如何使用機器學習算法優化分發鏈路
原創【51CTO.com原創稿件】
一, 背景介紹---點播視頻源站分發的痛點
點播視頻觀看的流程與源站定義
點播,是相對于直播說的,英文命叫VOD (Video on Demand),顧名思義,某個觀眾demand了,才有video看,看到的內容是視頻的開始;
而直播呢,是不管有沒有觀眾去看的,視頻一直在往前走,某個觀眾進來時看到的,是當時的視頻。
點播視頻的內容非常多樣化,有連續劇、電影、體育錄像、自媒體制作的視頻,甚至包含(現在非常火爆的)短視頻。
大家有沒有想過,每次打開一個點播視頻的時候,背后的操作是什么樣子的呢?
? ?
?
簡單的一種觀點是圖上這樣:
- 視頻網站提供點播資源,比如說PPTV新上了一個連續劇,一個電影,或是短視頻網站新提供了一個新的短視頻
- 觀眾通過網頁、app等訪問網站,進行視頻的觀看
實際上,情況沒有這么簡單
視頻網站的提供的點播資源,也就是文件,是放在自己公司的服務器上面的,這個服務器可能是買的,也可能是租的,
存儲這些文件的服務器集群,就叫做源站
這些視頻文件,實際上不會直接給用戶訪問,而是通過cdn逐級分發出去的,所以這些存儲集群,還要負責對接CDN
所以源站的作用是負責存儲和對接CDN,這里有個分工,視頻網站擁有視頻版權,CDN擅長分發
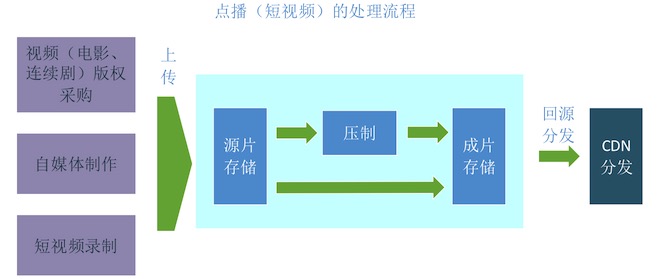
下面我們來看看點播、包括短視頻的視頻網站的處理流程,
? ?
?
流程如下:
- 內容生成(這一點是在視頻網站之外就可以做的)。視頻網站采購版權,或者是自媒體作者制作好視頻,短視頻作者在手機端錄制好視頻
- 把內容上傳到視頻網站的源片存儲。視頻網站的編輯上傳采購的版權視頻,自媒體和短視頻作者上傳自己制作的視頻
- 選擇是否壓制(根據特性)。視頻網站根據視頻的特性,選擇是否對視頻進行壓制處理, 例如短視頻一般不需要壓制即可在手機播放,而電影連續劇一般會壓制多檔碼率
- 成片存儲。壓制好(或不用壓制)的視頻,叫做成片,存儲起來
- 回源。CDN從成片存儲回源下載這些視頻,給觀眾看
源站與CDN的網絡拓撲
我們知道有以下事實:
- 一個視頻網站的(成片)視頻,一般不會只放在一個機房內.如PPTV的視頻,體育類的會放在上海的機房,原因是體育演播室在上海,本地錄制方便且無需互聯網帶寬;影視類的都放在武漢的機房,原因是編輯中心在武漢。
- 一個視頻網站會對接多個CDN,也可能自己建設CDN。如PPTV,在自己CDN的基礎上,和國內外各大知名CDN廠商都有深度的合作
- 每個CDN(包括自建)供應商對應的網絡接入點位置,質量都有很多區別
另外,對于視頻網站來說,一個視頻文件,只用保存一兩份(當然,視頻公司會做冷熱備份等等操作,所以,實際上落盤的存儲不只這么少,這個細節屬于存儲高可用的范疇,就不深究了),
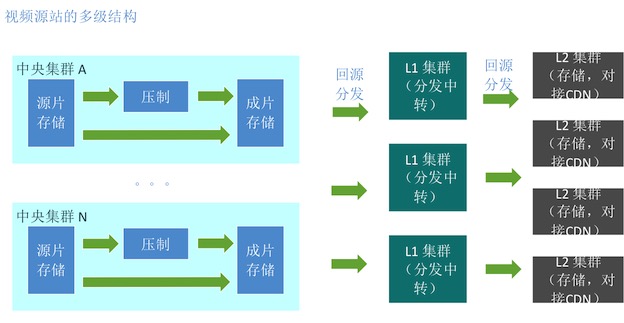
為了存儲在不同機房,唯一的一份數據同時發到多個CDN,源站內部需要使用多級緩存的結構。
? ?
?
在視頻源站內部的多級緩存之間,也就是多個機房之間的分發,叫做內部分發;
視頻源站(L2集群)到CDN接入點間的分發,叫做外部分發。一般L2集群對接CDN接入點,在與CDN聯調對接時,就會選好優質線路,甚至在一個運營商的機房。
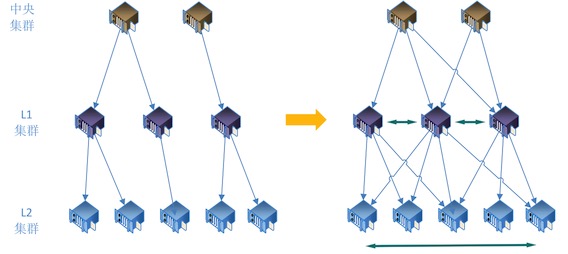
所以,我們介紹的重點還是,如何把視頻文件從N個成片存儲集群,通過K個L1集群,分發到M個L2集群中。
點播視頻源站分發過程中,存在的問題
- 點播視頻從中央集群向L1,L2集群(機房)分發時,采用樹狀分發(這個樹的建立,會根據經驗或者網絡本身特性),每個中央節點到不同的L1機房線路質量差距很大,不同的L1機房到L2機房質量也差異很大
- 分發過程走的是互聯網線路(專線太貴),互聯網線路的穩定性不可預期,有時網絡抖動,會造成分發失敗,甚至挖斷光纜導致某條干網不可用的事故也經常出現,某條線路或者某個機房的問題,可能會造成區域性的不可用
- 不同集群(機房)在規劃和建設時,服務器(計算、存儲、IO)能力、出入口帶寬不一樣,不同集群向下分發時對應的節點數也不一致,會出現不同集群間的負載差異較大的情況,俗稱忙的忙死閑的閑死,忙的節點,很可能成為瓶頸
??
點播視頻源站分發鏈路優化的意義
如何解決上面說的問題呢,我們自然的會想到,如果每個文件的分發過程,都能自動選擇一個***秀的鏈路,而不是根據那個配置死的回源樹,那么分發的過程將會帶來這些優勢:
- 更加高效和穩定
- 避免區域性的故障
- 不同集群(機房)的負載更加合理和平均
? ?
?
二, 節點間數據分發質量的評估
為何先評估兩個服務器節點間的分發質量
前面提到了優化的辦法是選擇好的分發鏈路,那么,到底怎樣分發鏈路才是一個好的鏈路呢?我們先來看以下事實:
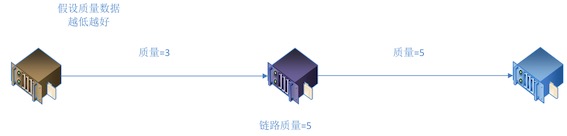
- 鏈路是由數據通過的服務器節點構成的
- 鏈路中,相鄰的服務器節點傳輸質量的最差值,決定這條分發鏈路的質量上限
? ?
?
所以,我們首先研究兩個服務器節點間傳輸質量的情況
兩個服務器節點間傳輸質量的評估
那么,用什么的來評估兩個服務器節點間的傳輸質量呢,我們自然希望有一個量化的數據,一個簡單的想法就是“文件下載耗時”。
影響兩個服務器節點間的傳輸質量(下載耗時)的因素有這些:
- 文件大小
- 服務器之間網絡線路的情況,包括數據延遲、丟包率、躍點數等等
- 發送服務器(接收服務器)的當前負載,包括CPU負載,內存用量,IO負載,當前帶寬,存儲用量
- 當前時間
我們接下來會簡單分析,這些因素會對下載有什么影響
文件大小:文件越大,下載越慢,耗時越長
服務器之間網絡線路的情況:兩個服務器之間的網絡情況,具體有這些指標
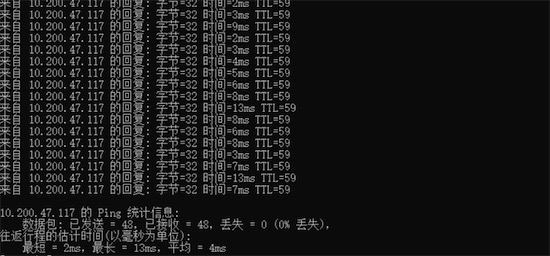
- 延遲:下圖中的ping指令,可以測試出兩個服務器間的延遲信息,對于數據傳輸來說,延遲越小越好
- MTU(Maximum Transmission Unit):是指一種通信協議的某一層上面所能通過的***數據包大小(以字節為單位)。***傳輸單元這個參數通常與通信接口有關(網絡接口卡、串口等),如下方圖中所示,傳輸3000字節,如果mtu設置成1500,需要打成兩個包,而當mtu設置為1492,則需要打成3個包,傳輸3個包當然要比2個耗時更多。
- 丟包率:下圖中的ping指令,測試出當前丟包為0個,在網絡出現問題時,這個數據可能不為0,視頻下載基于HTTP,底層是TCP協議,丟包后要重傳,丟包率越低會越好
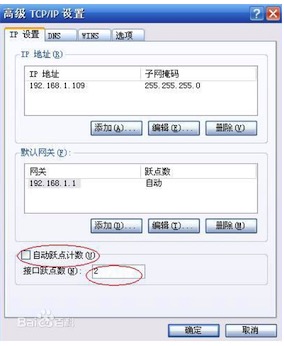
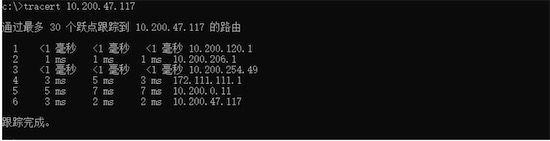
- 躍點數:躍點數代表兩個服務器間通信時經過的路由設備數目,數據通過路由器時,路由器中會有數據包隊列,隊列過滿,數據有被丟棄的風險;路由器在計算數據包下一跳的時候,也會有一定的耗時;
- 服務器的***帶寬:服務器***帶寬,當然是越大越好(當然成本也越高),例如家里裝寬帶,500M的肯定比100M的好(也更貴)
?
 ?
??
 ?
?
發送服務器(接收服務器)的當前負載情況
- CPU負載:CPU負載在不大的時候,對下載影響不大,當CPU負載超過一定值時,會嚴重影響下載的效率
- 內存用量:內存用量在不高的時候,對下載影響不大,當內存用量過一定值時,會嚴重影響下載的效率
- IO負載:IO負載在不大的時候,對下載影響不大,當IO負載超過一定值時,會嚴重影響下載的效率
- 當前帶寬使用情況:當前帶寬在不接近***帶寬的時候,對下載影響不大,當它接近***帶寬時,數據包傳輸阻塞,會嚴重影響下載的效率
?? ??
??
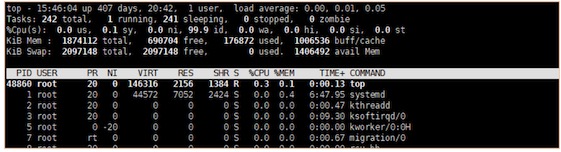
圖中為top指令看到的當前機器負載
當前時間:
以上提到的數據,都是隨著時間抖動的,例如說帶寬數據,視頻網站早上看的人少,晚上看的人多,工作日看的人和周末又不一致,而遇到一些節假日,又有新的特點,整體互聯網的使用趨勢是向上的,所以從一個長期時間來看,帶寬數據應該是波動向上的。
這里要提一個問題,正是由于相同尺寸、相同鏈路的下載速度,在不同時間點的表現差異巨大,才需要引入一個動態的預估機制。
例如,一個文件2G大小,我們在開始下載前,覺得鏈路A是***的,但是實際上下載了300M后,鏈路的A的質量已經不好了,這是鏈路B可能反倒更好,我們想要達到的目的是,計算出下載完2G大小文件的綜合耗時***是哪條。
建立兩個節點間數據傳輸質量模型的設想
度量兩個節點間的分發質量,我們可以用一個數值,下載時長(Download Time,縮寫為DT)來表示,這個數據受到很多具體的、隨時間呈現一定規律的因素(變量)影響,那么我們可以有一個美好的設想:用一個模型,或者說是一個函數,來描述這些因素與DT間的關系,后續新的文件下載時,使用這個模型,輸入當前這些變量,預測文件下載的耗時。
假設函數如下:
DT = Func(file_size,current_time,defer,cpu_load,mem_load,io_load, …….)
我們知道一個文件大小為100M,當前時間點已知,節點間這些變量已知,我們可以根據這個函數算出時長來。
三, 機器學習算法的設計和實現
機器學習的引入
前面提出了建立一個模型(函數)的設想,來預測DT,這個模型如何建立呢?
我們先看數學上是怎么做的,在數學范疇里,對于已知一組自變量、應變量數據,反過來求函數的過程,叫做擬合
二維空間里,一個自變量,一個應變量,就是簡單的曲線擬合,
三維空間了,兩個自變量,一個應變量,就是曲面擬合,
N維空間里, N-1個自變量,1個應變量,也能擬合,
這些具體的算法在數學書里都有,最小二乘法什么的,感興趣的同學可以自行查看。
而在計算機科學范圍內,AI研究的先驅者,提出了利用神經網絡做機器學習的辦法,來處理這個問題。
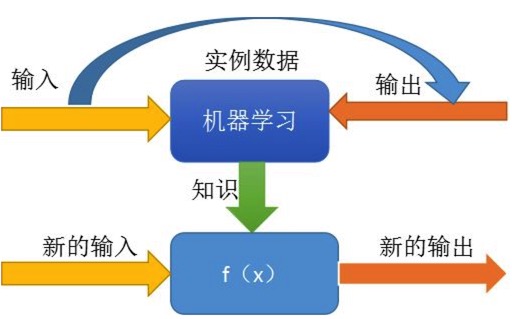
機器學習是什么呢,現在網上有很多解釋,我們這里簡單來說明下
? ?
?
我們給機器(計算機上的程序)已知的輸入、輸出,讓它去找規律出來(知識發現),然后我們讓它根據找到的規律,用新的輸入算出新的輸出來,并對這個輸出結果做評價,如果合適就正向鼓勵,如果結果不合適,就告訴機器這樣不對,讓它重新找規律。
其實這個過程在模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。
機器學習的本質就是讓機器根據已有的數據,去分析出一個模型來表示隱藏在這些數據背后的規律(函數)。
如何實現這個找規律的過程呢?
我們先說數學上是如何建立函數的(如何做擬合),過程如下:
- 選取擬合函數(冪函數,指數函數,對數函數,三角函數等)
- 設定參數
- 比較誤差,調節參數
- 迭代
? ?
?
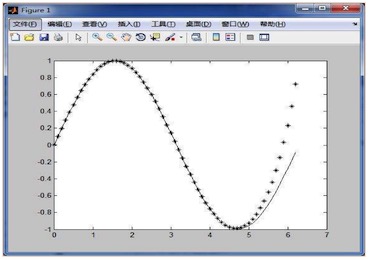
對于圖中這一系列點,我們***感覺這些點的排布是符合正弦函數的,那么我們使用三角函數中的正弦函數去擬合它,并且設定函數的周期、振幅、相位等等參數,你和后,發現在x > 5后,還是有一定誤差的,這就需要去判斷誤差是可接受,如果不可,則需要重新做擬合。
? ?
?
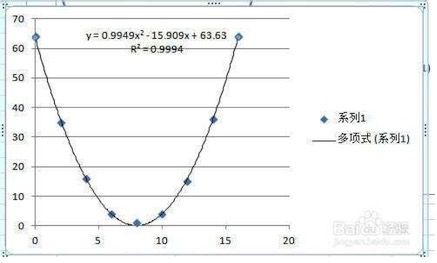
對于上圖中的這些點做擬合,我們發現這些點的分布好像是個拋物線,那么根據我們中學的數學知識,拋物線是冪函數中二次冪函數的圖像,所以使用二次冪函數做擬合,最終得到一個方程來。
和數學領域一樣,AI領域里,輸入通過一個模型(函數)變成輸出,這個模型(函數)靠什么確定呢,靠猜!
猜不是問題,問題是如何猜的更準?
AI的先驅提出了模擬人類大腦神經元的思路,來處理如何猜模型的問題
神經網絡和人工神經網絡
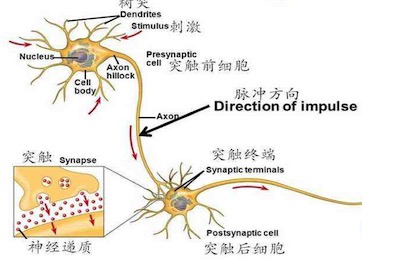
大腦神經元是這個樣子:
? ?
?
大腦的神經網絡是這個樣子:
大腦神經元的特點是這樣,每個神經元只負責處理一定的輸入,做成一定的輸出,給下級節點,***組合起來,形成人腦中的神經網絡,這也就是動物思考的過程了。
人工神經網絡就是,人為的構造出一些處理節點(模擬腦神經元),每個節點有個函數,處理幾個輸入,生成若干輸出,每個節點與其它節點組合,綜合成一個模型(函數)。
?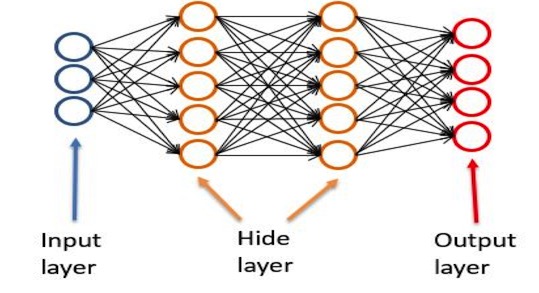 ?
?
從左到右分別是輸出層, 隱藏層,輸出層。
輸入層負責接受輸入,輸出層負責輸出結果,隱藏層負責中間的計算過程。
隱藏層的每一個節點,就是一個處理函數。隱藏層的結構,也就是層數,節點數,還是每個節點的函數將決定整個神經網絡的處理結果。
Tensorflow的介紹
Tensorflow的介紹網上非常多(可以搜索查看),按照本文的上下文,我們簡單的介紹如下:
? ?
?
Tensorflow是一個通過神經網絡實現深度學習的平臺,我們給它輸入,輸出,約定一些(猜測模型)的規則,讓他去幫我們猜測具體模型。
使用TensorFlow的步驟可以簡單的概括為,收集訓練數據 訓練 比較 迭代 …..
訓練數據的收集
我們來介紹如何為建立兩個節點間的傳輸質量的模型收集訓練數據。
前面介紹過,數據分為輸入和輸出數據。
輸入數據為4類:
- 下載的文件大小-可直接記錄
- 當前時間-使用unix timestamp
- 網絡情況的統計-來自一些測速工具
- 發送(接收)服務器的負載情況-來自zabbix的記錄
輸出數據為下載一個文件的時間記錄,需要做離散化處理(后續介紹離散化原因)
Zabbix 的介紹:
- 基于WEB界面的提供分布式系統監視以及網絡監視功能的企業級的開源解決方案
- zabbix能監視各種網絡參數,保證服務器系統的安全運營;并提供靈活的通知機制以讓系統管理員快速定位/解決存在的各種問題
- zabbix server與可選組件zabbix agent
- 支持Linux,Solaris,HP-UX,AIX,Free BSD,Open BSD,OS X
Zabbix的anget部署在傳輸節點上,定期收集機器的負載和帶寬使用數據, 并向中心(zabbix server)匯總。
下圖是zabbix對于當前帶寬的統計情況:
? ?
?
下圖是3個月的帶寬負載:
? ?
?
下圖是3個月的cpu負載:
? ?
?
使用IPERF工具收集網絡數據
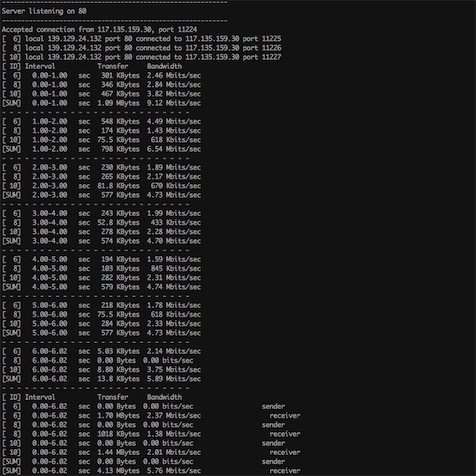
IPERF工具可以收集以下數據:
- 當前服務器之間的傳輸帶寬
- 丟包率
- MSS、MTU
- 支持tcp/udp
下圖為iperf的使用截圖:
? ?
?
Ping工具收集延遲,測試節點連通性:
? ?
?
Tractroute工具收集節點間躍點數信息
? ?
?
(windows cmd中,命令為tracert)
訓練的準備
數據的組合與格式化:
將網絡數據,負載數據,文件大小,時間,格式化后組合成一條json。
將下載耗時數據分段后做離散化處理,這里解釋下,為何要對結果(輸出)做離散化,TensorFlow擅長做分類處理的學習,當分類的結果集合是個連續集的時候,可能的結果就有無窮多個,這將大大加大訓練的難度,降低訓練的速度。把結果離散化處理好,接近時間的時間處理成一個值,超過一定閾值的時間都化為一個值,這樣結果的區間有限,將大大降低訓練難度。
訓練模型參數的預設定:
我們前面說到數學范疇的擬合時,會先根據自己經(xia)驗(meng),從冪函數、三角函數,指數函數,對數函數中選取一種或是多種組合起來作為擬合的基礎。
對于神經網絡來說,我們也不能一上來啥都不管,就讓它亂猜,而是要根據已(geng)知(shi)經(xia)驗(meng),設定模型和參數。
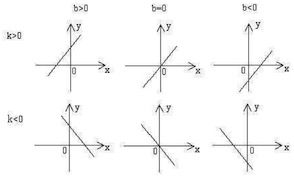
前面提到,每個節點都是一個函數,那么,我們選什么函數呢,我們先考慮最簡單的情況,線性函數,我們用一堆線性函數組合起來成為一個網絡,這個網絡描述的模型,肯定還是個線性模型,它不足以描述世界上大部分的規律。
下圖是常見的線性函數:
? ?
?
那么我們考慮,把每個函數再做非線性化,就是在一個線性函數外,再套一個非線性函數(稱作激活函數),再組合成一個網絡,這個網絡描述的模型,基本上能覆蓋世界上大部分的規律了(別問我原因,我也不懂。。。)。
下圖是常使用的一些非線性函數:
?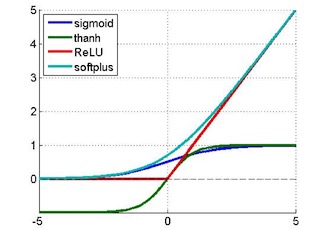 ?
?
構成的網絡:
?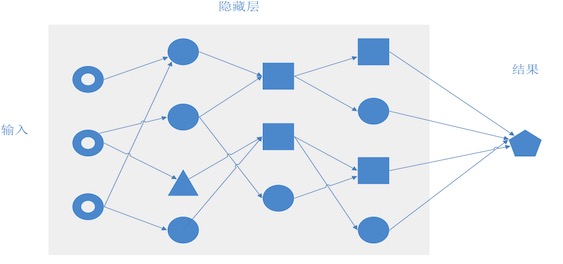 ?
?
每個節點上的函數類型,我們先猜了一個,那么,網絡的結構呢,到底用幾層,每層幾個節點,這個事情,在做不同領域的神經網絡時,選擇真是千差萬別。
我們在評估節點間傳輸質量時,先根據(拍)經(腦)驗(門)設置層數為15,每層50個節點,節點函數也按照基本經驗進行設置。
下面的參數將影響TensorFlow的訓練結果:
- 初始學習率
- 學習率衰減率
- 隱藏層節點數量
- 迭代輪數
- 正則化系數
- 滑動平均衰減率
- 批訓練數量
- 線性函數、激活函數設置
其中,隱藏層節點數,迭代輪數,批訓練數量,線性函數、激活函數設置將影響較大,如何設置,前面已經提及,而剩余參數影響稍小,有興趣的同學可以自行搜索。
TensorFlow的處理流程
單個節點處理如下圖:
?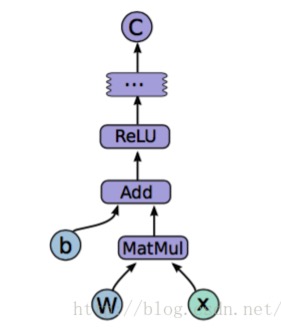 ?
?
一個節點做了 ReLU(Wx+b)再與其它節點組合,最終生成輸出結果。
整體上分為以下幾步:
- 數據輸入
- 訓練
- 訓練結果審查
- 調節參數
- 重新訓練
- 訓練結果審查
- ……
- 訓練結果滿意
通過Tensorflow的結果,計算***傳輸路徑
當我們經過大量的訓練和調優后,得到了每兩個(需要的)服務器節點間的訓練模型,通過這個模型,輸入當前文件大小、時間、服務器和網絡的測試狀態,就可以算出一個預期的下載傳輸耗時。
? ?
?
我們把節點間兩兩計算的結果,代入到網絡拓撲圖中
?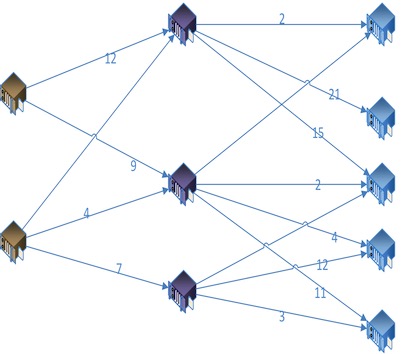 ?
?
使用最短路徑算法,計算***(和次優)的傳輸路徑
這里是的算法為Dijkstra算法 (翻譯為 迪杰斯特拉算法)
?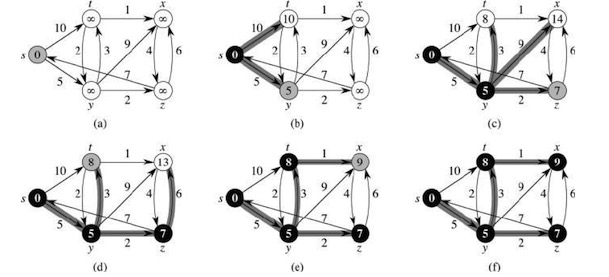 ?
?
這是一個非常經典的最短路徑算法,就不占篇幅介紹了,有興趣的同學可以自行搜索。
整體處理流程回顧
?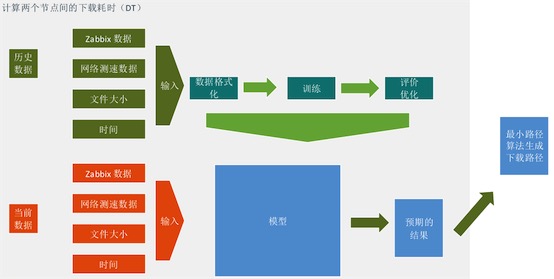 ?
?
- 首先,收集訓練數據,使用zabbix數據、網絡測速數據、文件大小、當前時間信息為輸入,下載耗時為輸出,進行模型訓練,并對模型做持續的優化。
- 使用當前的zabbix數據、網絡測速數據、文件大小、當前時間信息為輸入,使用訓練好的模型做計算,得到預期的下載結果。
- 相關節點,兩兩計算預期結果,構成一個傳輸網絡,使用Dijkstra算法計算傳輸網絡內的最小路徑。
四, 未來展望
使用***流算法進行文件分片下載
目前的算法針對的是整體文件進行下載,實際上,流媒體服務器早已經實現了文件虛擬切割,http協議也有range請求,在此基礎上,把一個文件分割,通過多條鏈路同時下載,將提升下載速度,也將進一步提升網絡利用率。
具體可參考EK 算法,Dinic算法等。
使用最小費用***流對***流算法進行改進
考慮到每個機房,每條線路建設時,成本不一樣。
在***流有多組解時,給每條邊在附上一個單位費用的量,在滿足***流時的計算最小費用是多少,這樣對于成本使用將更精細,機房如需擴容也將做成指導。
在直播領域的應用
目前點播源站內部分發,進行模型訓練采用的輸入數據是上述數據,結果是下載耗時;對于直播來說,可以使用和直播相關的數據進行組合與訓練,結果為QoS,生成新的模型,對直播回源的內部調度預測***鏈路。
【作者介紹】
曾小偉,PP云技術副總監,圖像編解碼、高性能計算出身,輔修AI(NLP方向),12年以上流媒體服務端開發及架構設計經驗。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】