ML和數據趨勢:總結2020,并研究和超越2021
2020在世界范圍內帶來了數字化爆炸。微軟估計大流行(三月和四月)的前兩個月推動了兩年的數字化。在整個年度剩下的時間里,大流行加速了對市場的喚醒,這已經很長一段時間了:每個成功的現代化公司都需要不僅是一家軟件公司,而且是一個數據公司。
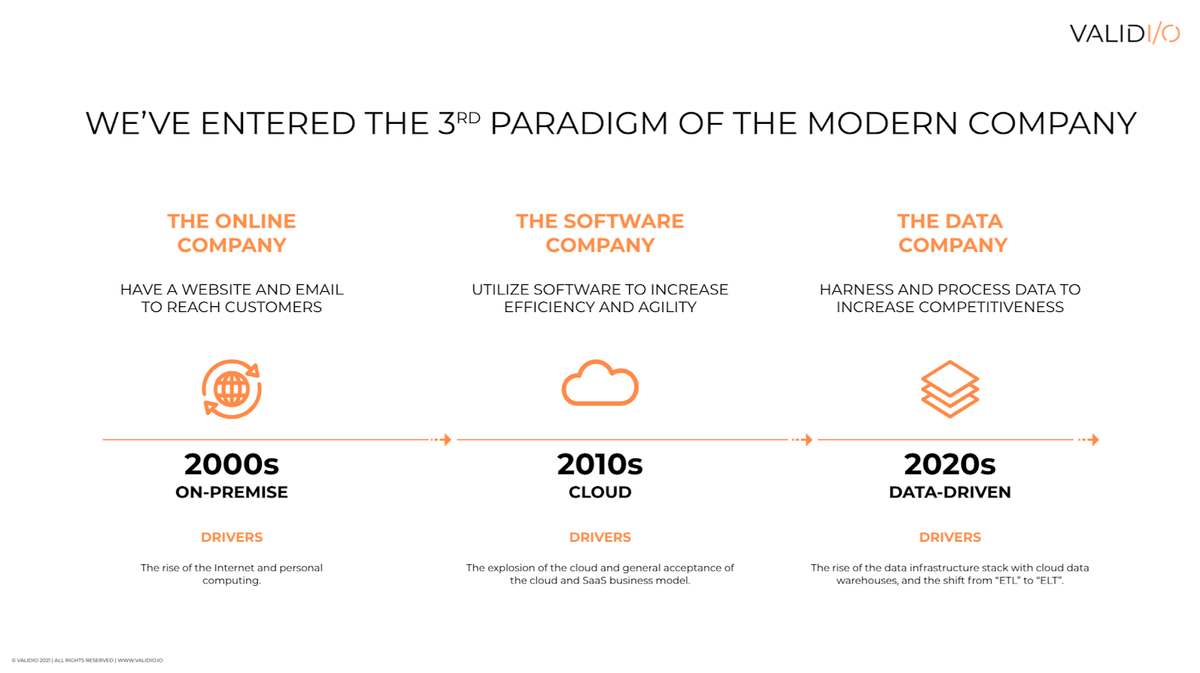
加速數字化和我們越來越多的胃口和生成數據在2020年的數據+ ML景觀中推動了大量的發展。由于公司已經開始獲得過去幾年的預測分析和ML倡議的利益,他們顯然在2021年展示一個健康的食欲。“我們可以更快地處理更多數據,更快和更便宜嗎?我們如何在生產中部署更多ML模型?我們應該在實時做得更多嗎?“……列表繼續。在過去幾年中,我們在數據基礎設施空間中經歷了一個驚人的演變。數據驅動的組織已從ETL(提取,轉換,負載)移動到ELT(提取,負載,變換),其中原始數據從源系統復制并加載到數據倉庫/數據湖中,然后轉換為。現在甚至是一個新的范式在叫做反向ETL的制作中,展示了這個空間中進化的速度。
“現代數據棧”的概念在制作中是多年的 - 它開始出現在2012年時,隨著Redshift,亞馬遜的云數據倉庫推出。但在過去的幾年里,甚至可能在2020年被Snowflake截止,2020年被Snowflake夸張的IPO,云倉庫的普及已經爆炸地增長,所以擁有整個數據和ML工具和周圍的公司。
2020年代正在成為數據十年。雖然2010年是SaaS的十年 - 例如當Salesforce成為第一個違反100億美元的SaaS公司時,2020年代將成為在強大的世俗途中成長的數據公司的時代(數據庫初創公司,數據質量初創公司,數據譜系啟動,機器學習啟動等)。
> Image courtesy of Validio
正如我們剛剛進入咆哮的數據20,我們希望突出一些我們在數據和ML基礎架構內展開得令人興奮的趨勢:
- MLOPS穿過鴻溝
- 從河流進入董事會的數據質量
- 統一的數據基礎架構和新數據層出現了
- 現代數據云(倉庫VS Data Lakehouse)的戰爭為真實升溫
- 數據工程師的崛起
1. MLOPS穿過鴻溝
ML,特別是在企業空間中,歷史上一直緩慢且難以擴大,合作一直是困難和運營的模型,實際提供業務價值在(亞馬遜,Facebook,Airbnbs和世界外的Google之外)。然而,許多ML工具公司使用的“舊”諺語,其中80%的模型永遠不會使其進入生產,肯定達到了2021年的到期日期。事實是越來越多的公司正在成功將ML模型部署到生產中。

正如我們(希望)通過AI炒作的高峰(例如,為AI為AI的緣故),我們看到企業中出現了良好的“MLOPS”的需求 - 即機器學習操作措施意味著標準化和簡化生命周期生產機器學習。
來自Kleiner Perkins的Bucky Moore借用了他1月博客文章的橫穿Chasm框架,爭論我們在MLOPS工具空間中的“早期大部分”采用階段。與“創新者”和“早期采用者”群體相比,大多數人被描述為實用主義者,尋求全面和經濟的解決問題,最好是來自市場領導者。與創新者和早期采用者不同,大多數人對采用技術不感興趣,因為它們是“新的”,他們也不關心第一的風險。
一個相信MLOPS已經過鴻溝,沒有,MLOPS的崛起(即ML的DEVOPS)信號從研發和POC(如何建立模型)到操作(如何運行模型)的行業轉變。
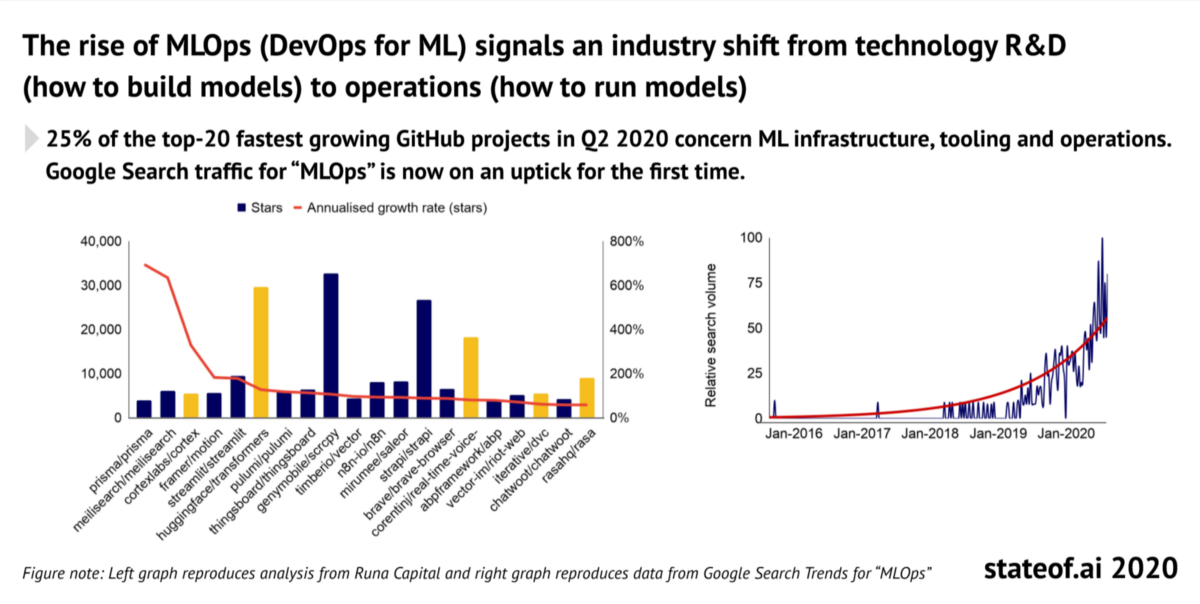
根據艾恩貝納奇和伊恩·霍加爾斯的艾達2020年報告,25%的2020次增長最快的GitHub項目中,Q2 2020有關ML基礎設施,工具和操作。谷歌搜索流量為“MLOPS”現在是第一次上升。隨著組織繼續開發機器學習(ML)的練習,越來越需要能夠處理整個ML生命周期的強大和可靠的平臺需求。MLOP的崛起是有前途的,但許多挑戰仍然存在,與任何新技術范例一樣。
> Image courtesy of State of AI Report 2020
2. 數據質量從河流進入會議室的步驟
我們在2020年經歷了在數據質量周圍的嗡嗡聲中清晰的加速度。大流行強調了需要不斷管理,監控和驗證數據質量和模型的需要,因為由于市場條件快速變化,消費者行為和輸入數據,世界各地的ML型號在2020年初開始故障。在2021年,數據質量正在成為數據驅動組織使用的任何類型的分析系統的現代數據棧的核心部分 - 從基本報告到生產中的高級機器學習和預測分析。
數據質量差是廣泛的機器學習的挑戰性。與數據漂移一起,數據質量差是ML模型精度隨著時間的推移最低的原因之一。
ML質量要求很高,并且壞數據可能導致雙重背突發:當預測模型接受不良預測模型(壞)數據時,當模型應用于新(壞)數據時,以告知未來的決策。較差的數據質量的挑戰是ML的獨特之一 - 雙背突發的第二部分影響所有數據驅動的決策,包括BI工具和儀表板,客戶體驗優化,業務分析和業務運營。事實上,它根據HBR(并鑒于數據加速度,今日售價為3萬億美元,今天該數字可能更高)。
數據社區中的數據質量周圍的嗡嗡聲由Uber和Airbnb的數據工程團隊擔任,他們都寫了關于評估和管理數據質量問題的文章以及他們構建的東西來處理它。
質量問題源于跨越堆棧:數據源和攝入,統一和集成的不一致(例如,數據庫并購,云集成),模式更改,源系統更改,系統升級,記錄錯誤,格式不一致,人類錯誤……列表繼續。目前,大多數公司都沒有有效的流程或技術來識別“壞數據”或導致它的內容。通常,它是反應性的:有人發現問題,數據工程團隊手動工作才能識別錯誤(并且希望其來源)并修復它。使數據適合目的是數據專業人員的最耗時的任務(占用最多80%),順便提一下,他們最不享受的一項任務。
但是監控和驗證數據質量的軟件和工具開始出現,并且正在增加現代數據驅動的公司及其數據基礎架構堆棧的興趣。雖然有幾個用于監視代碼和缺失分類的工具(例如DATADOG,SUMOLogic,New Rlic,SPLUCK),但數據工作流程仍然主要是手動管理或DIY解決方案。
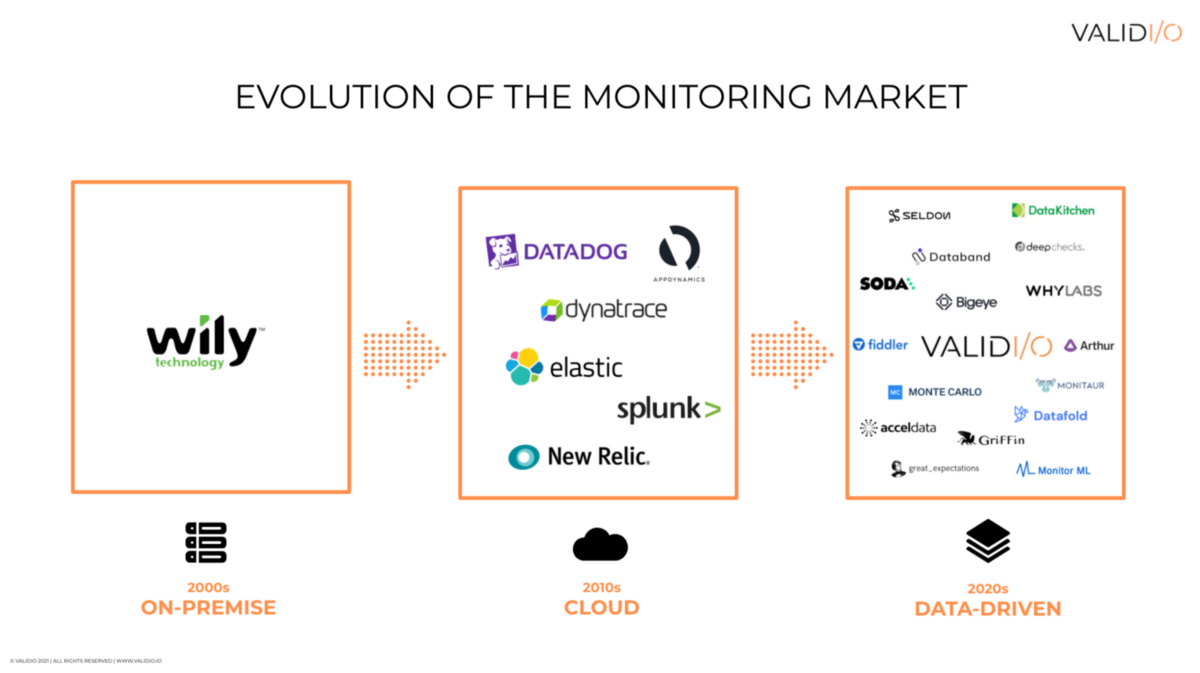
> Image courtesy of Validio
云原生計算無法成為我們的軟件開發和工具的新時代。作為數據驅動的系統(經常通過機器學習啟用)現在有能力解鎖下一波創新浪潮,我們將看到類似的數據質量和模型性能監控工具,以實現實時數據質量保證,數據驗證,數據漂移管理,模型性能優化等
3. 統一的數據基礎架構和新數據層出現
通過現代企業數據卷的爆炸性增長,更多的組織比以往任何時候都有更多的組織,正在處理和存儲大量的業務分析和運營數據。這種趨勢導致需要現代數據基礎架構架構。Andreessen Horowitz通過發布現代數據基礎設施的藍圖,真正開啟了2020年的游戲。
兩個關鍵班次推動了Dataops的興起,隨后對統一數據基礎設施的需求是基于云的數據倉庫的升高以及從ETL轉移到ELT(提取,轉換,加載,加載,負載,變換)的轉變。
在傳統數據倉庫中,存儲和計算耦合,因此只能存儲有用的數據是有意義的。因此,導入數據的標準過程是ETL:在加載到數據倉庫時,將提取的數據轉換(連接,聚合,清除等)。但隨著2012年亞馬遜紅移的商業推出,2014年第一艘云原生數據倉庫和Snowflake,儲存量和計算的架構被解脫出來。從那時起,計算能力飆升,而成本急劇困擾。
進入elt。通過ELT,提取的數據以其原始形式加載到數據倉庫中 - 然后在云中轉換。由于ELT已經刪除了收集和存儲數據的障礙,因此新興的默認模式是:“將所有內容推到Redshift / Snowflake / BigQuery,我們將在以后處理它”。
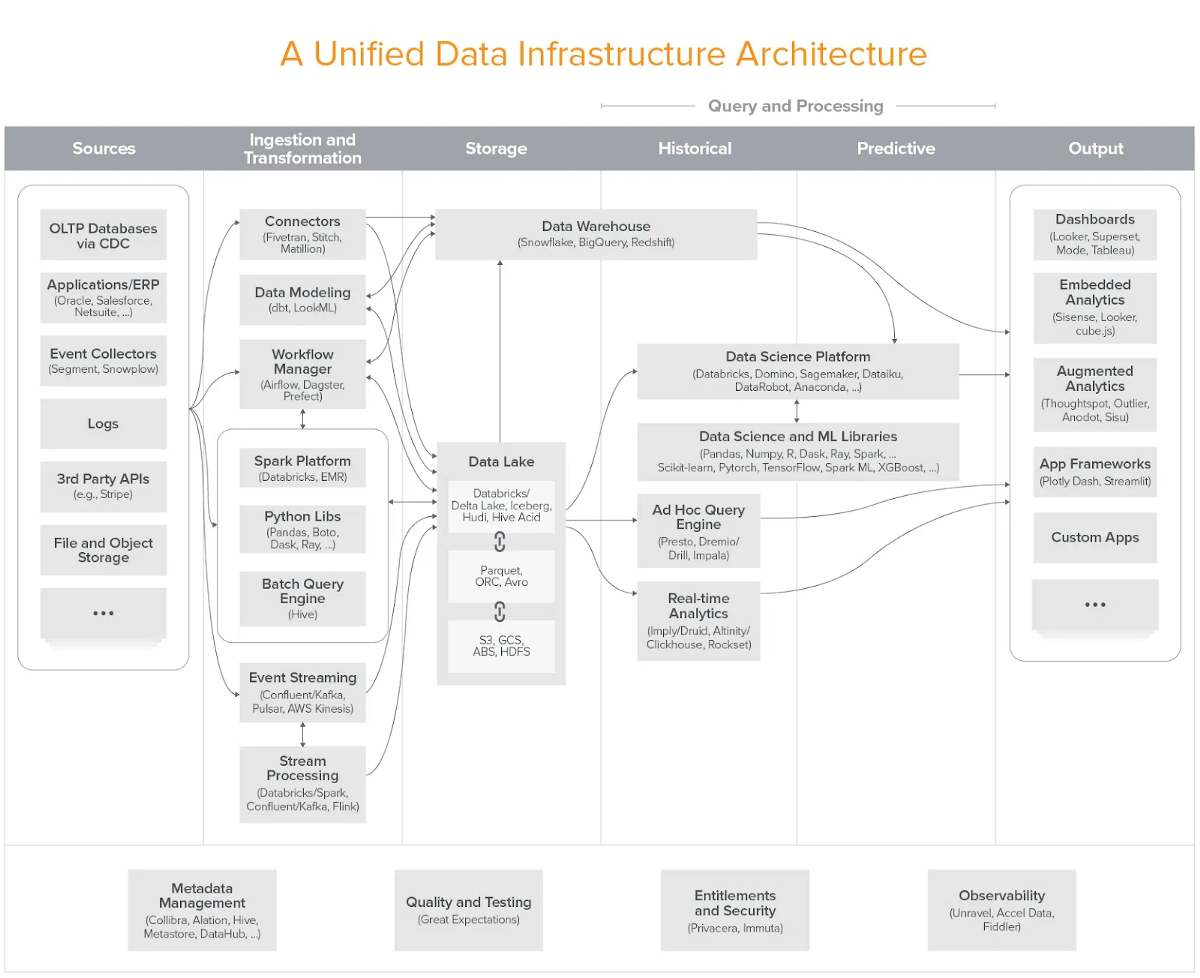
> Image courtesy of a16z
我們仍然在朝著現代統一數據基礎設施的明確架構之旅中相對較早,但有些特點是明顯結晶的。atomico是指這是“新數據層”。他們將這種新數據層視為現代企業的大班次,潛在的大幅度超過“代碼”,在未來十年內創建了幾個數十億美元的類別。
在這個新的波浪層中,它是數據(而不是代碼)及其驅動系統輸出和性能的工作流程。因此,最大化數據的洞察力和價值正在成為現代企業的主要焦點,呼吁底層數據基礎架構(或層)和工具的演變。為混合添加額外的風味,數據所有權正在變得越來越不清楚,因為團隊正在向數據網格移動(分布式數據所有權)。
4. 現代數據云(倉庫VS Data Lake VS Lakehouse)的戰斗為真實升溫
二十年前,數據倉庫可能不會是最性感的話題,嗯,任何時候都是真的。但是,Dataops的目前崛起,跨職能數據團隊,最重要的是:云已經制作了“云數據倉庫”鎮上的談話,概念與創新誘惑積極地融化。
作為一個具體的例子,關于Hadoop在2021年的有趣的事情是,雖然節省成本和分析性能是它在動蕩的2010年中回歸最具吸引力的益處,但Spark著迅速擺脫了這兩個功能,因為大多數財富500個公司(最后)離開了Hadoop。云使數據更容易管理,更廣泛的用戶更易于訪問,更快地處理。在2021年,純粹的數據量使得公司無法以有意義的方式使用數據,而無需利用一些云數據倉庫解決方案。隨著2012年亞馬遜Redshift的發布,其次是Snowflake,谷歌Big Query等隨后幾年,市場已經加熱了。
Snowflake帶來了與數據湖(原始數據)合并了數據倉庫(轉換數據)的推動,但現在建立的Lakehouse的出現挑戰(由Databricks’delta Lake的開創),其中包括在哪里和如何存儲(和轉換)數據已變得更復雜。 (基本上,兩者之間的差異是Snowflake建立在數據倉庫邏輯上,但云中的存儲成本的解耦和計算成本呈現出加載原始數據的激烈,因此他們添加了轉換功能。Databricks,另一個,已將數據倉庫功能添加到數據湖中,頂部有一個開源事務元數據層,可以在數據的選擇部分上進行轉換和操作,而大多數則保存在低成本對象存儲中。)
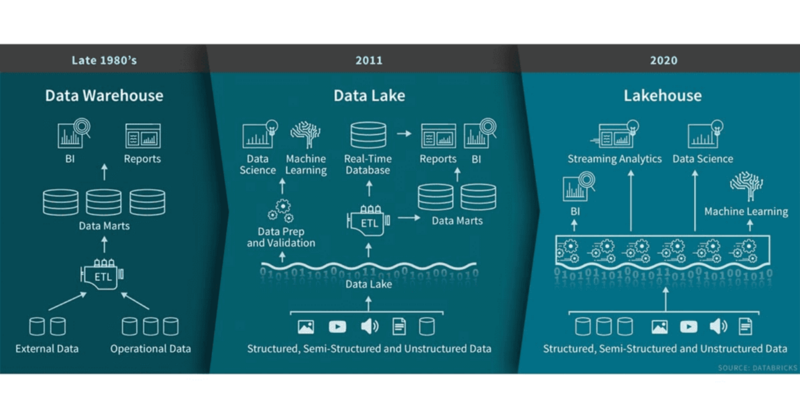
> Image courtesy of Databricks
雖然傳統上,數據倉庫經常對其主要用例用于數據分析和報告的數據平臺進行了定義,而數據湖泊有服務更多的ML定向/預測分析用例,則兩種型號正在收斂。隨后,我們正在看到一個有趣的數據平臺戰斗的開始,在接下來的5到10年內發揮作用:誰將設定最終數據云的標準?雪花將保持其位置作為靈活和高效的存儲的先驅,是否會成為另一個云數據倉庫(如AWS Redshift或Google Buequery)為他們提供了持續的錢,或者將達到7美元的資金注入(例如S3,主要的云玩家)轉換游戲領域?放下你的賭注并彈出你的爆米花,因為這將是一個好看的大戲!
5. 數據工程師的崛起
最后但并非最不重要的是,我們在2020年期間看到了數據工程師角色的迅速崛起。希望在閱讀這篇文章后,它應該在讀到這篇文章后毫不奇怪,其中86%的企業計劃在接下來的12個月內增加他們的Dataops投資,而且數據工程師現在是技術最快的工作。然而,這是一個如此接近我們的心靈,我們認為它應該得到自己的博文。
敬請關注!
原文鏈接:
https://medium.com/validio/ml-data-trends-wrapping-up-2020-and-looking-into-2021-beyond-b3ff1eadc211