的行為是要展示這五個廣告。而用戶每次點擊廣告,強化學習代理都會獲得獎勵的積分。因此必須找到一種最大限度提高廣告點擊量的方法。
2.多臂老虎機(Multi-armed Bandit)
多臂老虎機是找到通過反復試驗發現幾種解決方案之一的方法。
在某些強化學習環境中,其動作是按順序進行評估的。例如在電子游戲中,在完成一個關卡或贏得一場比賽時,必須執行一系列動作才能獲得獎勵。而在投放廣告時,每個廣告展示的結果都是獨立評估的,這是一個單一步驟的環境。
為了解決廣告優化問題,可以將使用多臂老虎機(Multi-armed Bandit)算法,這是一種適用于單一步驟強化學習的算法。多臂老虎機(MAB)來自一個假想場景:在這個場景中,很多人都在玩老虎機,并知道這些老虎機有不同的中獎率,但并不知道哪一臺老虎機的中獎率最高。
如果某人堅持玩某一臺老虎機,可能會失去選擇中獎率最高的老虎機的機會。因此,必須找到一種有效的方法來發現最高中獎率的老虎機,而又不會投入太多的籌碼。
廣告優化案例就是一種采用多臂老虎機原理的一個典型示例。在這種情況下,強化學習代理必須找到一種方法來發現點擊率最高的廣告,而不會在效率低下的廣告上浪費太多的時間和資源。
3.探索vs.開發
每個強化學習模型都面臨的一個問題是“探索vs.開發”的挑戰。開發意味著堅持使用強化學習代理迄今為止發現的最佳解決方案,而探索意味著嘗試其他解決方案,希望找到比當前最佳解決方案更好的解決方案。
在選擇廣告的應用中,強化學習代理必須在選擇展示效果最佳的廣告和探索其他選擇之間做出決定
解決開發或探索問題的一種方法是采用“ε-greedy”算法。在這種情況下,強化學習模型通常會選擇最佳的解決方案,在指定百分比的情況下(ε因子),將隨機選擇其中一個廣告。
每個強化學習算法都必須在探索最佳解決方案和探索新選擇之間找到適當的平衡。這是一個實際的運作方式。假設有一個采用ε-greedy算法的多臂老虎機(MAB)代理,其ε因子設置為0.2。這意味著代理可以在80%的時間中選擇效果最佳的廣告,而另外20%的時間選擇其他廣告。
強化學習模型是在不知道哪個廣告效果更好的情況下啟動的,因此為每個廣告分配了相同的投放次數。當所有廣告的投放次數均等時,將會在每次投放廣告時隨機選擇其中一個。
在投放200次廣告之后(5個廣告分別有40次投放次數),有人點擊了一次第4個廣告。強化學習代理會按以下方式調整廣告的點擊率:
廣告1:0/40=0.0%
廣告2:0/40=0.0%
廣告3:0/40=0.0%
廣告4:1/40=2.5%
廣告5:0/40=0.0%
現在,強化學習代理認為第4個廣告是效果最好的廣告。對于每個廣告的展示,將選擇一個介于0和1之間的隨機數。如果該數字大于0.2(ε因子),則會選擇第4個廣告。如果該數字小于0.2,則會隨機選擇一個其他廣告。
現在,強化學習代理在另一個用戶點擊廣告之前又展示了200次其他廣告,這次有人點擊了一次第3個廣告。需要注意的是,在這200次展示中,由于第4個廣告是最佳廣告,將獲得80%的廣告展示次數(160次)。而其余的平均分配給其他廣告,而新的點擊率值如下:
廣告1:0/50=0.0%
廣告2:0/50=0.0%
廣告3:1/50=2.0%
廣告4:1/200=0.5%
廣告5:0/50=0.0%
現在最理想的廣告變為第3個廣告。它將獲得80%的廣告展示次數。假設再獲得100次展示(第3個廣告為80次,而其他每個廣告為4次),則有人點擊了一次第2個廣告。以下是新的點擊率分布狀況:
廣告1:0/54=0.0%
廣告2:1/54=1.8%
廣告3:1/130=0.7%
廣告4:1/204=0.49%
廣告5:0/54=0.0%
現在,第2個廣告是最佳解決方案。隨著投放更多廣告,點擊率將反映每個廣告的實際價值。效果最好的廣告將獲得最多的展示次數,但強化學習代理將繼續探索其他選擇。因此,如果環境發生變化,用戶開始對某個廣告有著更積極的反應表現,強化學習就可以發現。
在投放了10萬個廣告之后,其分布狀況如下所示:
廣告1:123/30,600=0.40%
廣告2:67/18,900=0.35%
廣告3:187/41,400=0.45%
廣告4:35/11,300=0.31%
廣告5:15/5,800=0.26%
使用ε-greedy算法,可以將10萬次廣告展示的收入從352美元提高到426美元,平均點擊率達到0.42%。這是對傳統的A/B/n測試模型的重大改進。
改進ε-greedy算法
ε-greedy強化學習算法的關鍵是調整ε因子。如果將其設置得太低,將利用認為最好的廣告,其可能的代價是找不到更好的解決方案。例如,在上面探索的示例中,第四個廣告恰好有了第一次點擊,但從長遠來看,它的點擊率并不是最高的。因此小樣本不一定代表真實的分布。
另一方面,如果將ε因子設置得過高,則強化學習代理將會浪費太多資源來探索非最佳解決方案。
改善ε-greedy算法的一種方法是定義動態策略。當多臂老虎機(MAB)模型開始運行時,可以從較高的ε因子開始進行更多的探索和更少的開發。隨著模型投放更多的廣告,并更好地估計每個解決方案的價值,它可以逐漸減小ε因子直至達到閾值。
在優化廣告問題的背景下,可以將ε因子設為0.5,然后在每1000次廣告展示后將其減小0.01,直到達到0.1。
改善多臂老虎機(MAB)的另一種方法是將更多的精力放在新的觀測值上,并逐漸降低原有觀測值的價值。這在動態環境(例如數字廣告和產品推薦)中特別有用,在動態環境中解決方案的價值會隨著時間而變化。
這是一種非常簡單的方法。投放廣告后更新點擊率的傳統方法如下:
(result + past_results)/impressions
此處,result是所顯示廣告的結果(如果點擊則為1,如果未點擊則為0),past_results是這個廣告迄今為止獲得的累計點擊次數,而impressions數量是該廣告已投放的總次數。
要逐漸淡化原有結果,可以添加一個新的alpha因子(介于0和1之間),并進行以下更改:
(result + past_results * alpha)/impressions
這個微小的變化將使新的觀察結果帶來更大的影響。因此,如果有兩個相互競爭的廣告,而它們的點擊次數和展示次數相等,那么在強化學習模型中,將會選擇點擊次數最高的那個廣告。此外,如果某個廣告過去的點擊率非常高,但最近卻沒有響應,則其價值在該模型中的下降速度會更快,從而迫使強化學習模型更早地轉向其他替代方案,并在效率低下的廣告上使用更少的資源。
為強化學習模型添加場景
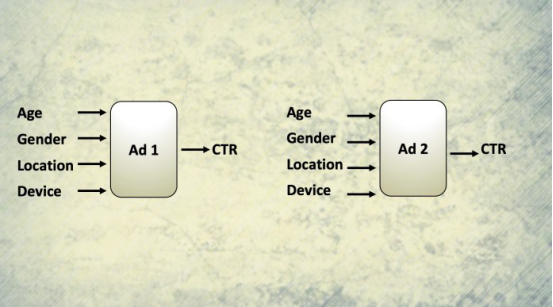
上下文老虎機利用函數近似來考慮廣告受眾的個體特征
在互聯網時代,網站、社交媒體和移動應用程序擁有大量用戶的信息,例如他們的地理位置、設備類型以及觀看廣告的確切時間。社交媒體公司擁有更多關于他們用戶的信息,其中包括年齡、性別、朋友和家人,他們過去分享的內容類型。喜歡或點擊的帖子類型等等。
這些豐富的信息使這些公司有機會為每個觀眾提供個性化廣告。但是,所創建的多臂老虎機(MAB)模型向所有人顯示了相同的廣告,并且沒有考慮每個受眾的特定特征。如果想為多臂老虎機(MAB)增加上下文該怎么辦?
一種解決方案是創建多個多臂老虎機(MAB)模型,每個模型針對特定的用戶子領域。例如,可以為北美、歐洲、中東、亞洲、非洲等地用戶創建單獨的強化學習模型。如果還要考慮性別怎么辦?那么將為北美地區的女性用戶提供一種強化學習模型,為北美地區的男性用戶提供另一種強化學習模型等。如果還要添加年齡和設備類型等因素,可能看到它很快就會成為一個大問題,這造成多臂老虎機(MAB)模型數量激增,難以訓練和維護。
一種替代解決方案是使用“上下文老虎機”(Contextual Bandit),這是考慮到上下文信息的多臂老虎機(MAB)的升級版本。上下文老虎機沒有為每個特征組合創建單獨的多臂老虎機(MAB),而是使用“函數近似”,它試圖根據一組輸入因素對每個解決方案的性能進行建模。
無需過多討論細節,上下文老虎機使用監督的機器學習根據位置、設備類型、性別、年齡等來預測每個廣告的效果。多臂老虎機(MAB)是每個廣告使用一個機器學習模型,而不是每個特征組合都需要創建上下文老虎機。
這總結了關于通過強化學習優化廣告的討論。而強化學習技術可用于解決許多其他問題,例如推薦內容和產品或動態定價,并且可用于其他領域,例如醫療保健、投資和網絡管理等行業領域。
原文標題:How reinforcement learning chooses the ads you see,作者:By Ben Dickson
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】


























