













繼臉書開源PyTorch3D后,谷歌開源3D場景理解庫
3D 計算機視覺是一個非常重要的研究課題,選擇合適的計算框架對處理效果將會產生很大的影響。此前,機器之心曾介紹過 Facebook 開源的基于 PyTorch 框架的 3D 計算機視覺處理庫 PyTorch3D,該庫在 3D 建模、渲染等多方面處理操作上表現出了更好的效果。
最近,另一個常用的深度學習框架 TensorFlow 也有了自己的高度模塊化和高效處理庫。它就是谷歌 AI 推出的 TensorFlow 3D(TF 3D),將 3D 深度學習能力引入到了 TensorFlow 框架中。TF 3D 庫基于 TensorFlow 2 和 Keras 構建,使得更易于構建、訓練和部署 3D 語義分割、3D 實例分割和 3D 目標檢測模型。目前,TF 3D 庫已經開源。

GitHub 項目地址:
https://github.com/google-research/google-research/tree/master/tf3d
TF 3D 提供了一系列流行的運算、損失函數、數據處理工具、模型和指標,使得更廣泛的研究社區方便地開發、訓練和部署 SOTA 3D 場景理解模型。TF 3D 還包含用于 SOTA 3D 語義分割、3D 目標檢測和 3D 實例分割的訓練和評估 pipeline,并支持分布式訓練。該庫還支持 3D 物體形狀預測、點云配準和點云加密等潛在應用。
此外,TF 3D 提供了用于訓練和評估標準 3D 場景理解數據集的統一數據集規劃和配置,目前支持 Waymo Open、ScanNet 和 Rio 三個數據集。不過,用戶可以自由地將 NuScenes 和 Kitti 等其他流行數據集轉化為類似格式,并在預先存在或自定義創建的 pipeline 中使用它們。最后,用戶可以將 TF 3D 用于多種 3D 深度學習研究和應用,比如快速原型設計以及嘗試新思路來部署實時推理系統。
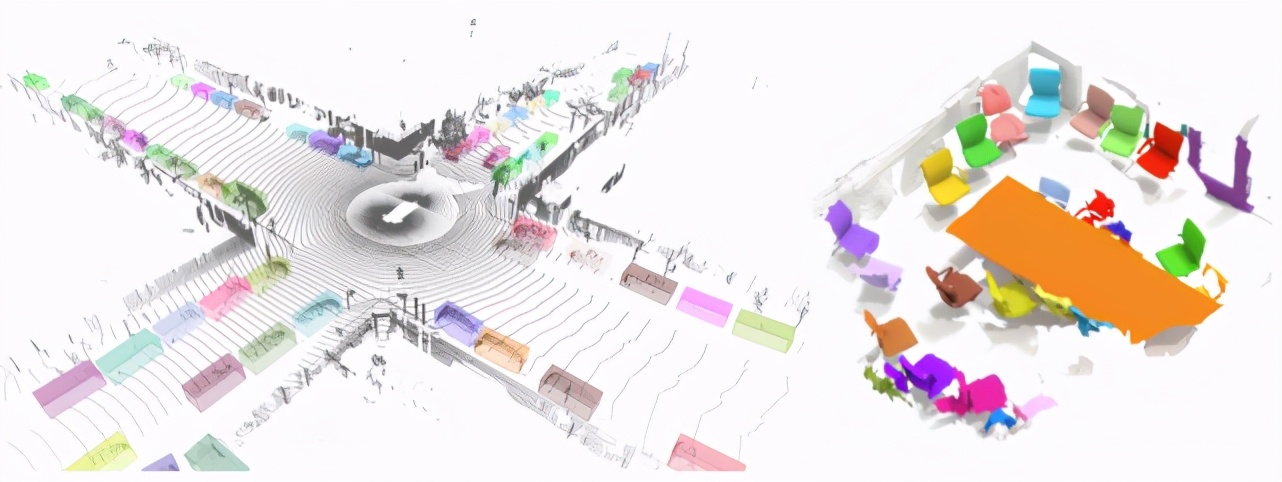
下圖(左)為 TF 3D 庫中 3D 目標檢測模型在 Waymo Open 數據集幀上的輸出示例;下圖(右)為 TF 3D 庫中 3D 實例分割模型在 ScanNet 數據集場景上的輸出示例。
3D 稀疏卷積網絡
谷歌詳細介紹了 TF 3D 庫中提供的高效和可配置稀疏卷積骨干網絡,該網絡是在各種 3D 場景理解任務上取得 SOTA 結果的關鍵。
在 TF 3D 庫中,谷歌使用子流形稀疏卷積和池化操作,這兩者被設計用于更高效地處理 3D 稀疏數據。稀疏卷積模型是大多數戶外自動駕駛(如 Waymo 和 NuScenes)和室內基準(如 ScanNet)中使用的 SOTA 方法的核心。
谷歌還使用各種 CUDA 技術來加速計算(如哈希算法、共享內存中分割 / 緩存濾波器以及位操作)。在 Waymo Open 數據集上的實驗表明,這種實現的速度約是利用預先存在 TensorFlow 操作的實現的 20 倍。
TF 3D 庫中使用 3D 子流形稀疏 U-Net 架構來提取每個體素(voxel)的特征。通過令網絡提取稀疏和細微特征并結合它們以做出預測,U-Net 架構已被證實非常有效。在結構上,U-Net 網絡包含三個模塊:編碼器、瓶頸層和解碼器,它們均是由大量具有潛在池化或非池化操作的稀疏卷積塊組成的。
下圖為 3D 稀疏體素 U-Net 架構:
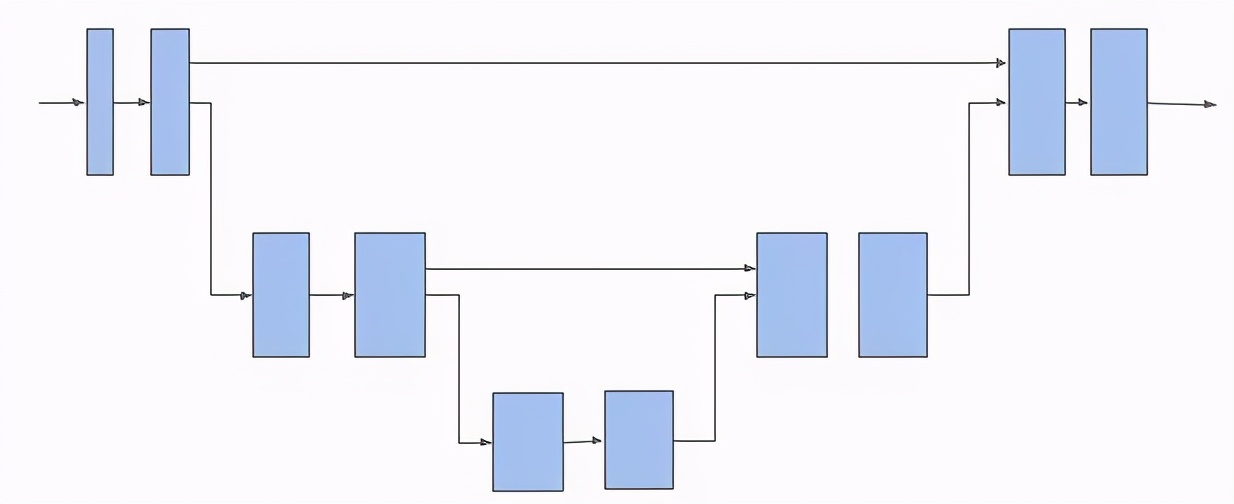
稀疏卷積網絡是 TF 3D 中所提供 3D 場景理解 pipeline 的骨干。并且,3D 語義分割、3D 實例分割和 3D 目標檢測模型使用稀疏卷積網絡來提取稀疏體素的特征,然后添加一個或多個額外的預測頭(head)來推理感興趣的任務。用戶可以通過改變編碼器或解碼器層數和每個層的卷積數,以及調整卷積濾波器大小來配置 U-Net 網絡,從而探索不同骨干網絡配置下各種速度或準確率的權衡。
TF 3D 支持的三個 pipeline
目前,TF 3D 支持三個 pipeline,分別是 3D 語義分割、3D 實例分割和 3D 目標檢測。
3D 語義分割
3D 語義分割模型僅有一個用于預測每體素(per-voxel )語義分數的輸出頭,這些語義被映射回點以預測每點的語義標簽。
下圖為 ScanNet 數據集中室內場景的 3D 語義分割結果:

3D 實例分割
除了預測語義之外,3D 實例分割的另一目的是將屬于同一物體的體素集中分組在一起。TF 3D 中使用的 3D 實例分割算法基于谷歌之前基于深度度量學習的 2D 圖像分割。模型預測每體素的實例嵌入向量和每體素的語義分數。實例嵌入向量將這些體素嵌入至一個嵌入空間,在此空間中,屬于同一物體實例的體素緊密靠攏,而屬于不同物體的體素彼此遠離。在這種情況下,輸入的是點云而不是圖像,并且使用了 3D 稀疏網絡而不是 2D 圖像網絡。在推理時,貪婪算法每次選擇一個實例種子,并利用體素嵌入之間的距離將它們分組為片段。
3D 目標檢測
3D 目標檢測模型預測每體素大小、中心、旋轉矩陣和目標語義分數。在推理時使用 box proposal 機制,將成千上萬個每體素 box 預測縮減為數個準確的 box 建議;在訓練時將 box 預測和分類損失應用于每體素預測。
谷歌在預測和真值 box 角(box corner)之間的距離上應用到了 Huber 損失。由于 Huer 函數根據 box 大小、中心和旋轉矩陣來估計 box 角并且它是可微的,因此該函數將自動傳回這些預測的目標特性。此外,谷歌使用了一個動態的 box 分類損失,它將與真值強烈重疊的 box 分類為正(positive),將與真值不重疊的 box 分類為負(negative)。
下圖為 ScanNet 數據集上的 3D 目標檢測結果:






















