字節提出 Vi-PRoM 視覺預訓練方案,機器人操作成功率更高,操作效果更好了
近年來,利用大規模真實世界數據進行的視覺預訓練取得了顯著進展,在基于像素觀察的機器人學習中展現出巨大的潛力。但這些工作在預訓練的數據、方法和模型方面有所不同。因此哪些類型的數據、預訓練方法和模型可以更好地輔助機器人操控仍然是一個懸而未決的問題。
基于此,ByteDance Research 團隊的研究者從預訓練數據集、模型架構和訓練方法三個基本角度全面研究了視覺預訓練策略對機器人操作任務的影響,提供了一些有利于機器人學習的重要實驗結果。此外,他們提出了一種名為 Vi-PRoM 的機器人操作視覺預訓練方案,它結合了自監督學習和監督學習。其中前者采用對比學習從大規模未標記的數據中獲取潛在模式,而后者旨在學習視覺語義和時序動態變化。在各種仿真環境和真實機器人中進行的大量機器人操作實驗證明了該方案的優越性。

- 論文地址:https://arxiv.org/pdf/2308.03620.pdf
- 項目地址:https://explore-pretrain-robot.github.io/
基準研究

預訓練數據
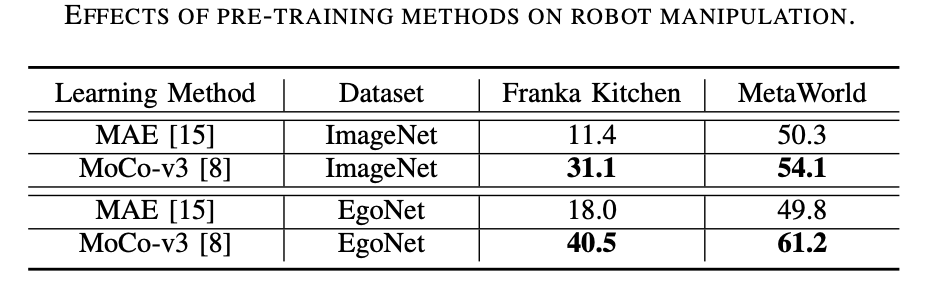
EgoNet 比 ImageNet 更強大。使用對比學習方法在不同的數據集(即 ImageNet 和 EgoNet)上預訓練視覺編碼器,并觀察它們在機器人操作任務中的表現。從下表 1 中可以看到,在 EgoNet 上預訓練的模型在機器人操作任務上取得了更好的性能。顯然,機器人在操作任務方面更傾向于視頻中包含的交互知識和時序關系。此外,EgoNet 中以自我為中心的自然圖像具有更多關于世界的全局背景,這意味著可以學習更豐富的視覺特征。

模型結構
ResNet-50 表現更好。從下表 2 中可以看出 ResNet-50 和 ResNet-101 在機器人操作任務上的表現優于 ResNet-34。此外,隨著模型從 ResNet-50 增加到 ResNet-101,性能并沒有提高。

預訓練方法
預訓練方法首選對比學習。如下表 3 所示,MoCo-v3 在 ImageNet 和 EgoNet 數據集上均優于 MAE,這證明了對比學習與掩模圖像建模相比更有效。此外,通過對比學習獲得的視覺語義對于機器人操作來說比通過掩模圖像建模學習的結構信息更重要。
算法介紹
基于上述探索,該工作提出了針對機器人操作的視覺預訓練方案 (Vi-PRoM),該方案在 EgoNet 數據集上預訓練 ResNet-50 來提取機器人操作的全面視覺表示。具體來說,他們首先采用對比學習以自我監督的方式從 EgoNet 數據集中獲取人與物體的交互模式。然后提出了兩個額外的學習目標,即視覺語義預測和時序動態預測,以進一步豐富編碼器的表示。下圖顯示了提出的 Vi-PRoM 的基本流程。值得注意的是,該工作不需要手動標注標簽來學習視覺語義和時序動態。

實驗結果
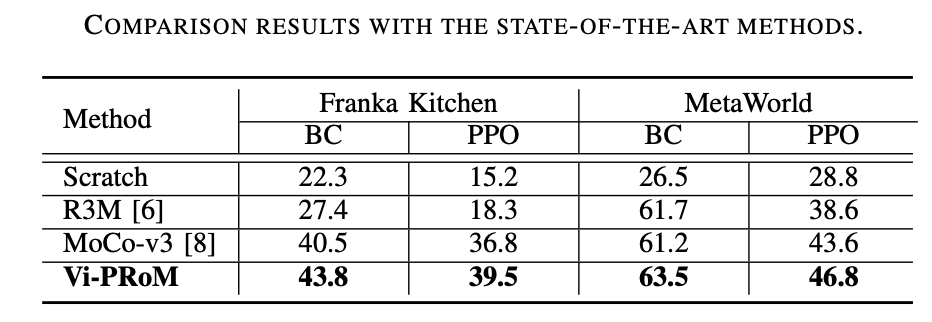
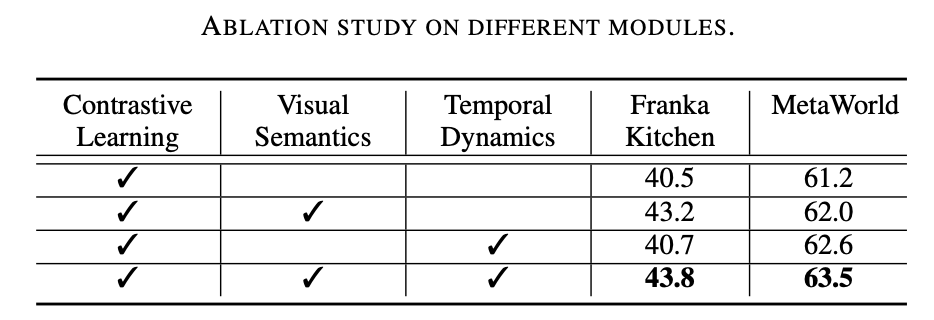
該研究工作在兩種仿真環境 (Franka Kitchen 和 MetaWorld) 上進行了廣泛的實驗。實驗結果表明所提出的預訓練方案在機器人操作上優于以前最先進的方法。消融實驗結果如下表所示,可以證明視覺語義學習和時序動態學習對于機器人操作的重要性。此外,當兩個學習目標都不存在時,Vi-PRoM 的成功率會大大下降,證明了視覺語義學習和時序動態學習之間協作的有效性。
該工作還研究了 Vi-PRoM 的可擴展性。如下左圖所示,在 Franka Kitchen 和 MetaWorld 模擬環境中,Vi-PRoM 的成功率隨著演示數據規模的增加而穩步提高。在更大規模的專家演示數據集上進行訓練后,Vi-PRoM 模型顯示了其在機器人操作任務上的可擴展性。


得益于 Vi-PRoM 強大的視覺表征能力,真實機器人可以成功打開抽屜和柜門。
Franka Kitchen 上的實驗結果可以看出,Vi-PRoM 在五個任務上都比 R3M 具有更高的成功率和更高的動作完成度。
R3M:





Vi-PRoM:





在 MetaWorld 上,由于 Vi-PRoM 的視覺表示學習了良好的語義和動態特征,它可以更好地用于動作預測,因此相比 R3M,Vi-PRoM 需要更少的步驟來完成操作。
R3M:

Vi-PRoM: