圖解 Raft 共識算法:如何復制日志?
Raft 日志格式
在 Raft 算法中,需要實現分布式一致性的數據被稱作日志,我們 Java 后端絕大部分人談到日志,一般會聯想到項目通過 log4j 等日志框架輸出的信息,而 Raft 算法中的數據提交記錄,他們會按照時間順序進行追加,Raft 也是嚴格按照時間順序并已一定的格式寫入日志文件中:
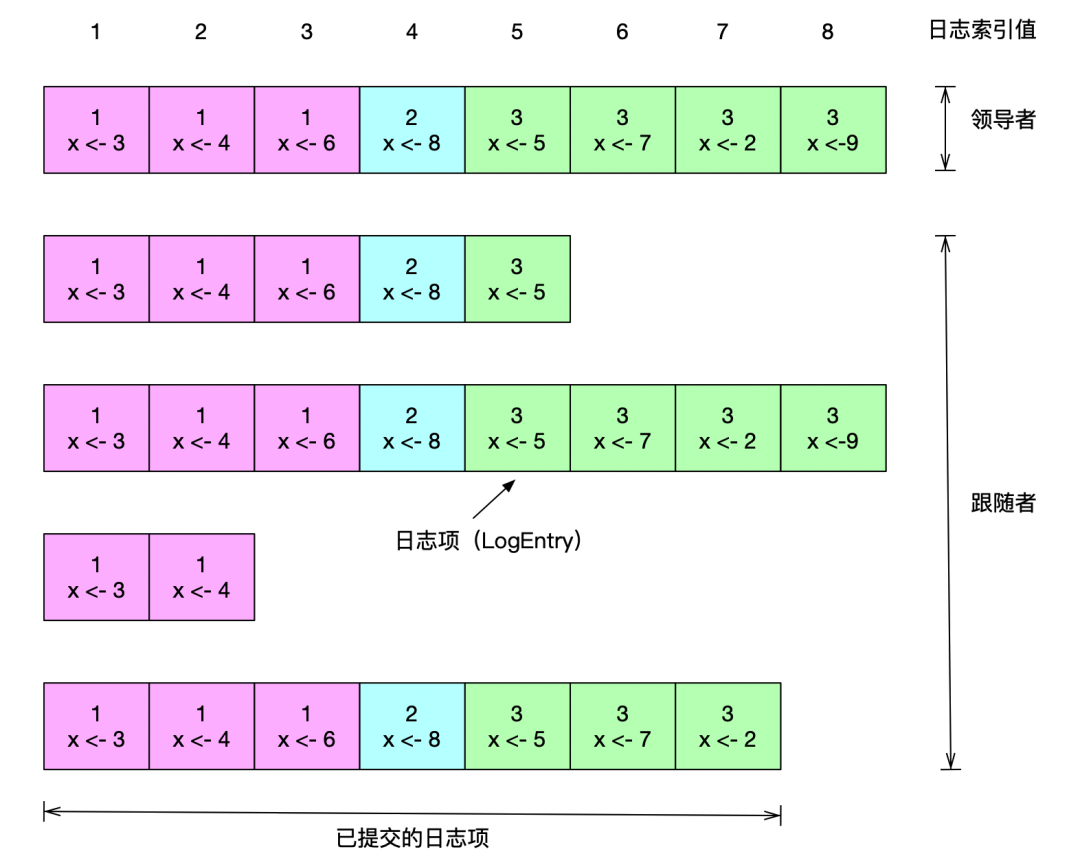
如上圖所示,Raft 的日志以日志項(LogEntry)的形式來組織,每個日志項包含一條命令、任期信息、日志項在日志中的位置信息(索引值 LogIndex)。
- 指令:由客戶端請求發送的執行指令,有點繞口,我覺得理解成客戶端需要存儲的日志數據即可。
- 索引值:日志項在日志中的位置,需要注意索引值是一個連續并且單調遞增的整數。
- 任期編號:創建這條日志項的領導者的任期編號。
日志復制過程
Raft 的復制過程大致如下:
領導者接收到客戶端發來的請求,創建一個新的日志項,并將其追加到本地日志中,接著領導者通過追加條目 RPC 請求,將新的日志項復制到跟隨者的本地日志中,當領導者收到大多數跟隨者的成功響應之后,則將這條日志項應用到狀態機中,可以理解成該條日志寫成功了,最后領導者返回日志寫成功的消息響應客戶端,流程如下圖所示:
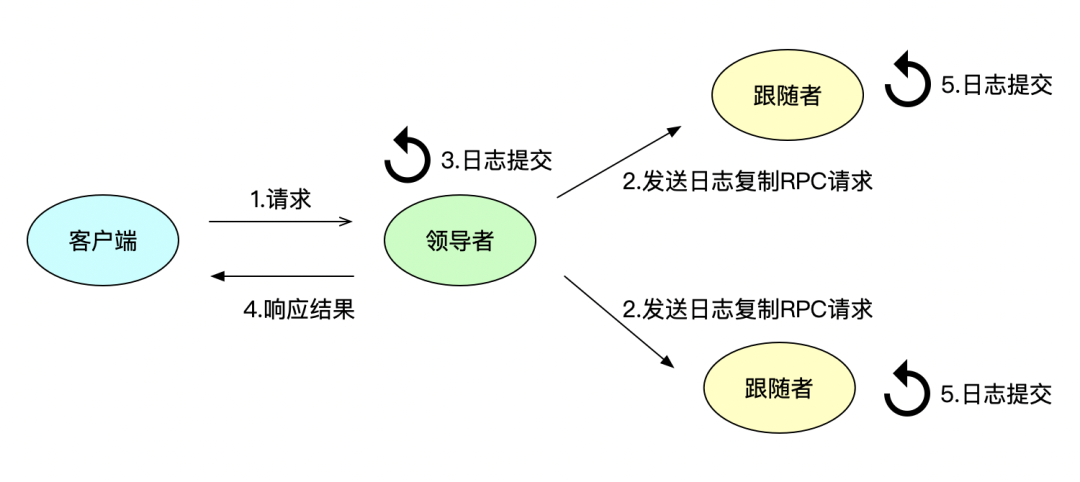
可以看出,Raft 的復制過程中,領導者接收到大多數跟隨者成功響應,并且將日志項應用到狀態機之后,不需要將結果響應給跟隨者,而是直接將成功消息響應給客戶端,這是一種優化方式,同時 Raft 會在下一次 RPC 追加日志請求中附加上本次的日志項信息。
以上僅僅只是一種沒有發生任何問題的復制過程,在這過程中難免會發生節點宕機等問題,在這種情況下,Raft 是如何處理的呢?
如何保證日志的一致性?
上面講到,在正常情況下,領導者的日志追加 RPC 請求響應都成功的情況下,領導人和跟隨者的日志保持一致性。然而在領導者突然宕機的情況下有可能會造成領導者與跟隨者日志不一致的情況,這種情況會隨著后續領導者一些列宕機的情況下加劇問題的嚴重:
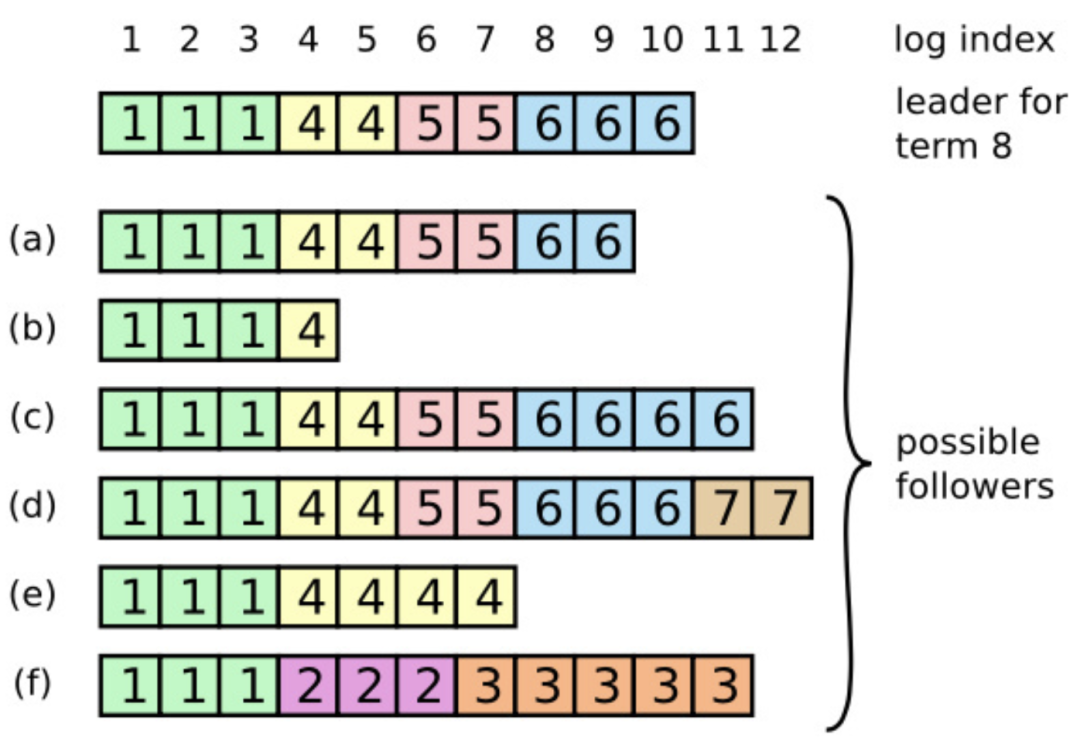
注:例子來源于 Raft 論文。
如上所示,當一個領導者成功當選時,跟隨者有可能是 a-f 的情況:
- a-b 表示跟隨者的日志項落后于當前領導者;
- c-d 表示跟隨者有些日志項沒有被提交;
- e-f 情況稍微有點復雜,以上兩種情況它們都存在。
下面我來還原上面圖所表示的情況是怎么發生的:
假設一開始 e 為領導者,在任期 2 時,f 被推選為領導者,寫入了若干日志項之后,在追加 RPC 請求中崩潰了,重啟后又被選舉為領導者(任期號 3),又在寫入了若干日志項之后奔潰了;e 此時又重新選舉為領導者(任期號為 4),成功復制了若干日志項,同時還有一部分沒有成功追加到大多數跟隨者又崩潰了,同時跟隨者 b 復制了一部分日志項之后崩潰了;假設 a 在任期 5 時被選舉為領導者,c 在任期 6 時被選舉為領導者,還未全部將本地日志復制到其他跟隨者之前又崩潰了,在任期 7 時 d 被選擇為領導者,寫入了若干日志項之后,在追加 RPC 請求中崩潰了,最后形成了上圖的情況。
面對以上的情況,Raft 是如何解決日志的一致性呢?
在 Raft 的日志機制中,為了簡化日志一致性的行為,有以下兩點非常重要的特性:
- 如果在不同的日志中的兩個條目擁有相同的索引和任期號,那么他們存儲了相同的指令。
- 如果在不同的日志中的兩個條目擁有相同的索引和任期號,那么他們之前的所有日志條目也全部相同。
第一個特性是因為 Raft 日志項在日志中不會改變,因此只要日志項只要是索引值和任期號相同,就可以認為他們是存儲了相同的指令數據信息。
第二個特性是因為領導者會通過強制覆蓋的方式讓跟隨者復制自己的日志來解決日志不一致的問題,領導者在追加 RPC 請求過程中會附帶需要復制的日志以及前一個日志項相關信息,如果跟隨者匹配不到包含相同索引位置和任期號的日志項,那么他就會拒絕接收新的日志條目,接著領導者會繼續遞減要復制的日志項索引值,直至找到相同索引和任期號的日志項,最后就直接覆蓋跟隨者之后的日志項。可認為兩個條目擁有相同的索引和任期號,那么他們之前的所有日志條目也全部相同。
因此,Raft 的日志追加大致可分為兩個步驟:
領導者找到跟隨者與自己相同的最大日志項,這意味著跟隨者之前的日志都與領導者的日志相同;
領導者強制覆蓋之后不一致的日志,實現日志的一致性。
下面我用一個例子充分表達 Raft 在日志復制過程中是如何進行日志強制覆蓋的。
假設有一個領導者和一個跟隨者,他們的日志項復制情況如下:
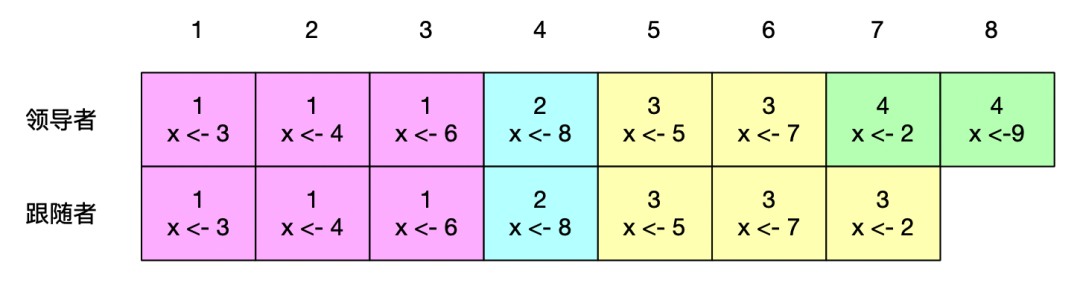
可以看出,跟隨者在任期號 3 時是領導者,在追加日志過程中崩潰了,重啟之后成為跟隨者,隨后新的領導者向其追加日志,此時他的任期號為 3 最后的一個日志項將被覆蓋。
先來看下 Raft 追加條目 RPC 的請求參數:
| 參數 | 描述 |
|---|---|
| term | 領導者的任期 |
| leaderId | 領導者ID 因此跟隨者可以對客戶端進行重定向(譯者注:跟隨者根據領導者id把客戶端的請求重定向到領導者,比如有時客戶端把請求發給了跟隨者而不是領導者) |
| prevLogIndex | 緊鄰新日志條目之前的那個日志條目的索引 |
| prevLogTerm | 緊鄰新日志條目之前的那個日志條目的任期 |
| entries[] | 需要被保存的日志條目(被當做心跳使用是 則日志條目內容為空;為了提高效率可能一次性發送多個) |
| leaderCommit | 領導者的已知已提交的最高的日志條目的索引 |
領導者追加并覆蓋跟隨者過程如下:
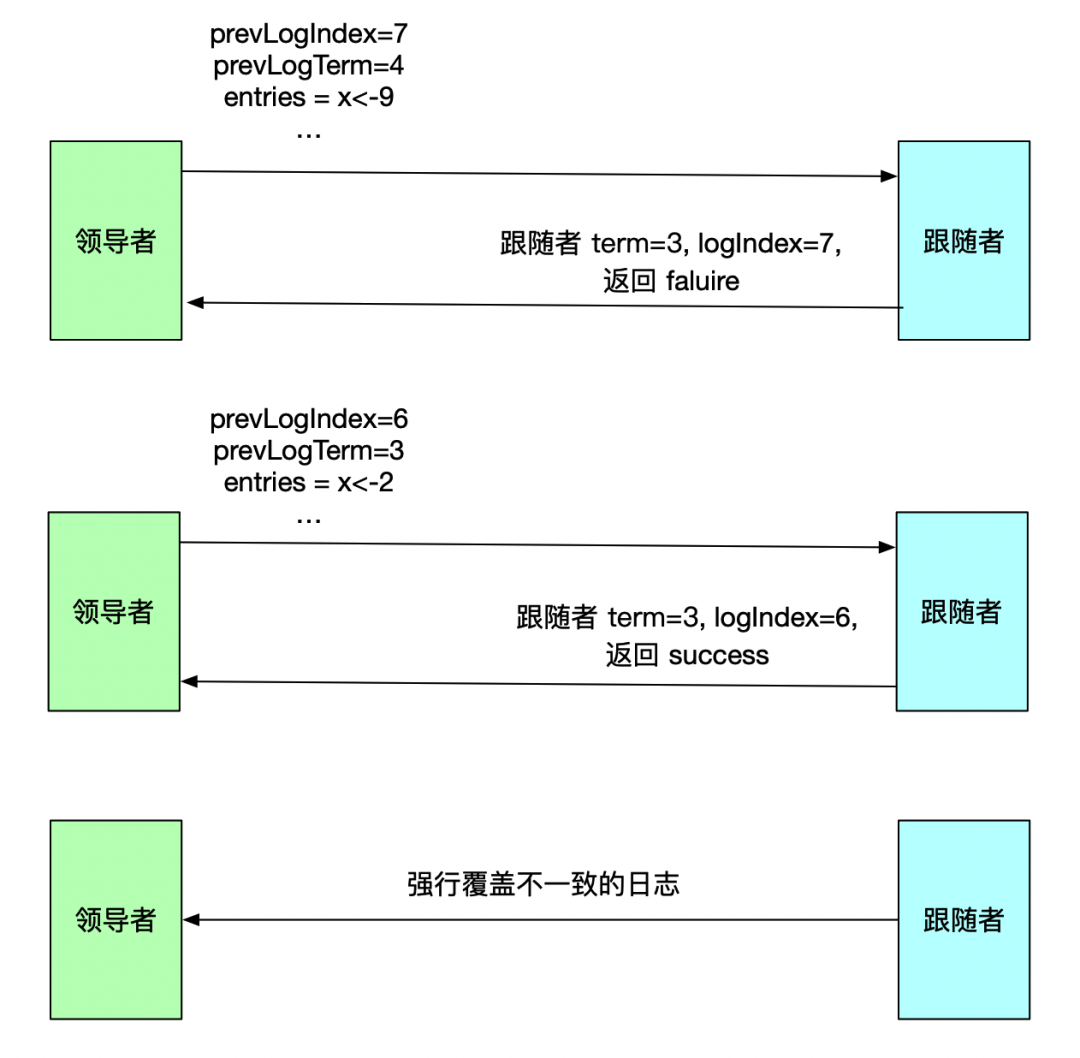
領導者通過日志追加 RPC 請求,將當前最新的要追加到跟隨者的日志項以及前一個它的 prevLogIndex=7、prevLogTerm=3 等信息發送跟跟隨者;
跟隨者判斷當前最新的日志的任期號與 prevLogTerm 不一致,拒絕追加;
領導者繼續遞減需要復制的日志項的索引值,此時 prevLogIndex=6、prevLogTerm=3;
跟隨者找到了 LogIndex=6、LogTerm=3 的日志項,跟隨者接受追加請求;
領導者接著會將跟隨者 LogIndex=6、LogTerm=3 的日志項之后的日志項進行追加并覆蓋。
本文轉載自微信公眾號「后端進階」,可以通過以下二維碼關注。轉載本文請聯系后端進階公眾號。