













圖解 Raft 共識算法:如何選舉領導者?
Raft 是通過以領導者為準實現各個節點日志一致的一種共識算法,被越來越多的分布式系統框架應用,比如 Etcd、Consul 等等,Seata 未來也會引用 Raft,即將發布的 Kafka 2.8 也引入了 Raft,在 Raft 的基礎上做了一些改版,在 Kafka 2.8 中稱作 KRaft。
由此看來,Raft 是目前大部分分布式系統的首選共識算法,學習 Raft 將有助于你在分布式領域中如魚得水。
本文主要內容為我對 Raft 選舉領導者的一些理解總結。
成員
按照我的理解,Raft 是一種強領導者模型,即一切以領導者為準,實現一系列的共識和各個節點日志一致性的一種共識算法。
Raft 一共有三種成員身份,分別是:領導者(Leader)、跟隨者(Follower)、候選人(Candidate)。
跟隨者:在 Raft 中只有領導者才會與客戶端交互,因此在不發生選舉時,跟隨者僅默默地處理來自領導者發送的消息,充當數據冗余的作用,當領導者心跳超時,跟隨者就會主動推薦自己當選候選人。
候選人:成為候選人之后,就會向其他節點發送請求投票消息,以獲取其他節點的投票,如果獲得了大多數選票,則當選領導者。
領導者:數據一切以領導者為準,它也是與客戶端交互的唯一角色,處理請求,管理日志的復制,同時還不斷地發送心跳信息給跟隨者,不斷刷新跟隨者節點的超時時間,以防跟隨者發起新的選舉。
選舉過程
下面我以一個剛初始化的 Raft 集群為例:
1、初始狀態
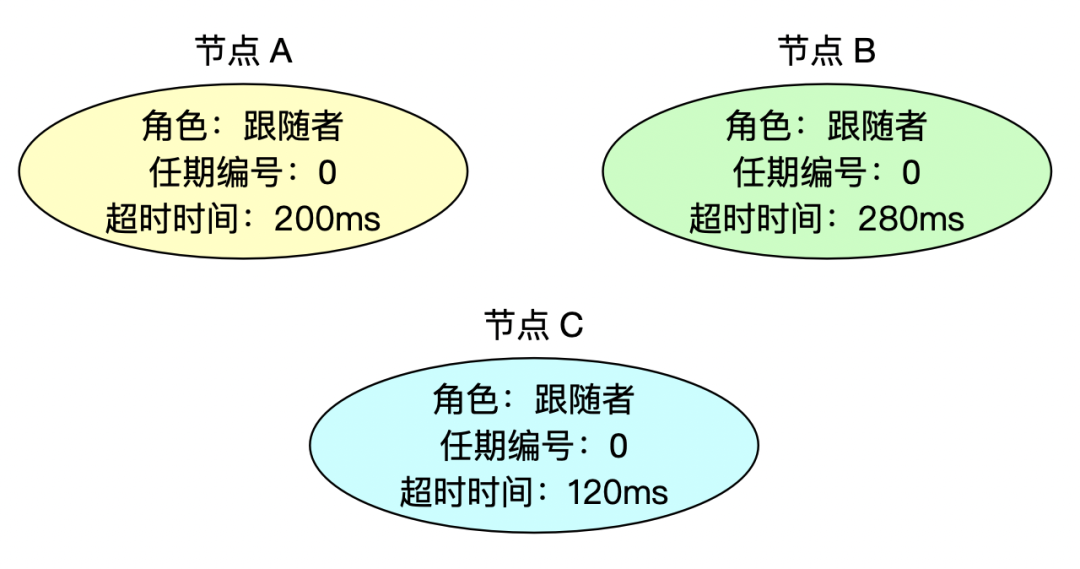
Raft 每個節點初始化后的心跳超時時間都是隨機的,如上所示,節點 C 的超時時間最短(120ms),任期編號都為 0,角色都是跟隨者。
2、請求投票
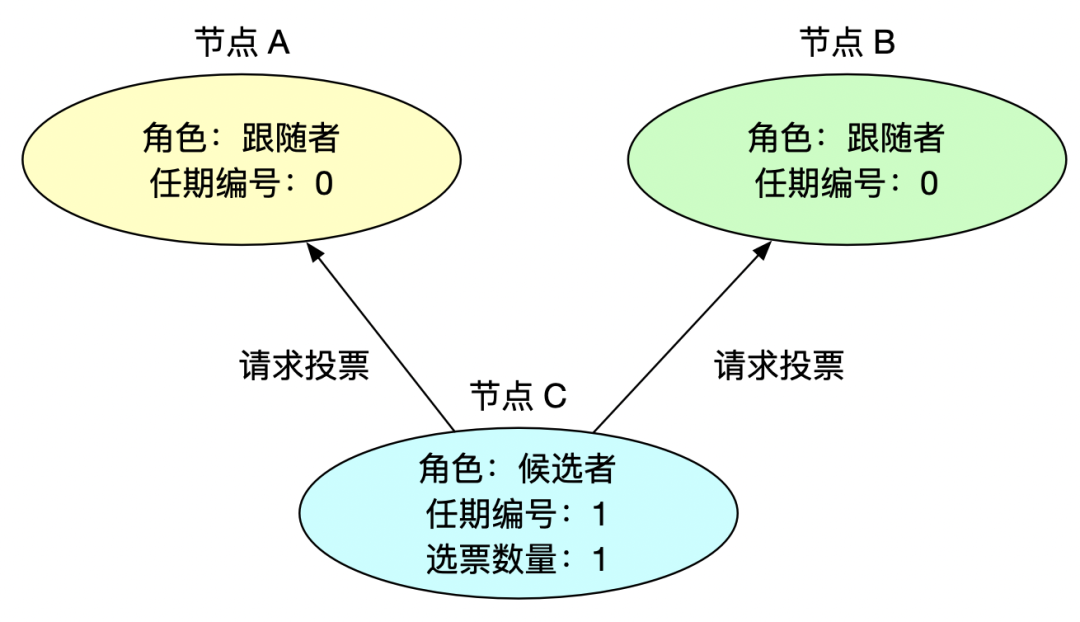
此時沒有一個節點是領導者,節點等待心跳超時后,會推薦自己為候選人,向集群其他節點發起請求投票信息,此時任期編號 +1,自薦會獲得自己的一票選票。
3、跟隨者投票
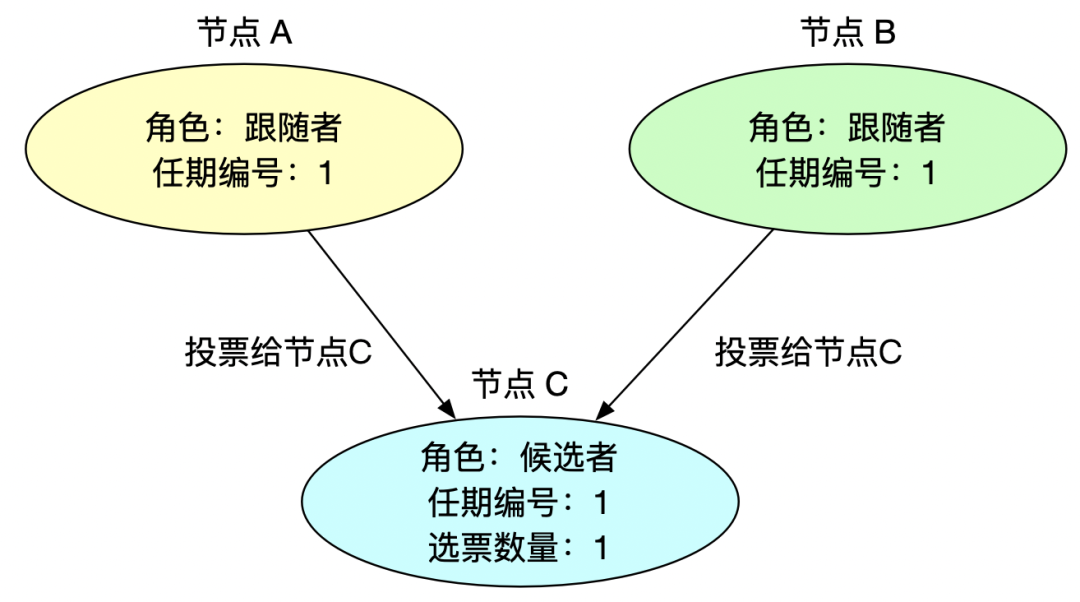
跟隨者收到請求投票信息后,如果該候選人符合投票要求后,則將自己寶貴(因為每個任期內跟隨者只能投給先來的候選人一票,后面來的候選人則不能在投票給它了)的一票投給該候選人,同時更新任期編號。
4、當選領導者
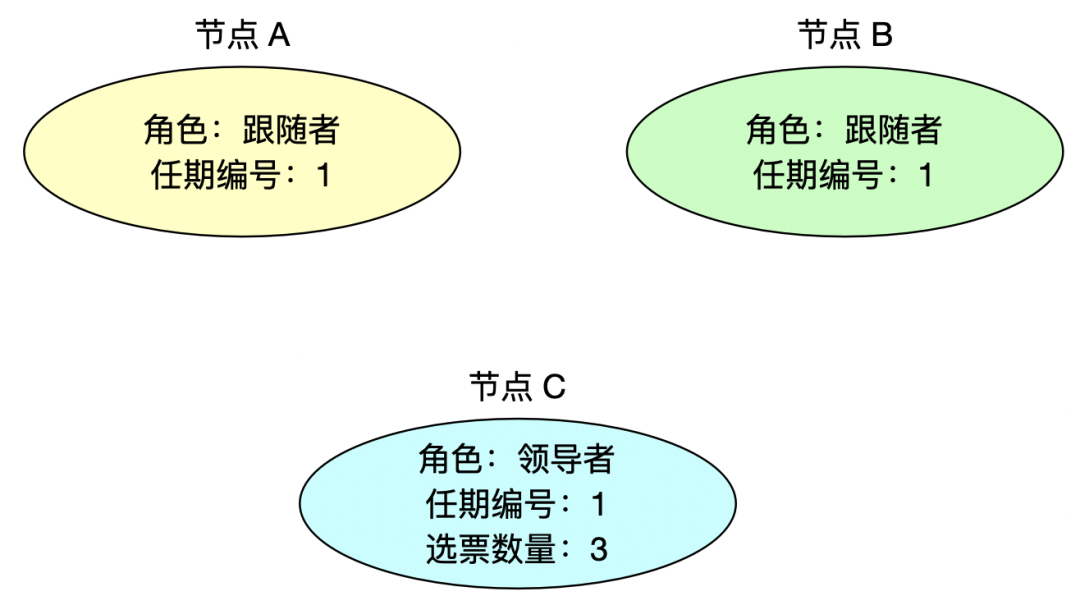
當節點 C 贏得大多數選票后,它會成為本次任期的領導者。
5、領導者與跟隨者保持心跳
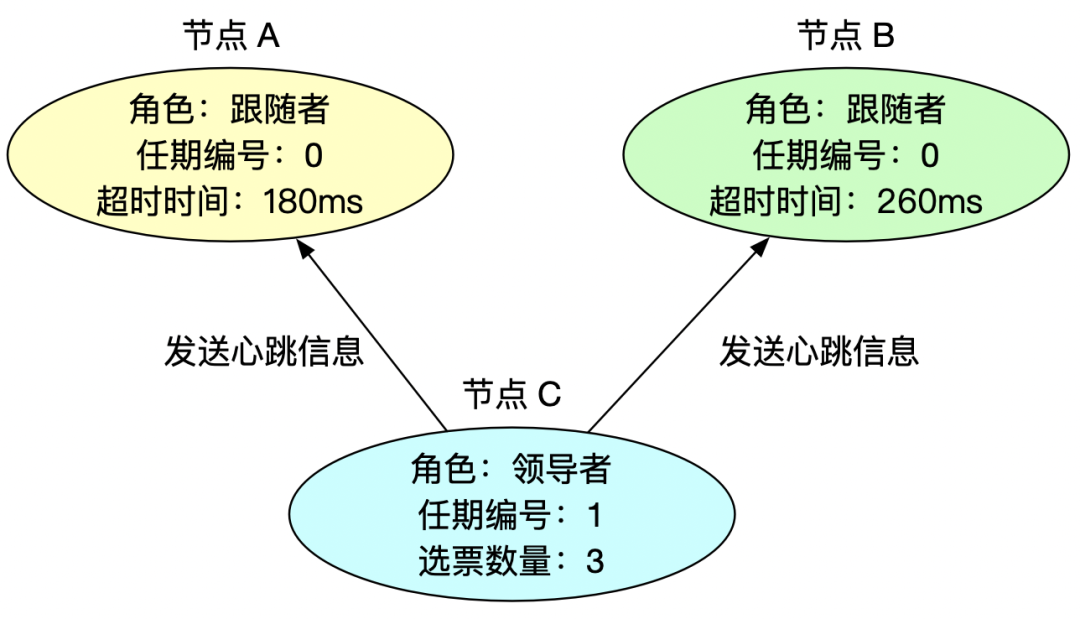
領導者周期性發送心跳消息給其他節點,告知自己是領導者,同時刷新跟隨者的超時時間,防止跟隨者發起新的領導者選舉。
關于任期
從以上的選舉過程看,我們知道在 Raft 中的選舉中是有任期機制的,顧名思義,每一任領導者,都有它專屬的任期,當領導者更換后,任期也會增加,Raft 中的任期還要注意以下個細節:
如果某個節點,發現自己的任期編號比其他節點小,則會將自己的任期編號更新比自己更大的值;
從上面的選舉過程看出,每次推薦自己成為候選人,都會得到自身的那一票;
如果候選人或者領導者發現自己的任期編號比其它節點好要小,則會立即更新自己為跟隨者,這點很重要,按照我的理解,這個機制能夠解決同一時間內有多個領導者的情況,比如領導者 A 掛了之后,集群其他節點會選舉出一個新的領導者 B,在節點 B 恢復之后,會接收來自新領導者的心跳消息,此時節點 A 會立即恢復成跟隨者狀態;
如果某個節點接收到比自己任期號小的請求,則會拒絕這個請求。
關于隨機超時
跟隨者如果沒有在某個時間內接收到來自領導者的心跳,則會發起新一輪的領導者選舉,試想一下,如果全部跟隨者都在同一時間發起領導者選舉,這是一種怎樣的場景?會不會造成同一時間內造成選舉混亂呢?如果同時發起選舉,會不會因為選票被瓜分導致選舉失敗的原因?
如果你想自己親自調試并觀摩 Raft 選舉過程,你可以訪問以下網址:
https://raft.github.io/
本文轉載自微信公眾號「后端進階」,可以通過以下二維碼關注。轉載本文請聯系后端進階公眾號。





















