













MIT小哥聯合谷歌訓練7個多任務機器人,9600個任務成功率高達89%!
隨著任務數量的增加,使用當前計算方法來構建通用的日常機器人的成本變得過高,人們正在快速尋求一種解決辦法。我們都希望通用機器人可以執行一系列復雜的任務,例如清潔,維護和交付等等。
但是,即使使用脫機強化學習(RL )來訓練單個任務(例如清潔),也需要大量的工程設計、花費很長的時間,這看似是件不可能完成的事!
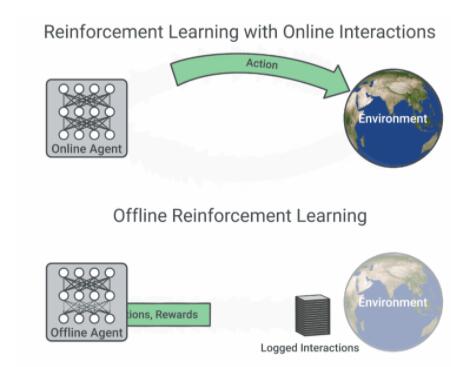
上圖為脫機和非脫機強化學習的演示動圖
MT-Opt+Actionable Model= 脫機強化學習
但是經過科學家們的不斷努力,機器人的發展遇到前所未有的機遇。
任職于google的幾位優秀的計算機科學家,率先研發出了處理大規模任務的新型機器人。
德米特里·卡拉什尼科夫(Dmitry Kalashnikov)是這項研究的第一作者,年紀輕輕的他于2009年創立了AI Digit公司,2013年加入google,擔任軟件工程師一職長達7年多。
杰克·瓦利(Jake Varley)作為第二作者,本科畢業于麻省理工大學(MIT)計算機科學專業,2013年順利成為哥倫比亞大學的博士生,一畢業就收到google拋來的橄欖枝,現在google任SWE一職已經3年了。
卡羅爾·豪斯曼(Karol Hausman)作為第三作者,是南加大計算機科學專業的博士生,也是2018年加入google,目前主要擔任google機器人控制和google大腦實驗室的科學家。
這項研究主要展示了機器人脫機強化學習(RL)的兩個新進展,即MT-Opt(一種用于自動數據收集和多任務RL訓練的系統)以及Actionable Models(可動模型),該模型利用獲取的數據實現脫機學習的目標。

MT-Opt引入了可擴展的數據收集機制,該機制在真實的機器人上可以收集超過800,000個任務,相比以往很多多任務脫機學習的成功應用,其平均性能比基線提高了約3倍。
更神奇的是,它還可以使機器人在不到1天的時間內對新任務進行適應,接著快速掌握新任務。
即使在沒有特定任務和獎勵的情況下該機器人也可以進行學習,這不僅極大地增加了機器人可以執行的任務數量,并可以更有效地學習下游任務。
所以為了大規模地收集多樣化的任務數據,他們創建了一個可擴展且直觀的多任務檢測器來指定任務,目的是為了要收集最終平衡結果的數據集。
具體步驟如下:
為了訓練該系統,科學家們收集了9600個機器人數據(來自七個機器人連續57天的數據收集),并采用監督學習(supervised learning)的方式來訓練多任務,甚至允許用戶快速定義新任務及其獎勵的設置。
首先當收集數據時,需要對各種現實因素進行監察和定期更新。(例如不同的光照條件,多變的背景環境以及機器人靈活的狀態)。
其次,通過使用較為簡單的任務解決方案,有效地引導機器人學習更復雜的任務,這樣在針對不同任務時,可以同時使用多個機器人同時操作。
一旦形成針對性訓練,每個任務的數據量和成功情節數便會隨著時間增長。
為了進一步提高性能,科學家們還重點放在某些表現欠佳的任務上進行調試和訓練,逐一突破!
成功率高達89%!
盡管這種數據收集策略可以有效地收集大量數據,但任務之間的成功率和數據量是不平衡的。
所以為了解決這個問題,他們命令機器人對每個成功或失敗的任務進行標記。這一步驟之后再將已經達到均衡的任務發送到多任務RL訓練管道。
好消息是,對于具有多數據的通用任務,MT-Opt的成功率是89%(QT-Opt的成功率是88%),罕見任務MT-Opt的平均成功率是50%。
使用可操作模型(Actionable Model)可以使機器人系統地學習大量的指示技能,例如物體抓握,容器放置和物體重新布置。
除此以外,該模型還能訓練數據中看不到的物體和視覺目標,新的機器人具有「學習世界」的能力!
小結:
MT-Opt模型和可操作模型的結果都表明,真實的機器人可以學習許多不同的任務,并且這些模型有效地分攤了學習技能的成本。
這是邁向通用機器人學習系統很重要的一步,該系統可以進一步擴展到現實生活中,執行許多對人類有幫助的服務。
如果感興趣的讀者,可以具體參考這兩篇論文:“ MT-Opt:大規模的連續多任務機器人強化學習”和“可行的模型:機器人技術的無監督離線強化學習”,網站上提供了很多有關MT-Opt的更多信息、視頻和可行的模型。

























