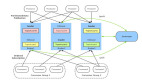
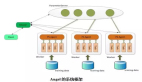
分布式機器學習系統:設計原理、優化策略與實踐經驗
人工智能領域正在經歷一場深刻的變革。隨著深度學習模型的規模呈指數級增長,我們正面臨著前所未有的計算挑戰。當前最先進的語言模型動輒包含數千億個參數,這種規模的模型訓練已經遠遠超出了單機系統的處理能力。在這個背景下,分布式機器學習系統已經成為支撐現代人工智能發展的關鍵基礎設施。

分布式機器學習的演進
在深度學習早期,研究人員通常使用單個GPU就能完成模型訓練。隨著研究的深入,模型架構變得越來越復雜,參數量急劇增長。這種增長首先突破了單GPU的內存限制,迫使研究人員開始探索模型并行等技術。僅僅解決內存問題是不夠的。訓練時間的持續增長很快成為另一個瓶頸,這促使了數據并行訓練方案的發展。
現代深度學習面臨的挑戰更為嚴峻。數據規模已經從最初的幾個GB擴展到TB甚至PB級別,模型參數量更是達到了數千億的規模。在這種情況下,即使采用最基礎的分布式訓練方案也無法滿足需求。我們需要一個全方位的分布式訓練系統,它不僅要解決計算和存儲的問題,還要處理數據管理、通信優化、容錯機制等多個層面的挑戰。
分布式訓練的核心問題
在構建分布式訓練系統時,面臨著幾個根本性的挑戰。首先是通信開銷問題。在傳統的數據并行訓練中,每個計算節點都需要頻繁地同步模型參數和梯度。隨著節點數量的增加,通信開銷會迅速成為系統的主要瓶頸。這要求我們必須采用各種優化技術,如梯度壓縮、通信計算重疊等,來提高通信效率。
同步策略的選擇是另一個關鍵問題。同步SGD雖然能保證訓練的確定性,但可能因為節點間的速度差異導致整體訓練速度受限于最慢的節點。而異步SGD雖然能提高系統吞吐量,但可能引入梯度延遲,影響模型收斂。在實際系統中,常常需要在這兩種策略間尋找平衡點。
內存管理也同樣至關重要。現代深度學習模型的參數量和中間激活值大小已經遠超單個設備的內存容量。這要求我們必須精心設計參數分布策略,合理規劃計算和存儲資源。近年來興起的ZeRO優化技術就是解決這一問題的典型方案,它通過對優化器狀態、梯度和模型參數進行分片,顯著降低了每個設備的內存需求。
分布式訓練的基本范式
分布式訓練最基本的范式是數據并行。這種方式的核心思想是將訓練數據分散到多個計算節點,每個節點維護完整的模型副本,通過參數服務器或集合通信來同步梯度信息。數據并行的優勢在于實現簡單、擴展性好,但它要求每個節點都能存儲完整的模型參數。
當模型規模超過單個設備的內存容量時,需要轉向模型并行方案。模型并行的核心是將模型參數分布到多個設備上,每個設備只負責部分參數的計算和存儲。這種方式雖然能夠處理超大規模模型,但實現復雜度較高,且需要精心設計以平衡計算負載和減少設備間通信。
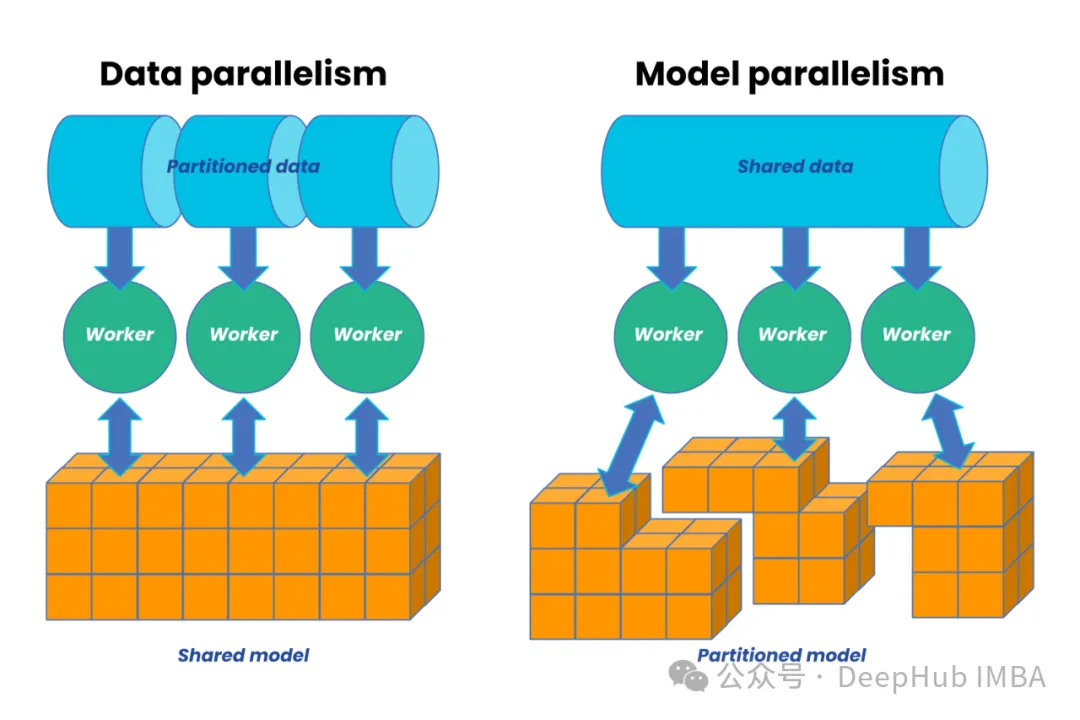
在實際應用中,往往需要將這些基本范式結合起來形成混合并行方案。例如可能在模型架構層面采用流水線并行,在參數層面使用張量并行,同時在外層使用數據并行。這種混合策略能夠更好地利用系統資源,但也帶來了更高的系統復雜度。
面向未來的系統設計
隨著人工智能技術的持續發展,分布式訓練系統還將面臨更多新的挑戰。模型規模的進一步增長、新型計算硬件的出現、對訓練效率的更高要求,這些都將推動分布式訓練系統向更復雜、更智能的方向發展。在這個過程中,如何在保持系統可用性的同時不斷提升性能和可擴展性,將是一個持續的挑戰。
接下來的章節中,我們將深入探討分布式訓練系統的各個核心組件,包括參數服務器的實現、訓練器的設計、數據加載優化等關鍵技術,以及在實際部署中的最佳實踐。通過這些內容希望能夠幫助讀者更好地理解和構建現代分布式機器學習系統。
參數服務器架構設計
參數服務器的基本原理
參數服務器(Parameter Server)是分布式機器學習系統中的核心組件,負責管理和同步模型參數。它采用中心化的參數存儲和更新機制,支持高效的分布式訓練。
關鍵特性
1.分片存儲
- 將模型參數分散存儲在多個服務器節點
- 支持動態擴展和容錯
- 通過一致性哈希等機制實現負載均衡
2.異步更新
- 支持非阻塞的參數更新操作
- 使用版本管理確保一致性
- 提供靈活的同步策略配置
3.通信優化
- 參數壓縮和稀疏更新
- 流水線化的通信機制
- 帶寬感知的調度策略
具體實現
以下是一個高效的分布式參數服務器實現:
class DistributedParameterServer:
def __init__(self, world_size: int, num_shards: int):
self.world_size = world_size
self.num_shards = num_shards
# 跨節點存儲的參數分片
self.parameter_shards = [
torch.zeros(shard_size, requires_grad=True)
for _ in range(num_shards)
]
# 無鎖更新緩沖區
self.update_buffers = {
shard_id: AsyncUpdateBuffer(buffer_size=1024)
for shard_id in range(num_shards)
}
# 初始化通信
self.initialize_communication()
def initialize_communication(self):
# 設置 NCCL 用于 GPU 通信
self.comm = ncclGetUniqueId()
torch.distributed.init_process_group(
backend='nccl',
init_method='env://',
world_size=self.world_size,
rank=dist.get_rank()
)
# 為異步操作創建 CUDA 流
self.streams = [
torch.cuda.Stream()
for _ in range(self.num_shards)
]核心功能解析
1.參數分片管理
- 通過parameter_shards實現參數的分布式存儲
- 每個分片獨立管理,支持并行訪問
- 使用PyTorch的自動微分機制追蹤梯度
2.異步更新機制
- AsyncUpdateBuffer實現高效的更新累積
- 使用無鎖數據結構最小化同步開銷
- 支持批量更新提高吞吐量
3.CUDA流管理
- 為每個分片創建獨立的CUDA流
- 實現計算和通信的重疊
- 提高GPU利用率
參數更新流程
async def apply_updates(self, shard_id: int, updates: torch.Tensor):
buffer = self.update_buffers[shard_id]
# 在緩沖區中排隊更新
buffer.push(updates)
# 如果緩沖區已滿則處理更新
if buffer.is_full():
with torch.cuda.stream(self.streams[shard_id]):
# 聚合更新
aggregated = buffer.aggregate()
# 將更新應用到參數
self.parameter_shards[shard_id].add_(
aggregated,
alpha=self.learning_rate
)
# 清空緩沖區
buffer.clear()
# 全局規約更新后的參數
torch.distributed.all_reduce(
self.parameter_shards[shard_id],
op=torch.distributed.ReduceOp.SUM,
async_op=True
)這個實現包含幾個關鍵優化:
1.批量處理
- 累積多個更新后一次性應用
- 減少通信次數
- 提高計算效率
2.異步操作
- 使用異步all-reduce操作
- 通過CUDA流實現并行處理
- 最小化同步等待時間
3.內存優化
- 及時清理更新緩沖區
- 使用就地更新減少內存分配
- 通過流水線化減少峰值內存使用
分布式訓練器設計與實現
訓練器架構
分布式訓練器是整個系統的核心組件,負責協調數據加載、前向傳播、反向傳播和參數更新等過程。一個高效的訓練器需要處理多個關鍵問題:
1.混合精度訓練
- 使用FP16減少顯存使用
- 維護FP32主權重保證數值穩定性
- 動態損失縮放預防梯度下溢
2.梯度累積
- 支持大批量訓練
- 減少通信開銷
- 提高內存效率
3.優化器集成
- 支持ZeRO優化器
- CPU卸載機制
- 通信優化策略
訓練器實現
以下是一個完整的分布式訓練器實現:
class DistributedTrainer:
def __init__(
self,
model: nn.Module,
optimizer: Type[torch.optim.Optimizer],
world_size: int,
gradient_accumulation_steps: int = 1
):
self.model = model
self.world_size = world_size
self.grad_accum_steps = gradient_accumulation_steps
# 封裝模型用于分布式訓練
self.model = DistributedDataParallel(
model,
device_ids=[local_rank],
output_device=local_rank,
find_unused_parameters=True
)
# 使用 ZeRO 優化初始化優化器
self.optimizer = ZeROOptimizer(
optimizer,
model,
overlap_comm=True,
cpu_offload=True
)
# 用于混合精度的梯度縮放器
self.scaler = GradScaler()
# 設置梯度分桶
self.grad_buckets = initialize_grad_buckets(
model,
bucket_size_mb=25
)訓練步驟實現
@torch.cuda.amp.autocast()
def train_step(
self,
batch: Dict[str, torch.Tensor]
) -> torch.Tensor:
# 前向傳播
outputs = self.model(**batch)
loss = outputs.loss
# 縮放損失用于梯度累積
scaled_loss = loss / self.grad_accum_steps
# 使用縮放后的損失進行反向傳播
self.scaler.scale(scaled_loss).backward()
return loss.detach()
def optimize_step(self):
# 等待所有梯度計算完成
torch.cuda.synchronize()
# 反縮放梯度
self.scaler.unscale_(self.optimizer)
# 裁剪梯度
torch.nn.utils.clip_grad_norm_(
self.model.parameters(),
max_norm=1.0
)
# 使用梯度分桶進行優化
for bucket in self.grad_buckets:
# 同步分桶梯度
bucket.synchronize()
# 應用更新
self.scaler.step(
self.optimizer,
bucket_idx=bucket.index
)
# 清空分桶梯度
bucket.zero_grad()
# 更新縮放器
self.scaler.update()訓練循環的實現需要考慮多個方面的優化:
1.評估策略
- 定期進行模型評估
- 支持分布式評估
- 維護最佳檢查點
2.狀態同步
- 確保所有節點狀態一致
- 處理訓練中斷和恢復
- 支持檢查點保存和加載
def train_epoch(
self,
dataloader: DataLoader,
epoch: int,
eval_steps: int
):
self.model.train()
step = 0
total_loss = 0
# 訓練循環
for batch in dataloader:
# 將批次數據移至 GPU
batch = {
k: v.to(self.device)
for k, v in batch.items()
}
# 計算損失
loss = self.train_step(batch)
total_loss += loss.item()
step += 1
# 累積步數后優化
if step % self.grad_accum_steps == 0:
self.optimize_step()
# 定期評估
if step % eval_steps == 0:
self.evaluate(step, epoch)
self.model.train()性能優化策略
1.計算優化
- 使用混合精度訓練
- 梯度累積減少通信
- 梯度分桶優化通信
2.內存優化
- ZeRO優化器減少內存使用
- CPU卸載機制
- 梯度檢查點技術
3.通信優化
- 使用NCCL后端
- 異步通信操作
- 通信計算重疊
分布式訓練系統的深入優化
混合精度訓練的實現細節
混合精度訓練是現代分布式訓練系統的重要組成部分。它不僅可以減少顯存使用,還能提高訓練速度。但實現高效穩定的混合精度訓練需要注意以下關鍵點:
動態損失縮放是確保FP16訓練穩定性的關鍵機制:
class DynamicLossScaler:
def __init__(self, init_scale=2**15, scale_factor=2, scale_window=2000):
self.cur_scale = init_scale
self.scale_factor = scale_factor
self.scale_window = scale_window
self.num_overflows = 0
self.num_steps = 0
def scale(self, loss):
return loss * self.cur_scale
def update_scale(self, overflow):
self.num_steps += 1
if overflow:
self.num_overflows += 1
if self.num_steps % self.scale_window == 0:
if self.num_overflows == 0:
self.cur_scale *= self.scale_factor
else:
self.cur_scale /= self.scale_factor
self.num_overflows = 0梯度累積的高級特性
梯度累積不僅用于處理顯存限制,還能提供額外的訓練優勢:
- 噪聲平滑:累積多個小批次的梯度可以降低梯度估計的方差
- 內存效率:通過分散計算減少峰值顯存使用
- 通信優化:減少參數同步頻率,降低通信開銷
class GradientAccumulator:
def __init__(self, model, accumulation_steps):
self.model = model
self.accumulation_steps = accumulation_steps
self.stored_gradients = {}
self._initialize_gradient_storage()
def _initialize_gradient_storage(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.stored_gradients[name] = torch.zeros_like(param)
def accumulate_gradients(self):
with torch.no_grad():
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None:
self.stored_gradients[name] += param.grad / self.accumulation_steps
param.grad = None
def apply_accumulated_gradients(self):
with torch.no_grad():
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.stored_gradients[name]
self.stored_gradients[name].zero_()ZeRO優化器的工作原理
ZeRO(Zero Redundancy Optimizer)通過三個階段的優化顯著減少顯存使用:
階段1:優化器狀態分片
優化器狀態(如Adam的動量和方差)在工作節點間進行分片:
class ZeROStage1Optimizer:
def __init__(self, optimizer, dp_process_group):
self.optimizer = optimizer
self.dp_process_group = dp_process_group
self.world_size = dist.get_world_size(dp_process_group)
self.rank = dist.get_rank(dp_process_group)
self._partition_optimizer_state()
def _partition_optimizer_state(self):
for group in self.optimizer.param_groups:
for p in group['params']:
if p.requires_grad:
state = self.optimizer.state[p]
# 將優化器狀態分片到不同節點
for k, v in state.items():
if torch.is_tensor(v):
partitioned = self._partition_tensor(v)
state[k] = partitioned
def _partition_tensor(self, tensor):
# 計算每個進程的分片大小
partition_size = tensor.numel() // self.world_size
start_idx = partition_size * self.rank
end_idx = start_idx + partition_size
return tensor.view(-1)[start_idx:end_idx]階段2:梯度分片
在階段1的基礎上添加梯度分片,進一步減少顯存使用:
def backward(self, loss):
loss.backward()
# 對梯度進行分片
for name, param in self.model.named_parameters():
if param.requires_grad:
# 僅保留本節點負責的梯度分片
grad_partition = self._partition_gradient(param.grad)
param.grad = grad_partition
def _partition_gradient(self, gradient):
partition_size = gradient.numel() // self.world_size
start_idx = partition_size * self.rank
end_idx = start_idx + partition_size
return gradient.view(-1)[start_idx:end_idx]階段3:參數分片
最后一個階段實現參數分片,實現最大程度的顯存節省:
def forward(self, *args, **kwargs):
# 在前向傳播前收集完整參數
self._gather_parameters()
output = self.module(*args, **kwargs)
# 釋放完整參數
self._release_parameters()
return output
def _gather_parameters(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
# 從所有節點收集完整參數
full_param = self._all_gather_parameter(param)
self.temp_params[name] = param.data
param.data = full_param
def _release_parameters(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
# 恢復到分片狀態
param.data = self.temp_params[name]高級訓練特性
為了處理超大模型,可以實現梯度檢查點機制:
class GradientCheckpointing:
def __init__(self, model, checkpoint_layers):
self.model = model
self.checkpoint_layers = checkpoint_layers
self.saved_activations = {}
def forward_with_checkpoint(self, x):
activations = []
for i, layer in enumerate(self.model.layers):
if i in self.checkpoint_layers:
# 保存輸入,釋放中間激活值
activations.append(x.detach())
x = layer(x)
else:
x = layer(x)
return x, activations通過這些深入的優化和實現細節,我們的分布式訓練系統可以更好地處理大規模模型訓練的挑戰。這些機制相互配合,共同提供了一個高效、可擴展的訓練框架。
高效的分布式數據加載系統
數據加載的重要性
在分布式機器學習系統中,數據加載往往成為制約訓練效率的關鍵瓶頸。隨著模型規模的增長,每個訓練步驟的計算時間相應增加,這要求數據加載系統能夠及時提供下一批次的訓練數據,避免GPU空等待。一個高效的數據加載系統需要解決以下核心問題:
1.數據分片與均衡
- 確保訓練數據均勻分布到各個節點
- 處理數據傾斜問題
- 支持動態負載調整
2.預取與緩存
- 實現異步數據預取
- 合理利用內存緩存
- 優化磁盤I/O性能
3.內存管理
- 控制內存使用峰值
- 實現高效的數據傳輸
- 優化CPU到GPU的數據移動
分布式數據加載器實現
以下是一個針對性能優化的分布式數據加載器實現:
class DistributedDataLoader:
def __init__(
self,
dataset: Dataset,
batch_size: int,
world_size: int,
rank: int,
num_workers: int = 4,
prefetch_factor: int = 2
):
# 跨節點分片數據集
self.sampler = DistributedSampler(
dataset,
num_replicas=world_size,
rank=rank,
shuffle=True
)
# 創建高效的數據加載器
self.dataloader = DataLoader(
dataset,
batch_size=batch_size,
sampler=self.sampler,
num_workers=num_workers,
pin_memory=True,
prefetch_factor=prefetch_factor,
persistent_workers=True
)
# 預取緩沖區
self.prefetch_queue = Queue(maxsize=prefetch_factor)
self.prefetch_stream = torch.cuda.Stream()
# 啟動預取工作進程
self.start_prefetch_workers()數據預取是提高訓練效率的關鍵機制。通過異步預取下一批次數據可以顯著減少GPU的等待時間:
def start_prefetch_workers(self):
def prefetch_worker():
while True:
# 獲取下一個批次
batch = next(self.dataloader.__iter__())
with torch.cuda.stream(self.prefetch_stream):
# 將批次數據移至 GPU
batch = {
k: v.pin_memory().to(
self.device,
non_blocking=True
)
for k, v in batch.items()
}
# 添加到隊列
self.prefetch_queue.put(batch)
# 啟動預取線程
self.prefetch_threads = [
threading.Thread(target=prefetch_worker)
for _ in range(2)
]
for thread in self.prefetch_threads:
thread.daemon = True
thread.start()數據加載優化策略
1.內存釘存(Pin Memory)
- 使用頁鎖定內存加速GPU傳輸
- 減少CPU到GPU的數據拷貝開銷
- 支持異步數據傳輸
2.持久化工作進程
- 避免頻繁創建銷毀工作進程
- 維持預熱的數據加載管道
- 提高數據加載穩定性
3.異步數據傳輸
- 利用CUDA流實現異步傳輸
- 通過預取隱藏數據加載延遲
- 優化CPU-GPU數據移動
性能優化與監控
在實際部署中,還需要考慮以下幾個關鍵方面:
1.性能指標監控
- 數據加載延遲
- GPU利用率
- 內存使用情況
- 磁盤I/O負載
2.自適應優化
- 動態調整預取深度
- 根據負載調整工作進程數
- 優化批次大小
3.故障處理
- 優雅處理數據加載異常
- 支持斷點續傳
- 實現自動重試機制
系統優化與最佳實踐
在深度學習領域,從實驗室原型到生產級系統的轉變往往充滿挑戰。一個高效的分布式訓練系統不僅需要正確的實現,更需要全方位的性能優化。這種優化是一個漸進的過程,需要從通信、計算、內存等多個維度進行系統性的改進。
通信系統的優化
在分布式訓練中,通信效率往往是決定系統性能的關鍵因素。當在數千個GPU上訓練模型時,如果沒有經過優化的通信機制,大量的時間都會浪費在參數同步上。為了解決這個問題,現代分布式訓練系統采用了一系列創新的通信優化技術。
梯度壓縮是最基礎的優化手段之一。通過對梯度進行量化或稀疍化處理,可以顯著減少需要傳輸的數據量。例如,8位量化可以將通信帶寬需求減少75%,而且在許多情況下對模型收斂幾乎沒有影響。更激進的壓縮方案,如深度梯度壓縮,甚至可以將梯度壓縮到原始大小的1%以下。
拓撲感知通信是另一個重要的優化方向。在大規模集群中,不同節點之間的網絡帶寬和延遲可能存在顯著差異。通過感知底層網絡拓撲,可以優化通信路由,最大化帶寬利用率。例如在有InfiniBand網絡的集群中,可以優先使用RDMA通信,并根據節點間的物理距離調整通信策略。
內存管理
隨著模型規模的增長,內存管理已經成為分布式訓練中最具挑戰性的問題之一。現代語言模型動輒需要數百GB的顯存,這遠超單個GPU的容量。因此,高效的內存管理策略變得至關重要。
顯存優化需要多管齊下。首先是通過梯度檢查點技術減少激活值存儲。在深度網絡中,激活值通常占用的顯存遠大于模型參數。通過戰略性地丟棄和重計算中間激活值,可以在適度增加計算量的情況下顯著減少顯存使用。
ZeRO優化器代表了當前最先進的內存優化技術。它通過對優化器狀態、梯度和模型參數進行分片,實現了接近線性的顯存減少。這種方法不僅降低了單個設備的內存壓力,還提供了出色的可擴展性。在實踐中合理配置ZeRO的不同階段對于獲得最佳性能至關重要。
訓練穩定性的保障
在追求性能的同時,維持訓練的穩定性同樣重要。分布式環境下的訓練過程面臨著更多的不確定性,需要采取額外的措施來確保可靠性。
混合精度訓練是現代分布式系統的標配,但它也帶來了數值穩定性的挑戰。動態損失縮放是解決這個問題的關鍵。通過自適應調整損失的縮放因子,可以在保持FP16訓練效率的同時,避免梯度下溢帶來的問題。
容錯機制是另一個不容忽視的方面。在大規模訓練中,硬件故障是不可避免的。設計良好的檢查點保存和恢復機制,以及優雅的故障處理流程,可以最大限度地減少故障帶來的影響。
性能調優的實踐智慧
性能調優是一個需要理論指導和實踐經驗相結合的過程。在實際工作中,我們發現一些關鍵的調優原則特別重要。首先是要建立可靠的性能度量基準。這包括訓練速度、GPU利用率、內存使用情況等多個指標。只有有了這些基準數據,才能客觀評估優化的效果。
系統配置的優化同樣重要。CUDA和通信庫的配置直接影響著系統性能。例如,啟用CUDA graph可以減少啟動開銷,而正確的NCCL配置則能顯著提升多GPU通信效率。這些配置需要根據具體的硬件環境和工作負載特點來調整。
# 設置CUDA環境
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = False進程間通信配置
# NCCL配置
os.environ['NCCL_DEBUG'] = 'INFO'
os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
os.environ['NCCL_IB_DISABLE'] = '0'訓練超參數的選擇也需要特別注意。在分布式環境下,批次大小的選擇不僅要考慮內存限制,還要考慮通信開銷和優化效果。學習率的調整更需要考慮分布式訓練的特點,通常需要隨著有效批次大小的變化進行相應的縮放。
總結
分布式機器學習系統仍在快速發展。隨著新型硬件的出現和算法的進步,我們預期會看到更多創新的優化技術。自適應訓練策略將變得越來越重要,系統能夠根據訓練狀態和資源利用情況動態調整參數。跨數據中心的訓練也將成為新的研究熱點,這將帶來新的通信優化和同步策略的需求。
展望未來,分布式訓練系統的發展方向將更加注重可擴展性和易用性的平衡。自動化的性能優化和故障處理機制將變得越來越普遍,使得研究人員能夠更專注于模型設計和算法創新。這個領域還有很多待解決的問題,但也正是這些挑戰讓分布式機器學習系統的研究充滿活力和機遇。