













人工智能圖像生成技術:短短5年內如何飛速發展?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
在過去幾年內,該機構還制造出一只可以通過自學還原魔方的機器手、一組超人電子競技算法、一種合理生成人類音樂的算法,以及多種可以玩游戲和使用工具學習復雜策略的算法。
近期,OpenAI發布了DALL-E,一個可以根據書面文本生成圖像的人工智能系統。例如,系統響應提詞“一個牛油果形狀的皮包。一個仿造牛油果樣式的皮包”,可以產生幾十次關于牛油果皮包的迭代。
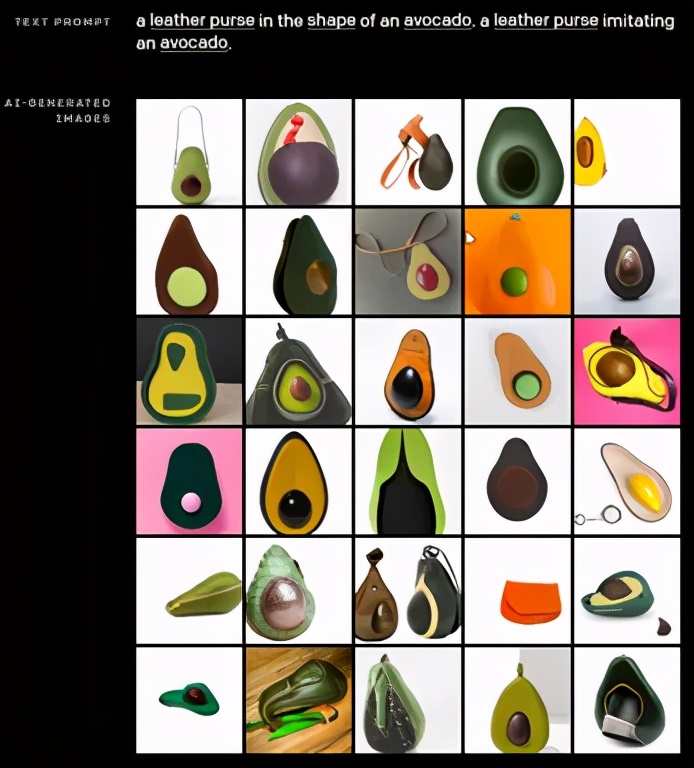
圖源: OpenAI
該公司還未將DALL-E(Salvador Dalí和WALL-E名字的結合)公之于眾,甚至也尚未邀請其特定開發者群體來試用新軟件,但據其網站上的案例所示,該系統可以創建極其逼真且細致的圖像。
DALL-E精通各種藝術風格,包括插圖和風景畫。它還可以生成文本,在建筑物上進行標記,并將同一場景的素描線條和全彩圖像分離。研究人員把這種影響深遠的能力稱為泛化能力,即算法并非專門針對某一種任務或藝術風格。
OpenAI將算法的神通廣大歸功于兩個主要因素:其一,算法非常龐大。它使用了120億個參數,數量大到令人驚異。而這些參數可以被認為是算法轉動的旋鈕,用來調整其理解想法的方式。這120億個參數在分析圖像和文本時能夠分辨出諸多特異性,令人難以置信。
然后,這些圖像和文本材料被輸入到算法中,并且被翻譯成更易于算法理解的標記或文本。OpenAI解釋說,一個標記就像英語字母表中的一個字母——它們代表碎片化的概念,這一方式更易于機器計算,并且以它們以算法的語言模式排列。
這一機器字母表包含16384個文本標記和8192個圖像標記。這種將人類可讀文本自動轉換為機器可讀文本的方法稱為“轉換器模型”。一個字幕或帶有文本的圖像轉換為算法,最多會被翻譯成256個標記,而圖像最多能被翻譯成1024個標記。這使得算法能夠為相對較少的文本輸入匹配到更復雜的圖像。
之后,算法將通過分析成對的圖像和字幕不斷進化。通過表面上數百萬次迭代,它能夠將文本片段與圖像的特定特征聯系起來。但OpenAI還未公布這一數據集的容量或其包含的圖像內容。
該公司并不是第一個嘗試從文本中生成圖像的公司,甚至這也不是OpenAI的首次嘗試。這只是此類算法的最新版本,似乎也是最可行的一個版本。雖然該公司還未發表過任何文章來描述該系統,但這一算法的創造者確實曾在其博客上引用了DALL-E的前置任務。
通過對算法的沿襲進行考察,我們可以追蹤到這項技術實際上的發展程度。
2016
OpenAI引用了這篇由密歇根大學和馬普研究所撰寫的論文,為當前文本到圖像生成的研究注入了活力。
這篇論文使用了生成式對抗網絡(generative adversarial networks generative,簡稱GANs)來生成圖像。GANs的功能是將兩種算法相互對立:一種生成圖像,另一種將不夠真實的圖像駁回。

圖源: Reed et. al
2017
一年后,羅格斯大學、里海大學和中國香港大學的研究人員采取了另一種 GAN 方法——“堆疊”成對的算法。第一對算法列出場景的形狀和顏色,然后第二對算法細化細節。
圖源: Zhang et. al
2019
2019年,另一支主要隸屬于微軟的團隊嘗試了不同的“兩步走”方法。第一步是生成場景中對象所在位置的示意圖,第二步是使用該示意圖作為向導生成構成目標圖片所需的對象。

圖源: Li et. al
2020
去年年底,美國人工智能艾倫研究所發表了一項使用轉換器模型的研究,與OpenAI使用的轉換器模型相同。艾倫研究所的研究人員沒有追求模型的規模,而是依賴于“隱蔽”。
在《麻省理工學院科技評論》上有一篇文章詳細解釋了這一概念,Karen Hao將“隱蔽”描述為“把不同的單詞隱藏在句子中,讓模型填補空白”。算法掌握這些直觀性跳躍后,研究者發現生成的圖像質量得到顯著提升。

圖源: Cho et al.
回溯過去這些研究案例,我們可以發現OpenAI的DALL-E確實是一項飛躍。從模糊不清的斑點開始,最先進的技術已發展到能夠生成牛油果形狀的椅子,OneZero專欄作家歐文·威廉姆斯表示他真的愿意購買這樣的椅子。
這些進步足以讓一代家具設計師、圖庫藝術家以及其他網絡藝術家感到害怕。
















