













單張圖像探索3D奇境:Wonderland讓高質量3D場景生成更高效
本文的主要作者來自多倫多大學、Snap Inc.和UCLA的研究團隊。第一作者為多倫多大學博士生梁漢文和Snap Inc.的曹軍力,他們專注于視頻生成以及3D/4D場景生成與重建的研究,致力于創造更加真實、高質量的3D和4D場景。團隊成員期待與更多志同道合的研究者們交流與合作。
在人類的認知中,從單張圖像中感知并想象三維世界是一項天然的能力。我們能直觀地估算距離、形狀,猜想被遮擋區域的幾何信息。然而,將這一復雜的認知過程賦予機器卻充滿挑戰。最近,來自多倫多大學、Snap Inc. 和 UCLA 的研究團隊推出了全新的模型 ——Wonderland,它能夠從單張圖像生成高質量、廣范圍的 3D 場景,在單視圖 3D 場景生成領域取得了突破性進展。

- 論文地址: https://arxiv.org/abs/2412.12091
- 項目主頁:https://snap-research.github.io/wonderland/

技術突破:從單張圖像到三維世界的關鍵創新
傳統的 3D 重建技術往往依賴于多視角數據或逐個場景 (per-scene) 的優化,且在處理背景和不可見區域時容易失真。為解決這些問題,Wonderland 創新性地結合視頻生成模型和大規模 3D 重建模型,實現了高效高質量的大規模 3D 場景生成:
- 向視頻擴散模型中嵌入 3D 意識:通過向視頻擴散模型中引入相機位姿控制,Wonderland 在視頻 latent 空間中嵌入了場景的多視角信息,并能保證 3D 一致性。視頻生成模型在相機運動軌跡的精準控制下,將單張圖像擴展為包含豐富空間關系的多視角視頻。
- 雙分支相機控制機制:利用 ControlNet 和 LoRA 模塊,Wonderland 實現了在視頻生成過程中對于豐富的相機視角變化的精確控制,顯著提升了多視角生成的視頻質量、幾何一致性和靜態特征。
- 大規模 latent-based 3D 重建模型(LaLRM):Wonderland 創新地引入了 3D 重建模型 LaLRM,利用視頻生成模型生成的 latent 直接重構 3D 場景(feed-forward reconstruction)。重建模型的訓練采用了高效的逐步訓練策略,將視頻 latent 空間中的信息轉化為 3D 高斯點分布(3D Gaussian Splatting, 3DGS),顯著降低了內存需求和重建時間成本。憑借這種設計,LaLRM 能夠有效地將生成和重建任務對齊,同時在圖像空間與三維空間之間建立了橋梁,實現了更加高效且一致的廣闊 3D 場景構建。
效果展示 — 視頻生成
基于單張圖和 camera condition,實現視頻生成的精準視角控制:



Camera-guided 視頻生成模型可以精確地遵循軌跡的條件,生成 3D-geometry 一致的高質量視頻,并具有很強的泛化性,可以遵循各種復雜的軌跡,并適用于各種風格的輸入圖片。
更多的例子:
不同的輸入圖片,同樣的三條相機軌跡,生成的視頻:




給定輸入圖片和多條相機軌跡,生成視頻可以深度地探索場景:




效果展示 —3D 場景生成
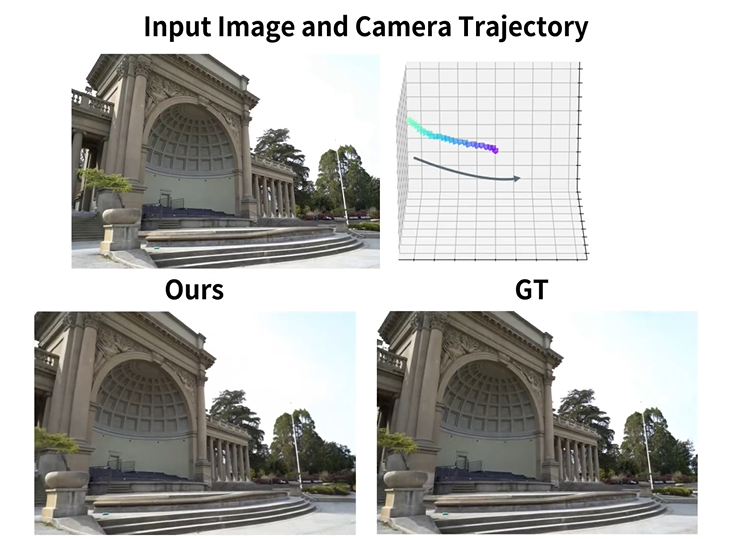
基于單張圖,利用 LaLRM, Wonderland 可以生成高質量的、廣闊的 3D 場景:
(以下展示均為從建立的3DGS Rendering出的結果)




基于單張圖和多條相機軌跡,Wonderland 可以深度探索和生成高質量的、廣闊的 3D 場景:
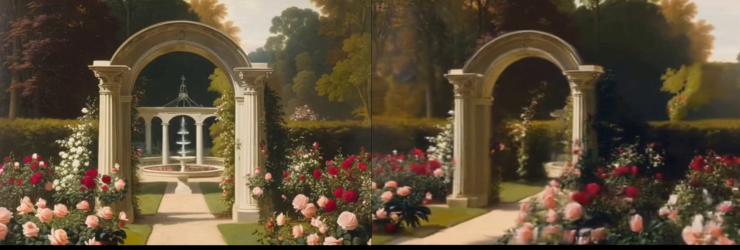



卓越性能:在視覺質量和生成效率等多個維度上表現卓越
Wonderland 的主要特點在于其精確的視角控制、卓越的場景生成質量、生成的高效性和廣泛的適用性。實驗結果顯示,該模型在多個數據集上的表現超越現有方法,包括視頻生成的視角控制、視頻生成的視覺質量、3D 重建的幾何一致性和渲染的圖像質量、以及端到端的生成速度均取得了優異的表現:
- 雙分支相機條件策略:通過引入雙分支相機條件控制策略,視頻擴散模型能夠生成 3D-geometry 一致的多視圖場景捕捉,且相較于現有方法達到了更精確的姿態控制。
- Zero-shot 3D 場景生成:在單圖像輸入的前提下,Wonderland 可進行高效的 3D 場景前向重建,在多個基準數據集(例如 RealEstate10K、DL3DV 和 Tanks-and-Temples)上的 3D 場景重建質量均優于現有方法。
- 廣覆蓋場景生成能力:與過去的 3D 前向重建通常受限于小視角范圍或者物體級別的重建不同,Wonderland 能夠高效生成廣范圍的復雜場景。其生成的 3D 場景不僅具備高度的幾何一致性,還具有很強的泛化性,能處理 out-of-domain 的場景。
- 超高效率:在單張圖像輸入的問題設定下,利用單張 A100,Wonderland 僅需約 5 分鐘即可生成完整的 3D 場景。這一速度相比需要 16 分鐘的 Cat3D 提升了 3.2 倍,相較需要 3 小時的 ZeroNVS 更是提升了 36 倍。
應用場景:視頻和 3D 場景內容創作的新工具
Wonderland 的出現為視頻和 3D 場景的創作提供了一種嶄新的解決方案。在建筑設計、虛擬現實、影視特效以及游戲開發等領域,該技術展現了廣闊的應用潛力。通過其精準的視頻位姿控制和具備廣視角、高清晰度的 3D 場景生成能力,Wonderland 能夠滿足復雜場景中對高質量內容的需求,為創作者帶來更多可能性。
未來展望
盡管模型表現優異,Wonderland 研發團隊深知仍有許多值得提升和探索的方向。例如,進一步優化對動態場景的適配能力、提升對真實場景細節的還原度等,都是未來努力的重點。希望通過不斷改進和完善,讓這一研發思路不僅推動單視圖 3D 場景生成技術的進步,也能為視頻生成與 3D 技術在實際應用中的廣泛普及貢獻力量。


























