













火爆老照片動起來、唱歌,微視把AI視頻特效打包「一鍵」實現了
從論文到手機,這個團隊正在「一鍵實現」越來越多的好玩特效。
這幾年,AI 模型在特效方向的技能似乎已被拉滿。因此,我們在有生之年見到了會說話的蒙娜麗莎、cos 油畫的周杰倫以及可以讓人一秒變禿的「東升發型生成器」。但是,這些技術似乎在使用層面都不太「接地氣」,很少有人將其做成「一鍵生成」類應用放到手機上,實時類應用就更少了。
到了 2021 年,這種局面正在發生變化。
在一款短視頻應用上,我們驚喜地看到,最近火遍全網的「深度懷舊」、「照片唱歌」都已經可以一鍵生成了:

這些特效都來自騰訊微視,用戶只需要下載微視 APP,上傳一張照片就可以得到想要的特效效果。其中,「會動的老照片」可以完成老照片上色、超分辨率、讓照片中的人物動起來等效果;而「讓照片唱首歌」可以讓任意照片中的人演唱一首曲目,還搭配豐富的面部表情。
不過,這還只是微視實現的眾多特效之一,還有更多特效可以在微視 APP 實時體驗,如變明星、變歐美、變娃娃等。

此外,你還可以通過手機實時控制生成圖像的面部動作,實現人臉動作遷移:
這些實時特效就像一面又一面的「魔鏡」,可以實現各種奇妙的人臉魔法特效。而且玩法非常簡單,只需要在 APP 中找到相應模板,然后打開攝像頭拍攝即可。
也許有人會問:論文都出來那么久了,怎么現在才在手機上看到這些效果?這就不得不提把 AI 模型從論文搬上手機的那些難處了。
把特效搬上手機難在哪兒?
我們知道,近年來興起的很多 AI 特效都是基于 GAN(生成對抗網絡)的,上文中的大部分特效也不例外。但是,傳統的 GAN 往往存在以下問題:
1.需要大量的訓練數據。數據對 AI 模型的重要性不言而喻,但對于一些基于 GAN 的人臉特效來說,模型不光需要數據,還需要大量的成對數據,這給數據采集工作帶來了新的挑戰。比如,在變換人種的特效中,我們不可能同時擁有一個人作為不同人種的圖片。
2.可控性差。我們在應用 GAN 生成人臉的時候可能會希望單獨調整某個屬性,其他屬性保持不變,如只把眼睛放大。但麻煩的是,圖像的信息被壓縮在一個維度很小的隱向量空間中,各個屬性耦合十分緊密。因此,如何實現這些屬性的解耦、提高人臉屬性的可控性就成了一個難題。
3.生成質量不穩定。由于輸入數據的質量和生成模型本身的不穩定性,GAN 模型生成的圖像畫質可能較低,因此我們還需要采取其他措施來提高生成圖像的質量。
4.計算量大,難以部署在移動端。一個擁有強大生成能力的 GAN 可能計算量要達到上百 G,不適合在移動端部署。因此,如何在不明顯損失視覺效果的前提下實現模型的高效壓縮成了一個亟待解決的問題。
這些挑戰如何克服?
針對上述挑戰,騰訊微視的技術團隊研發出了一套支持移動端實時特效的 GAN 模型訓練和部署框架,整體流程可以概括為以下幾個步驟:
按需求采集非成對數據,并訓練高參數量的模型生成成對數據;
對成對數據進行畫質增強;
利用成對數據訓練移動端輕量化模型。
借助這些步驟,模型不需要真實的成對數據也能達到預期的效果,可控性、生成圖像的質量都得到了顯著提升,還適配各種機型,讓更多人用上了簡單、高質量的人臉魔法特效。
利用高參數量模型生成成對數據
當成對的數據難以獲得,利用高參數量的大模型生成成對數據就成了一個必然選擇。生成效果如下圖:

為了完成這項任務,微視的技術團隊研發了三種不同的大模型。
第一種是融合了CycleGAN 和 StyleGAN 的 Cycle-StyleGAN。StyleGAN 擁有強大的高清人臉生成能力,但它是非條件生成模型,只能通過隨機向量生成隨機人臉。因此,研究人員引入了 CycleGAN 的思想,使模型具備 image-to-image 的條件生成能力。
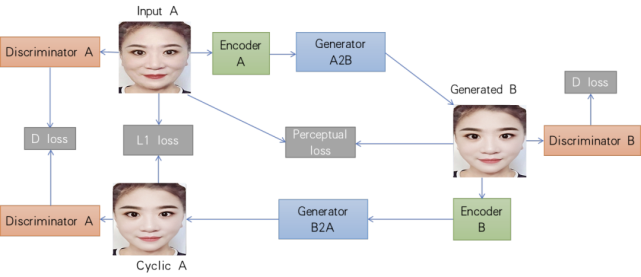
Cycle-StyleGAN 的基本結構。
借助這一模型設計,微視研發并上線了變年輕的效果:

但這一模型也有缺點:需要的數據量太大,而且穩定性、可控性都不強。因此,微視又研發了第二種大模型:基于隱向量的屬性編輯模型。
首先,他們利用亞洲人臉數據集訓練了一個高質量的生成模型。該模型通過 AdaIN 模塊來提取隱向量的信息,然后利用 Decoder 網絡來生成數據。為了解決數據解耦問題,實現單屬性可控(如只調節眼睛大小),團隊做出了以下優化:
對方向向量進行解耦,摸索出了一套有效的屬性解耦方法;
在訓練的過程中,通過監督信息控制隱向量的具體意義,比如限定某些維度控制鼻型,某些維度控制臉型。
通過以上操作,團隊實現了對大部分屬性的單獨控制,但眼袋、魚尾紋等過于細致的屬性依舊無法做到干凈的解耦。為此,團隊開發出了一套基于風格空間的屬性編輯方法。此外,團隊還針對真實數據與訓練數據之間的差異所導致的模糊、噪聲等問題進行了優化。
整體來看,第二代大模型不僅提高了模型可控性,還大大減少了數據需求量,可以在只能收集到少量非成對數據的真實人臉生成場景中使用。基于這套方案,微視研發并上線了變明星和變假笑等效果。

然而,現實中的人臉特效需求并不局限于真實人臉,還有一些風格化的需求需要滿足,如 CG 人臉生成。這類任務的數據匱乏程度更為嚴重,因此需要一種數據量需求更小的模型。為此,微視的團隊設計了第三種大模型——基于小樣本的模型融合模型。這種模型的主要思想是:在收集的少量數據上對預訓練的真實人臉模型進行調優訓練,使預訓練模型能夠較好地生成目標風格的圖片(如 CG 風格圖)。然后,將調優訓練后的模型與原始模型進行融合得到一個混合模型,該模型既能生成目標風格的圖片,又兼具原始預訓練模型強大多樣的生成能力。

CG 效果圖。
為了增加數據的多樣性,研發人員還給該模型加了一個數據增強模塊,借助 3D 人臉等技術生成更加多樣的數據。借助這一模型,只需要幾十張數據就能生成符合要求的人臉。
成對數據畫質增強
在迭代了三種大模型之后,小模型訓練所需的成對數據已經基本就緒,但還需要在美觀程度、穩定性和清晰度等方面進行優化。在美觀程度方面,微視利用圖像處理技術和屬性編輯方案對大模型生成的圖片進行美化,如利用去皺紋模型去除眼袋和淚溝。在穩定性和清晰度方面,微視參考圖像修復和超分辨率的相關方法單獨訓練了一個既能提升清晰度又能消除人臉瑕疵的 GAN 模型。隨機調研的結果顯示,用戶對美化后的圖片的喜愛程度明顯提高。

去眼袋和淚溝效果示意圖。
移動端小模型訓練
在手機上部署的特效對算法的實時性、穩定性要求都很高,因此微視的團隊設計了能在移動端流暢運行的小模型結構,把大模型生成的成對數據作為小模型訓練的監督信息進行訓練和蒸餾。
輕量級的小模型整體骨干基于 Unet 結構,參考了 MobileNet 深度可分離卷積和 ShuffleNet 的特征重利用等優點。為了提高生成圖像的清晰度和整體質量,研究團隊不僅將整張圖放進判別器進行訓練,還根據人臉點位裁剪出眼、眉、鼻、嘴,并將其分別輸入到判別器進行訓練。
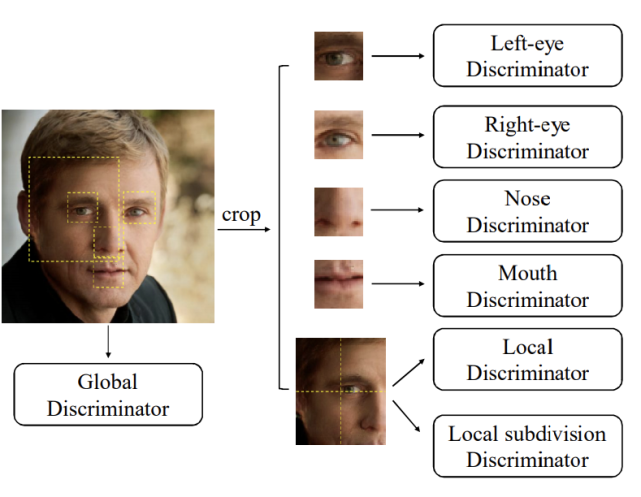
為了適配不同機型,團隊設計了多種計算量的模型。而且,考慮到低端機部署的模型參數量較少,他們還用到了知識蒸餾的方法讓 student 小模型學習到更多的信息。
以上三大步驟幫助微視實現了 image-to-image 的實時特效生成效果,但團隊并沒有止步于此,他們還實現了實時的輕量化人臉動作遷移。
實時人臉動作遷移
在人臉動作遷移方向,有一部分工作的思路是:首先估計從目標圖片到源圖片的反向光流,基于光流對源圖片的特征表示進行扭曲(warping)操作,然后再恢復出重建結果,例如 Monkey-Net、FOMM 等。微視的實時人臉動作遷移大模型就借鑒了此類方法。
為了實現手機端實時推斷,他們在模型大小和計算量兩個方面對大模型進行了優化,借鑒 GhostNet 分別設計了相應的小模型結構,從而將模型大小縮減了 99.2%,GFLOPs 降低了 97.7%。為了讓小模型成功學到大模型的能力,他們還采用了分階段蒸餾訓練的策略。
訓練完小模型之后,團隊借助騰訊自己研發的移動端深度學習推理框架 TNN實現了手機端的部署和實時推理,從而使得用戶通過攝像頭驅動任意人臉圖片的玩法變為可能。
做特效,騰訊微視優勢在哪兒
逼真的效果、高效的模型離不開堅實的技術支撐。這些項目的核心技術由騰訊微視拍攝算法團隊與騰訊平臺與內容事業群(PCG)應用研究中心(Applied Research Center,ARC)共同研發。騰訊微視拍攝算法團隊致力于圖像 / 視頻方向的技術探索,匯聚了一批行業內頂尖的算法專家和產品經驗豐富的研究員和工程師,擁有豐富的業務場景,持續探索前沿 AI 和 CV 算法在內容生產和消費領域的應用和落地。ARC 則是 PCG 的偵察兵和特種兵,主要任務是探索和挑戰智能媒體相關的前沿技術,聚焦于音視頻內容的生成、增強、檢索和理解等方向。
在 AI 特效落地方面,團隊建立了以下優勢:
已經搭建了從算法研發、模型迭代到線上部署的一整套流程化框架,可以實現各項技術的快速落地,為探索更多特效提供了效率保證;
算法經過了多次迭代,數據需求量已經降至很低的水平,幾十張圖像就能實現不錯的效果,使得更多特效的實現成為可能;
在圖像質量提升、模型壓縮等方面積累了一些自己的技術,可以保障 AI 模型在各種移動端平臺上成功部署。
除了上面討論的 GAN 之外,研發團隊在增強現實、3D 空間理解等方面也做了一些探索,并在微視 APP 上上線了一批特效,這也是當前整個社區比較熱門的研究方向。
隨著技術的不斷迭代,未來,我們還將在微視上看到更多原本只能在論文中看到的驚艷效果。


















